Agentic automation has changed the game for everyone, but when tasks become too complex, interdependent, and/or require deep SME context the limitations become abundantly clear.
Teams are experiencing these blocks when pushing the boundaries of agent building by expanding single agent workflows to a multi agent systems.
The workaround?
Engineering context strategically into a multi agent system to manage complexity at scale.
This blog explores multi-agent systems, context engineering frameworks, and practical best practices for teams ready to build working multi-agent solutions that actually work.
Quick overview
Multi-agent systems are a powerful step beyond single-agent workflows, but they bring complexity. By layering in context engineering best practices, teams can scale coordination, reduce failures, and unlock production-grade performance with multi agent systems.
This guide gives you the practical and actionable knowledge to confidently build multi-agent workflows that work.
Why this matters
Most AI builders hit a ceiling with single agents once tasks become too complex. Multi-agent systems are emerging as the solution to break this ceiling. When engineered correctly with the right context they turn complex fragmentation into collaboration.
For organizations serious about deploying agents in production, mastering these strategies is the difference between experiments that break and AI that makes it to production.
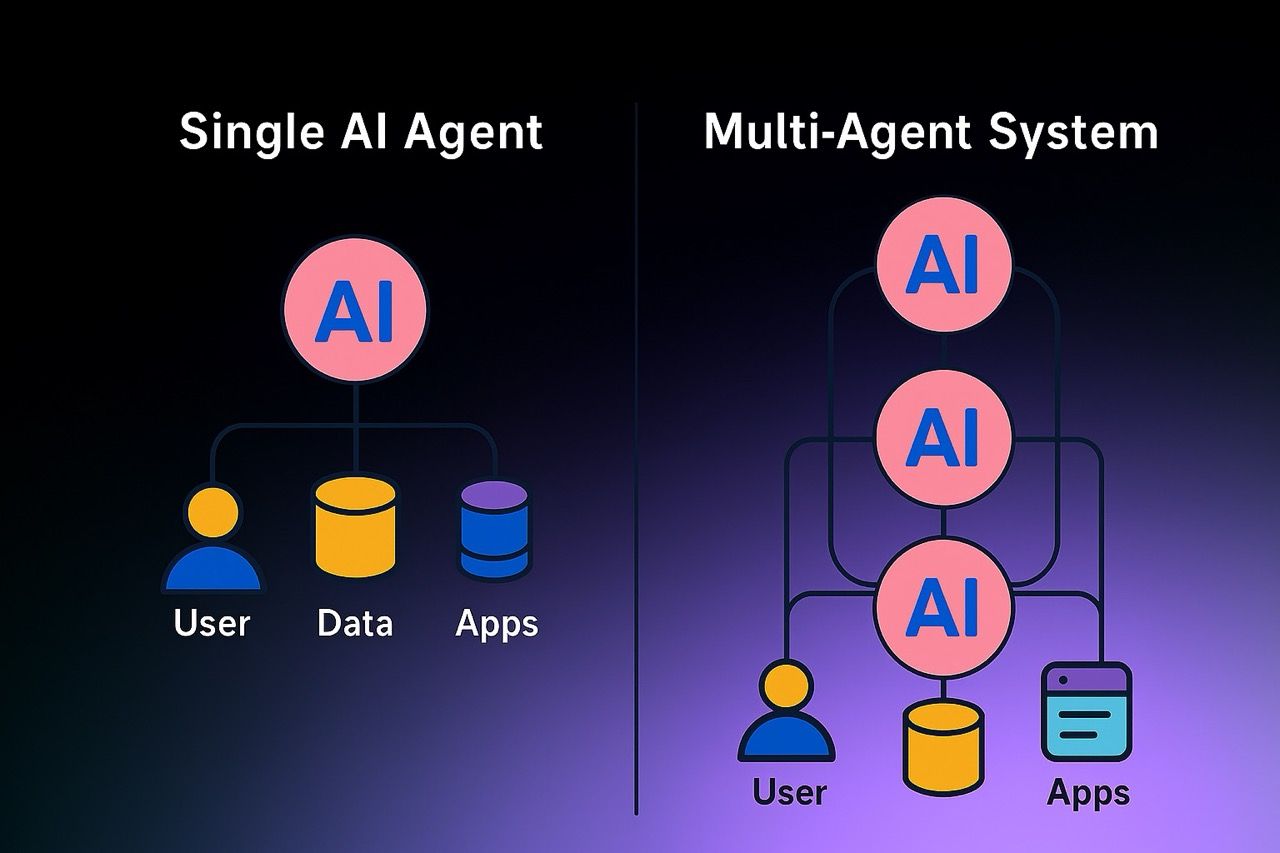
What is a multi agent system?
Multi agent systems coordinate multiple specialized agents to solve complex problems collaboratively.
Each agent has a specific role and context window, working in parallel toward a shared output. Like human teams, they rely on clear role definition, scoped responsibilities, and synchronized outputs to succeed.
Anthropic showcased a successful multi-agent research system that was organized with an Opus 4 lead agent managing coordinated Sonnet 4 specialized subagents that worked on tasks in parallel.
This system outperformed a Opus 4 single-agent by 90.2% on internal research evaluations, with token usage explaining 80% of performance variance in their BrowseComp analysis [1] .
Though Anthropic achieved phenomenal results using multi-agent systems, it isn’t fully clear whether this approach will work better for teams using single agents for their AI needs.
Are multi agent systems right for you?
Though powerful, not every task calls for multiple AI agents. In fact, multi-agent systems can introduce complexity, coordination risk, and significantly higher token usage.
Think about a task like generating automating product descriptions based on a few attributes (e.g. name, category, and key features).
This is a straightforward task, that fits within a single context window, where the agent can handle prompt interpretation, structured output formatting, and language generation without needing help from specialized sub-agents.
Use a single agent when:
Your task is linear or involves unified reasoning. Real-time responses and low latency are important. The problem fits within a single context window.
Now, think about a workflow for deep research where the goal is to compare economic policies across countries using live data, expert analysis, and statistical indicators.
This kind of task is too complex for one agent to handle well on its own, so using Anthropic’s approach as an example, there would need to be a lead agent responsible for overseeing the process and coordinating multiple specialized sub-agents.
It looks like this:
One sub-agent would use Browse tools to pull recent economic news and government reports. Another would query structured data sources (e.g. GDP, inflation, interest rates) and calculate key metrics using Calculator tools. A third sub-agent could summarize expert commentary or academic literature. The lead agent (Opus 4 in Anthropic’s case) would then synthesize all outputs, ensuring consistency, resolving contradictions, and generating a well-structured comparative analysis.
With each agent operates with scoped instructions and context, the system runs i n parallel, sustains accuracy, and avoids overloading any single agent with too much responsibility or information.
Use a multi agent system when:
Tasks can be naturally split into subproblems. Agents can specialize (e.g. research, planning, analysis). Work can be parallelized or decomposed across roles. You require external memory or broad tool orchestration.
If those conditions aren’t met, a well-structured single-agent system may be more reliable and easier to maintain [2] .
A good rule of thumb is to start with a single-agent and scale to multi-agent architectures only after proving value and identifying a clear need for specialization or parallelism. Learn more about this approach by exploring our guide on building agentic workflows that scale on Vellum.
Common orchestrations
Multi-agent systems can be structured in different ways depending on how agents interact, delegate, and share state, ultimately shaping how the system coordinates work, manages failures, and distributes reasoning.
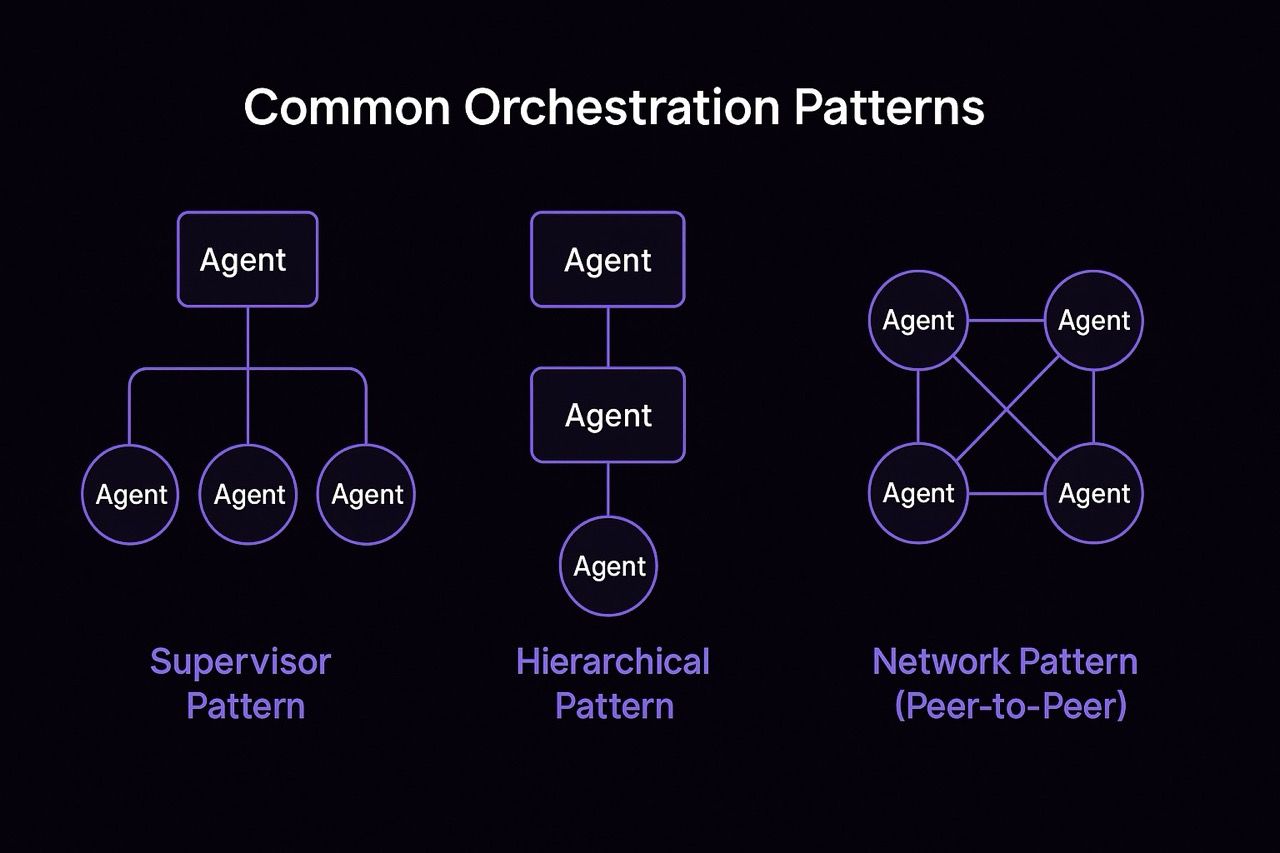
Here are the three most common patterns:
Supervisor Pattern A central agent acts as a manager that delegates tasks to specialized sub-agents and integrating their outputs. This mirrors a traditional team structure and is useful for workflows that need tight oversight.
Hierarchical Pattern Agents are arranged in a chain, where the output of one becomes the input for the next. This works well for sequential workflows like planning → research → summarization, where each stage builds on the previous.
- Network Pattern (Peer-to-Peer) Agents operate independently but share access to a shared state or memory layer. Coordination happens through updates to that state, making this ideal for collaborative or parallelized problem-solving.
Choosing the right orchestration pattern depends on your task structure, agent specialization, and need for control versus autonomy.
Managing complexity with context engineering
Cognition found that the main issue with multi agent systems is that they are highly failure prone when agents work from conflicting assumptions or incomplete information, specifically noting that subagents often take actions based on conflicting assumptions that weren't established upfront [3] .
This means failure will generally always boil down to missing context within the system. How to maintain this necessary context?
Context engineering . The defining principle is as follows:
Build agents that factor in the collective knowledge and decisions of the entire system before acting.
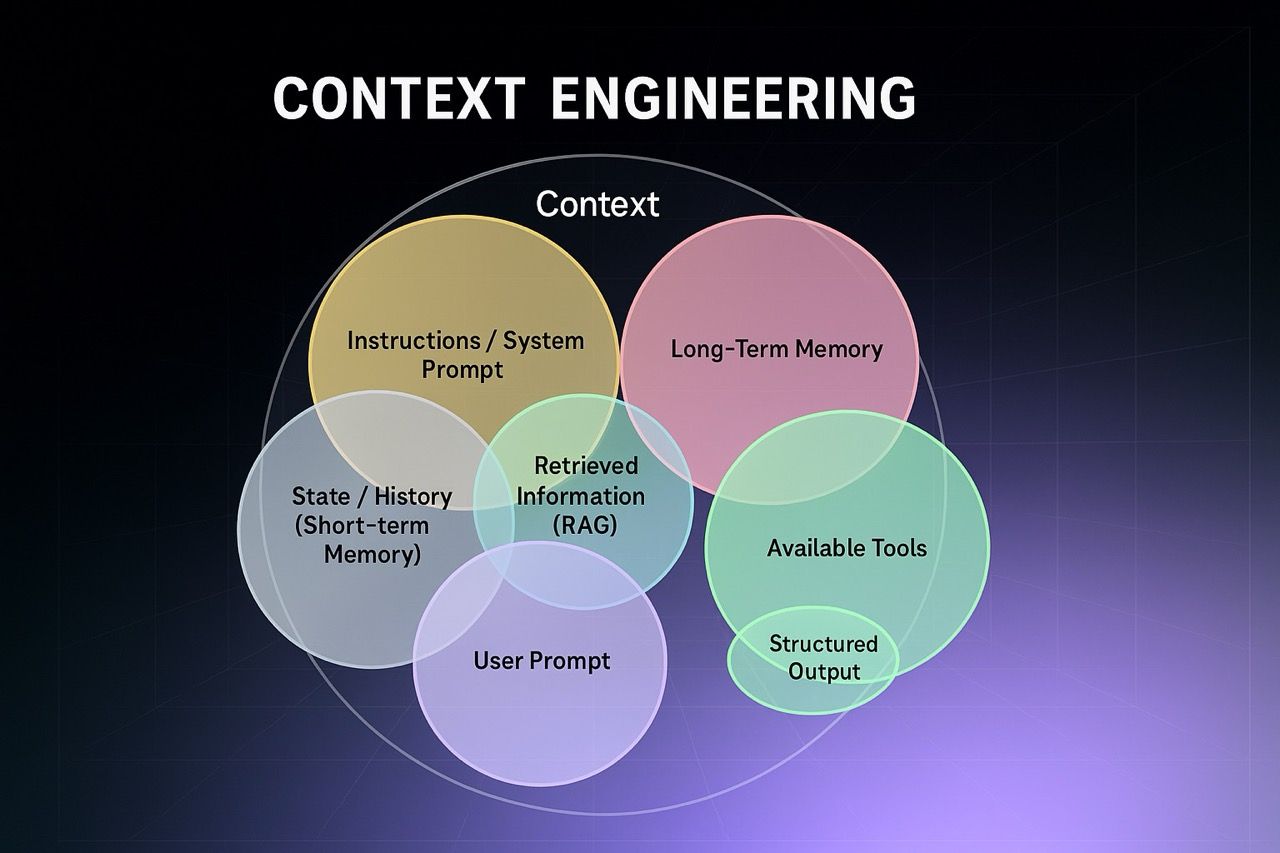
It is quickly evolving as a practice of designing, managing, and maintaining the input context used by agents in multi-agent systems. It keeps operations in scope so agents can make informed decisions that guarantee successful outputs.
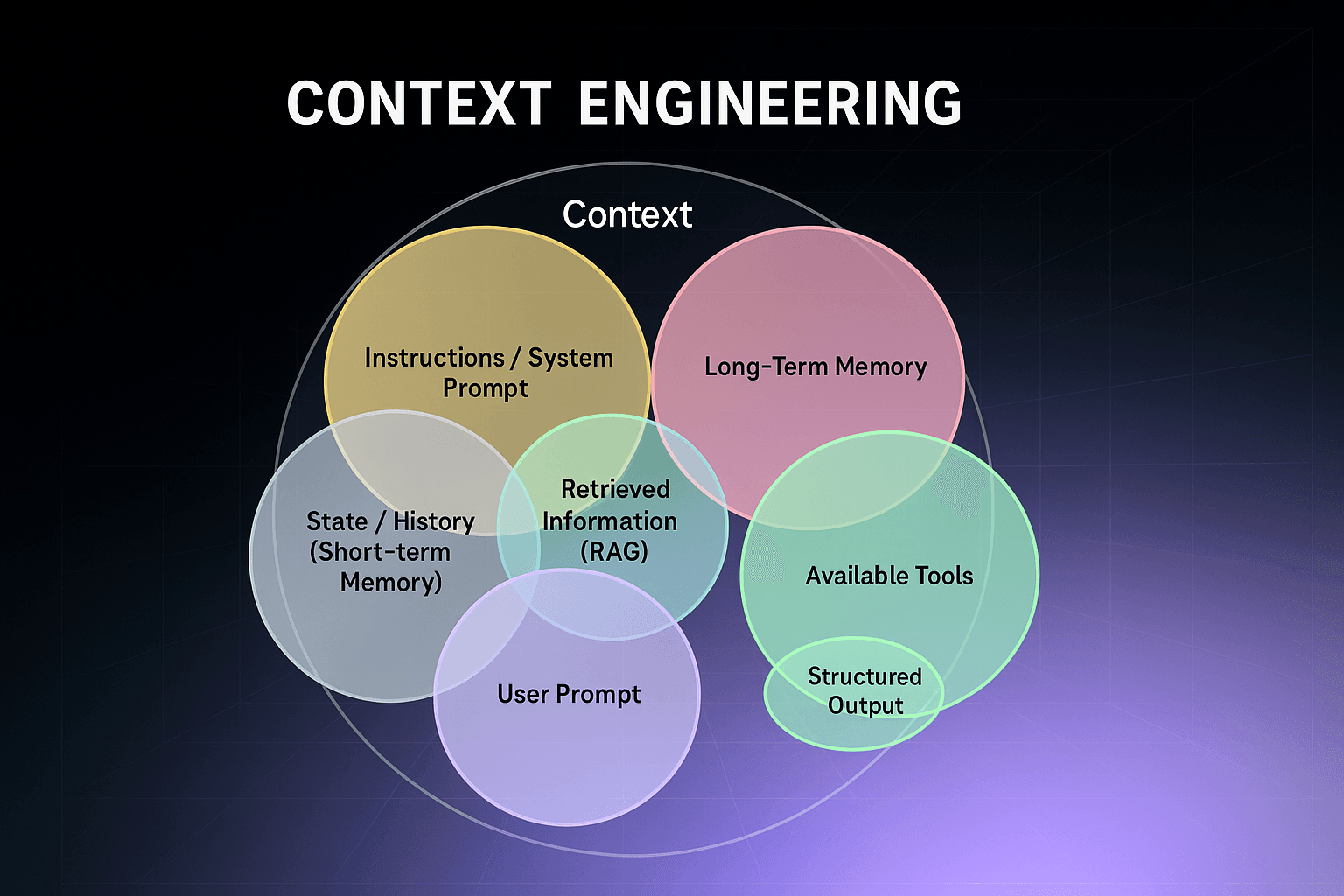
Understanding context types
Ensuring success first comes by understanding that not all context is the same, and builders must be precise in the types of context they leverage when building these systems.
Context types typically include:
Instructions: prompts, rules, few-shot examples, tool descriptions Knowledge: domain facts, retrieved data, semantic memory Tool feedback: prior decisions, API outputs, runtime signals
Managing this across agents requires structured context engineering strategies [4] :
Writing Context: Save information outside the context window so agents can reference it later (e.g. memory objects, files, or runtime state). Selecting Context: Retrieve only what’s needed at the moment by using RAG, similarity search, or filters to surface relevant data, instructions, or tools. Compressing Context: Summarize or trim past messages or tool outputs to prevent token bloat. Isolating Context: Give each agent a scoped window to avoid conflict or distraction.
The idea is to leverage and ensure strategic injections of different context types, message passing, and coordination strategies when building multi agent systems, builders can ensure agents receive the right information dynamically as the multi-agent system runs.
Here’s how its done.
Context engineering best practices
Effective multi agent systems require an architecture that encodes contextual awareness at the agent level by ensuring each agent has a precise understanding of its role, scope, dependencies, and decision boundaries.
This begins by systematically answering the following design questions for every agent:
What decisions have other agents already made that will affect this agent's work? In a multi agent customer support system, if the “triage agent” already classified the issue as a billing problem, the next agent (e.g. “solution agent”) should avoid reclassifying it or asking redundant intake questions. Context approach: Store decisions in shared state or memory and inject them into downstream prompts as structured flags (e.g. issue_type: billing). How do we prevent agents from making conflicting assumptions about the same task? In Anthropic’s research system, multiple sub-agents were assigned to collect different types of information about a single topic. If there were no shared task framing, one agent might focus on sourcing recent quantitative data, while another could interpret the same topic through qualitative or outdated sources ultimately leading to mismatched assumptions or conflicting conclusions. Context approach: Inject a unified task description and shared assumptions into each agent’s context block (e.g. “focus on policy impacts from 2020 onward,” or “prioritize official government sources”), and record framing decisions in shared memory so all agents stay aligned. What information from previous agent interactions is essential versus noise? In a multi-agent writing system (e.g. outline → draft → refine), only key decisions like tone, voice, and audience should be passed forward — not raw brainstorm content or irrelevant tool outputs. Context approach: Use summarization and context compression (e.g. summary_of_prior_steps) to reduce noise while preserving intent. How do we maintain consistency across parallel agents without full context sharing? When two agents independently summarize sections of the same research report, they may format or cite things differently. Context approach: Set formatting rules and shared stylistic instructions (e.g. APA citations, tone guidelines) as part of each agent’s prompt template. When agents work simultaneously, how do we avoid duplicated effort or contradictory outputs? In a workflow where one agent gathers data and another explains it, both might attempt to retrieve similar stats if unaware of each other’s roles. Context approach: Assign scoped responsibilities and dynamically reference shared memory to check what’s already been done (e.g. if "GDP data" exists in memory, skip retrieval).
TLDR;
Orchestration Pattern Coordination Mechanism Instructions Knowledge Tool Feedback Replayability Dynamic Tool Routing Supervisor Message Passing (Direct) High Medium (optional) High Supported Strong Hierarchical Message Passing + Shared State (Light) High Medium (stage-specific) High Limited Limited Network (Peer-to-Peer) Shared State Medium (static) High High Strong Strong
Common mistakes to avoid
Here are the most common failure modes when building multi-agent systems, and how to design around them.
Failure Mode Cause Solution Strategy Token Sprawl Redundant context shared across agents Trim prompts, use Corpus-in-Context, compress tool output Coordination Drift Misaligned roles, prompt changes Modular prompt versioning, audit history, observability Context Overflow Too much information in context window External memory, scoped scratchpads, summarization Hallucination Incomplete or conflicting grounding Better context filtering, evaluation, memory QA
Token sprawl often becomes the blocker in multi agent system often consuming up to 15x more tokens than standard chat interactions, making them viable only for high-value workflows where the performance gains justify the cost [1] .
Coordination drift poses major risks, especially when agents lack shared grounding, produce contradictory outputs, or depend on outdated intermediate steps [5] . These issues become even more pronounced as systems scale due to the exponential growth in agent interactions and communication overhead [6] .
Context overflow requires careful information architecture, so by designing your system to pass only essential context between agents rather than full conversation histories, context overflow and subsequently hallucinations can be avoided.
Scaling multi-agent systems without the proper tooling is incredibly hard; managing distributed prompts, coordinating across agents, and keeping everything observable isn’t something most teams can pull off.
It takes the kind of infrastructure that is purpose-built to turn best practices into real, working systems.
Enter Vellum.
Building multi agent systems in Vellum
Vellum is designed to provide the infrastructure necessary to orchestrate complex agent systems, with a tooling and feature set that ensures mission critical accuracy at deployment.
We provide a robust toolkit for experimentation, evaluation, and production management. This is where Vellum becomes your control panel for building sophisticated agents.
Here is how Vellum supports the coordination strategies and context patterns covered above:
Solving Token Sprawl:
Corpus-in-Context and RAG Pipelines pull in only the most relevant external knowledge with long-context optimization, eliminating redundant information sharing Prompt Engineering Tools enables dynamic, role-specific prompts using templating, ensuring each agent receives only necessary context
Preventing Coordination Drift:
Prompt Sandbox and Versioning provides safe testing environments to monitor prompt evolution and tag stable releases Evaluation and Observability enables regression testing and live monitoring of agent performance to catch drift early Deployment and Rollbacks allows teams to safely revert prompt configurations without downtime when coordination issues arise
Managing Context Overflow:
Workflow Orchestration and Prompt Nodes supports external memory integrations and scoped information passing between agents Prompt chaining and branching logic ensures agents receive appropriately sized context windows
Reducing Hallucination:
Evaluation and Observability provides continuous output comparison and scoring to identify conflicting agent outputs Better context filtering through RAG pipelines ensures agents work with accurate, relevant grounding information
With the right design approach and right platform, like Vellum, that provide system-wide visibility and structure needed to build multi-agent workflows, teams can turn multi-agent experimentation into a reliable, efficient workflow cheat code.
Ready to build multi agent systems that actually work on Vellum?
Start with Vellum's free tier to see how a scalable development infrastructure supercharged with the proper tools for context engineering transform your multi agent AI from failure to production grade.
Get started with Vellum free →
{{general-cta}}
FAQs
1) What is a multi-agent system?
A multi-agent system is a setup where multiple AI agents work together to complete highly specific or complex tasks. Each agent has its own role, context, or specialization to adress key pieces of a complex task. They often collaborate through coordinated workflows, shared context, or message passing.
2) What is the best architecture for multi agent AI systems?
It depends on your workflow. Use a supervisor pattern when central control is important, a hierarchical pattern when tasks follow a linear sequence, and a network (peer-to-peer) pattern when agents operate independently and coordinate via shared state. Platforms like Vellum make it easier to experiment with and compare these structures using visual workflows and prompt chaining.
3) How do I prevent agents in a multi agent system from contradicting each other?
Content engineering. Use context isolation, scoped prompts, shared memory, and message-passing rules. Agents should be aware of relevant system-wide decisions and avoid acting on conflicting assumptions, context engineering strategies help with this.
4) How can I make multi agent workflows more cost-efficient?
Minimize token usage by compressing context, limiting redundant messages, and only retrieving relevant information using RAG or similarity search. Systems like Vellum can help optimize context flow and token management automatically through prompt versioning and evaluation tools.
5) Can I dynamically activate agents based on task context or tool output?
Yes, dynamic agent routing allows workflows to trigger the right agent based on runtime data, decision state, or external signals. Vellum supports conditional logic and multi-step workflows for exactly this use case, helping teams automate complex AI behavior without heavy engineering.
6) How do I audit or replay multi agent runs for debugging?
Replay-ability comes from structured logging and state tracking. With Vellum, you can track agent prompts, outputs, and decision history—making it easy to debug, compare, and iterate safely on multi-agent pipelines.
7) What’s the role of context engineering in multi agent systems?
It’s the backbone of success. Context engineering ensures every agent gets the right mix of instructions, knowledge, and tool feedback without being overwhelmed by irrelevant or outdated information.
8) What kind of memory or state management do multi agent systems need?
A shared memory or state object is typically used so agents can remain loosely coupled but coordinated. This allows agents to asynchronously read, write, and react without needing direct communication.
9) What is the best tool or platform to build a multi agent system?
Vellum. It’s built specifically to support the complexities of multi-agent coordination—offering workflow orchestration, scoped prompts, prompt versioning, shared memory access, evaluation tooling, and rollback support. Whether you’re experimenting or deploying to production, Vellum gives you the infrastructure to make multi-agent systems actually work.
10) How do I know when to move from a single agent to a multi-agent system?
The shift makes sense once a single agent consistently struggles with scope, latency, or accuracy of a complex task. Signs include: repeated token overflows, conflicting outputs, or bottlenecks where specialized roles would add value. Start small with orchestration experiments, and scale only once you’ve validated that multiple agents provide measurable gains.
11) How do I keep multi-agent systems reliable as they grow more complex?
Reliability comes from controlled iteration: version every prompt, add evals for each agent role, and centralize observability so you can trace how agents interact. Vellum makes this straightforward with built-in evaluations, per-agent versioning, run-level traces, and rollback support, so complexity doesn’t turn into unpredictability.
Extra resources
2026 Guide to AI Agent Workflows → GPT-5 Prompt Guide → AI Agent Parameters Guide → AI Agent Memory Management Guide →
Citations
[1] Anthropic. (2025). How We Built Our Multi-Agent Research System
[2] Kubiya. (2024). Single Agent vs Multi Agent AI: Which Is Better?
[3] Cognition AI. (2024). Don’t Build Multi-Agents
[4] LangChain. (2024). Context Engineering for Agents
[5] Anna A Grigoryan (2025). Why Do Multi-Agent LLM Systems Fail?
[6] Arxiv. (2025). Why Do Multi-Agent LLM Systems Fail?