
GPT-5 is finally here! It comes with 400k context window, and 128k output window. That’s a nice upgrade, given that the price is on the lower end $1.25/$10 for input/output tokens.
It’s available in ChatGPT Pro and in the API starting today.
It feels like this model is topping all benchmarks right now, and it’s a model that’s greatly optimized for reliability, health queries and safety.
Let’s take a look!
💡 Want to see how GPT-5 compares to Claude, Gemini, Grok for your use case? Compare them in Vellum.
Math capabilities
This is the first time we’re seeing 100% on a newly generated benchmark like AIME 2025. This benchmark is modeled after the American Invitational Mathematics Examination (AIME), a high-school level math competition in the U.S.
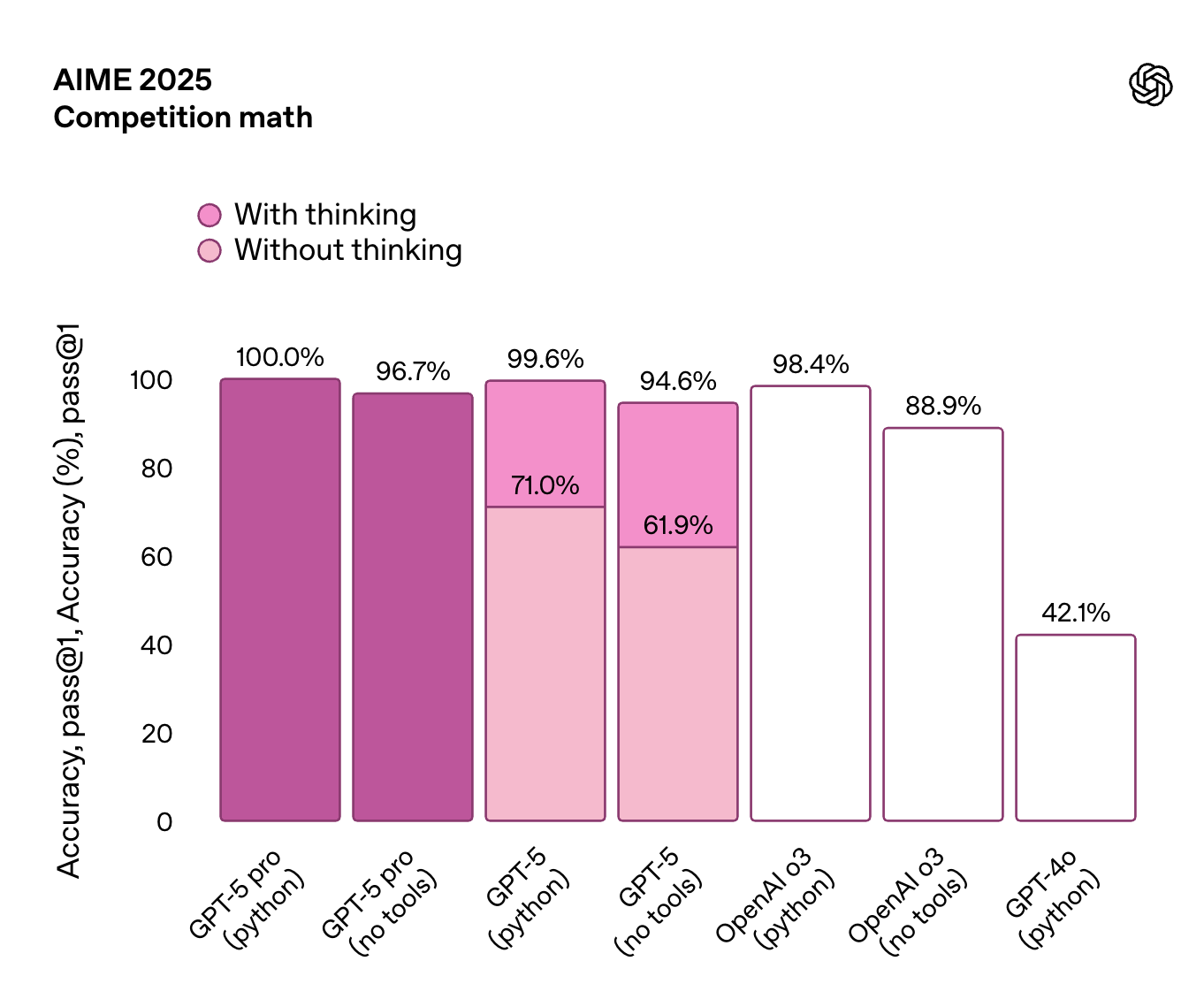
From these benchmarks we can see that:
GPT-5 pro (with Python tools) scores a perfect 100% accuracy "With thinking" (chain-of-thought) gives a big boost to all versions of GPT-5, especially the one without Python tools (jumping from 71.0% to 99.6%). GPT-4o in comparison looks so bad here :)
But how does it compare with other models on the market?
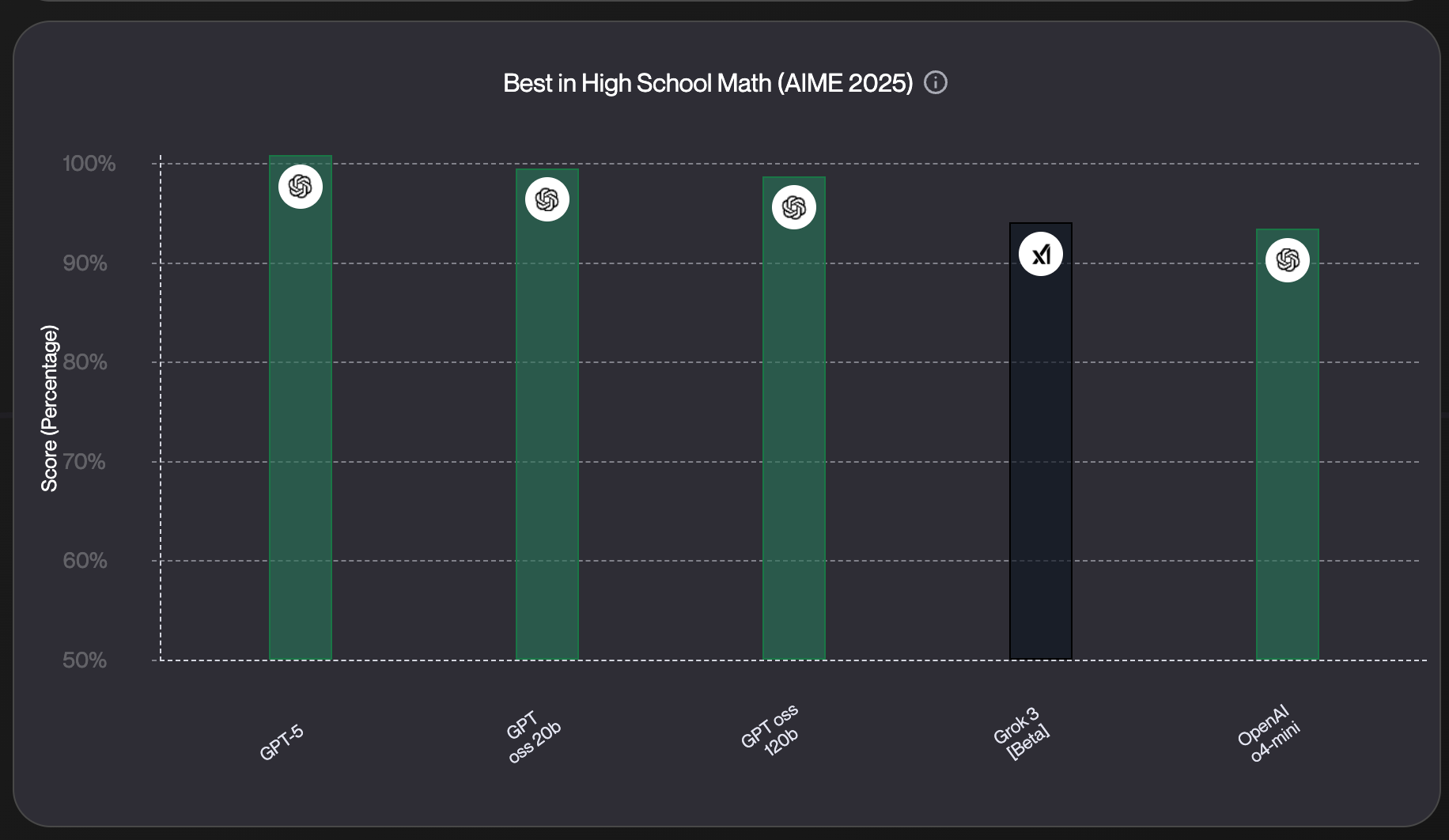
If we check our leaderboard , we can notice that OpenAI is dominating this benchmark, and only Grok 3 managed to secure a spot in the top 5 here:
Reasoning capabilities
When it comes to reasoning capabilities, we usually look at the GPQA Diamond benchmark.
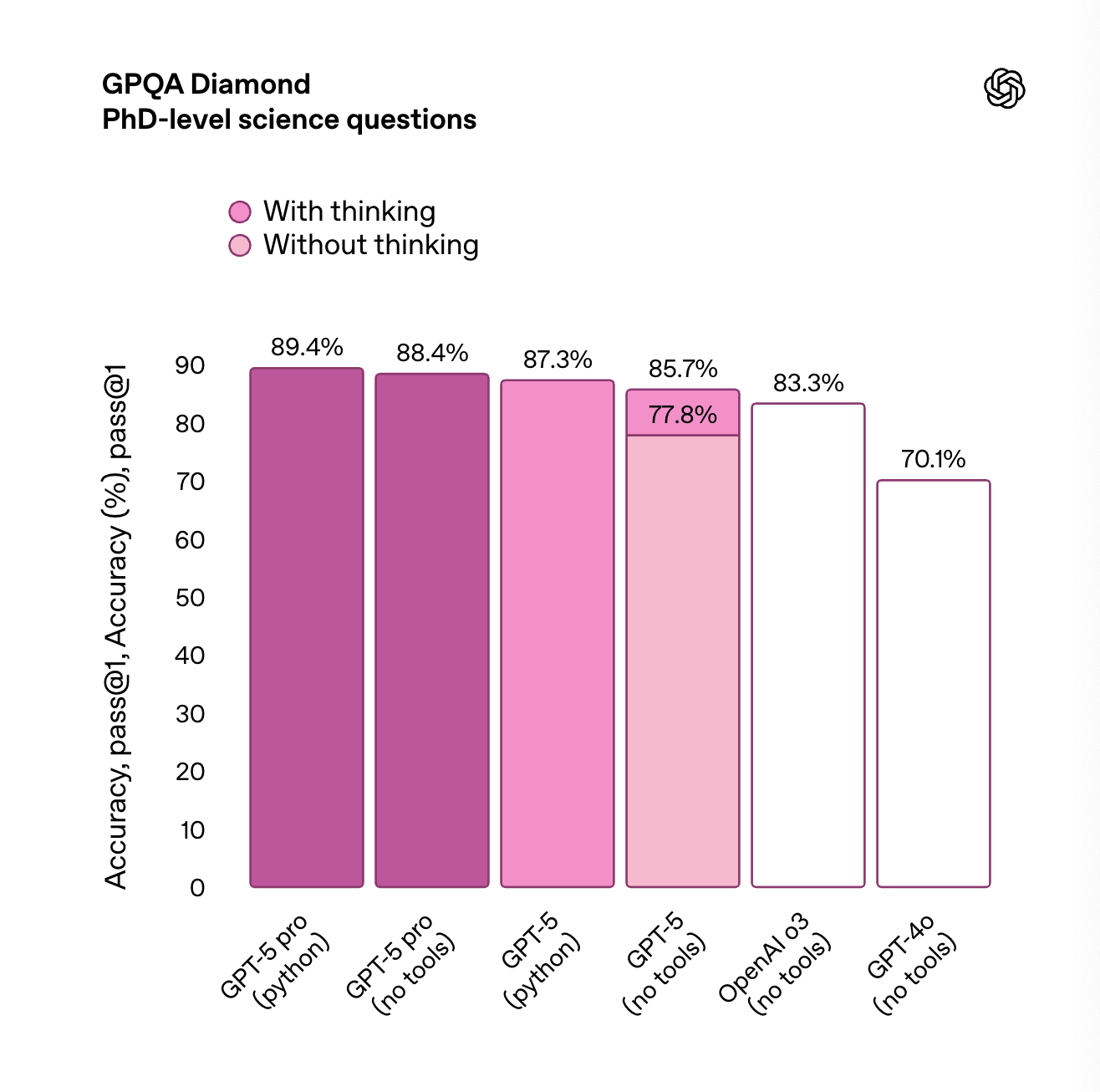
From the image above we can see that:
GPT-5 pro (with Python tools) scores the highest at 89.4% on PhD-level science questions, slightly ahead of its no-tools variant. "Thinking" helps noticeably , especially for GPT-5 (no tools), which jumps from 77.8% to 85.7% when reasoning is enabled. GPT-4o falls behind at 70.1% , showing a big gap in handling complex scientific reasoning compared to GPT-5 variants.
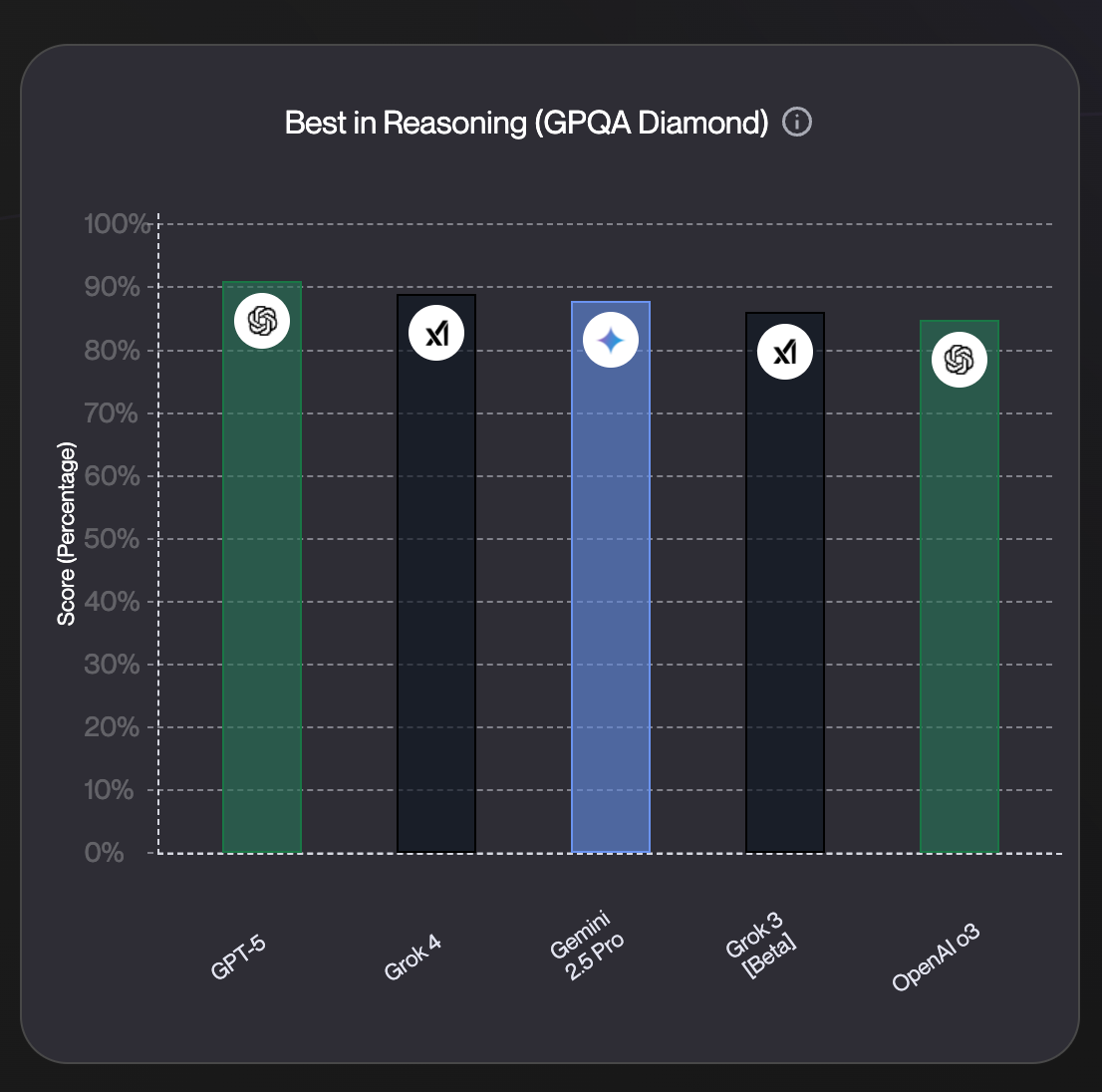
From our leaderboard we can see that GPT-5 Pro (Python) is at the first place when compared to other models on the market. Gemini 2.5 Pro and Grok 4 are close behind on this one.
Code capabilities
Now this is where things get interesting. Historically Claude models were stealing the spot for all things related to coding capabilities.
The SWE-bench Verified: Tests how well models can fix real-world GitHub issues by editing code. The other benchmark, Aider Polyglot, measures multi-language code editing skills, checking if models can make correct changes across different programming languages. Both are widely used to evaluate these models on software engineering tasks.
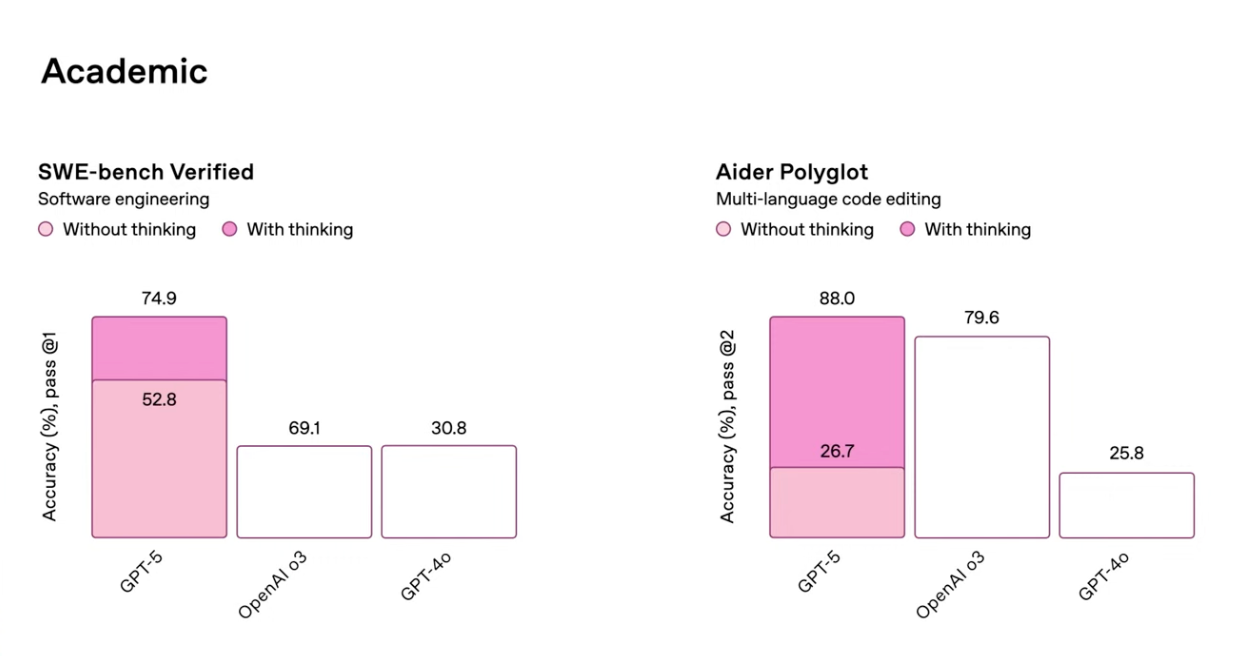
We can see that
GPT-5 leads both academic benchmarks when compared with other OpenAI models, on SWE-bench Verified it’s at 74.9% and Aider Polyglot at 88% when “thinking” (chain-of-thought reasoning) is enabled. Reasoning gives a huge boost to GPT-5: +22.1 points on SWE-bench and +61.3 points on Aider Polyglot. GPT-4o performs the weakest in both benchmarks, showing limited ability to solve complex code-related tasks compared to newer models.
How does it compare with other models?
For the SWE-bench comparison, Grok 4, GPT-5, and Claude Opus 4.1 all perform similarly. To get a clearer picture, we’ll need more practical tests from coding agents like Codium, Lovable, and other tools built for real-world dev workflows.
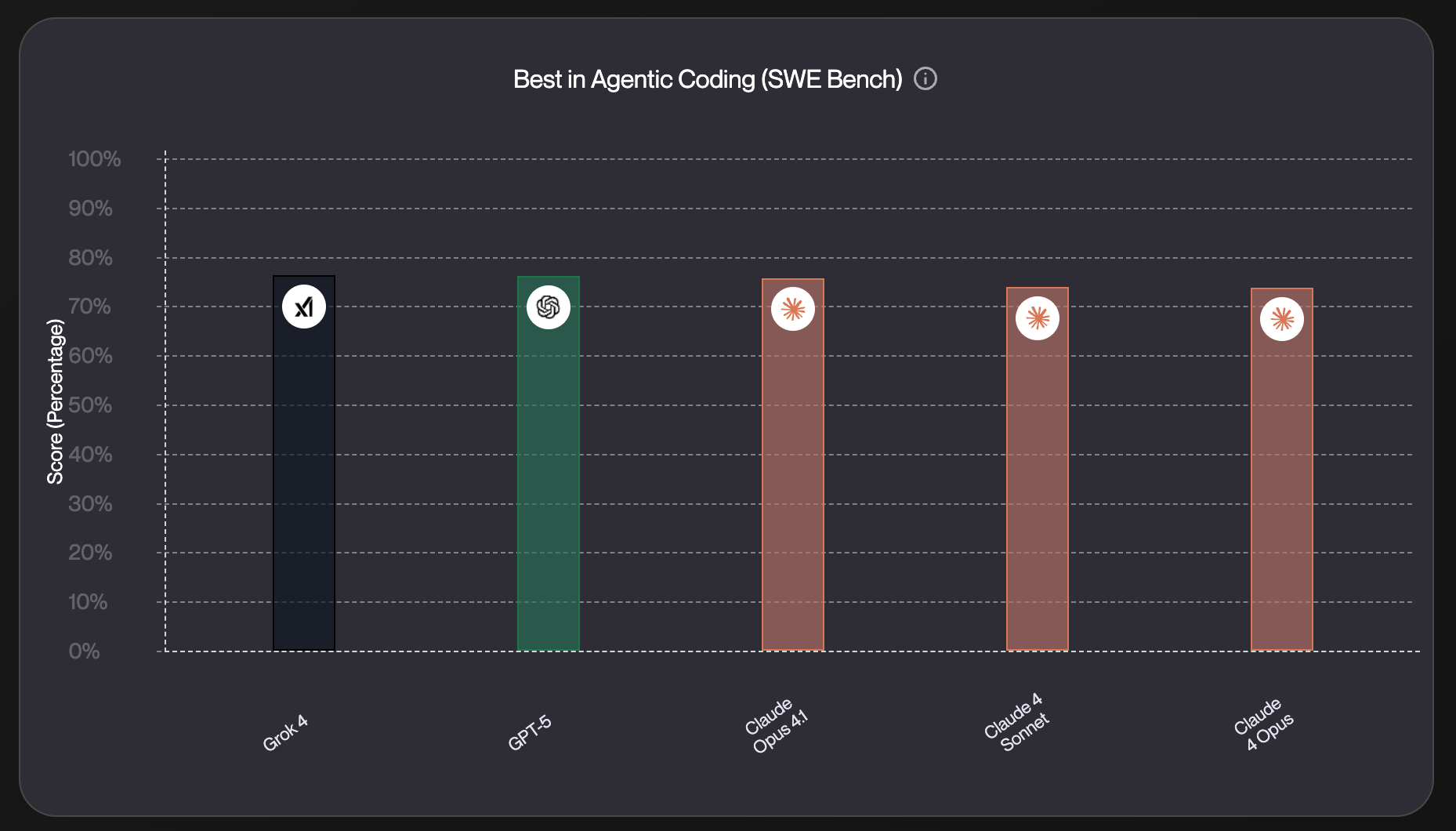
Reliability capabilities
The biggest emphasis with GPT-5 is on reliability and safety ; especially when it comes to health-related questions , where accuracy truly matters.
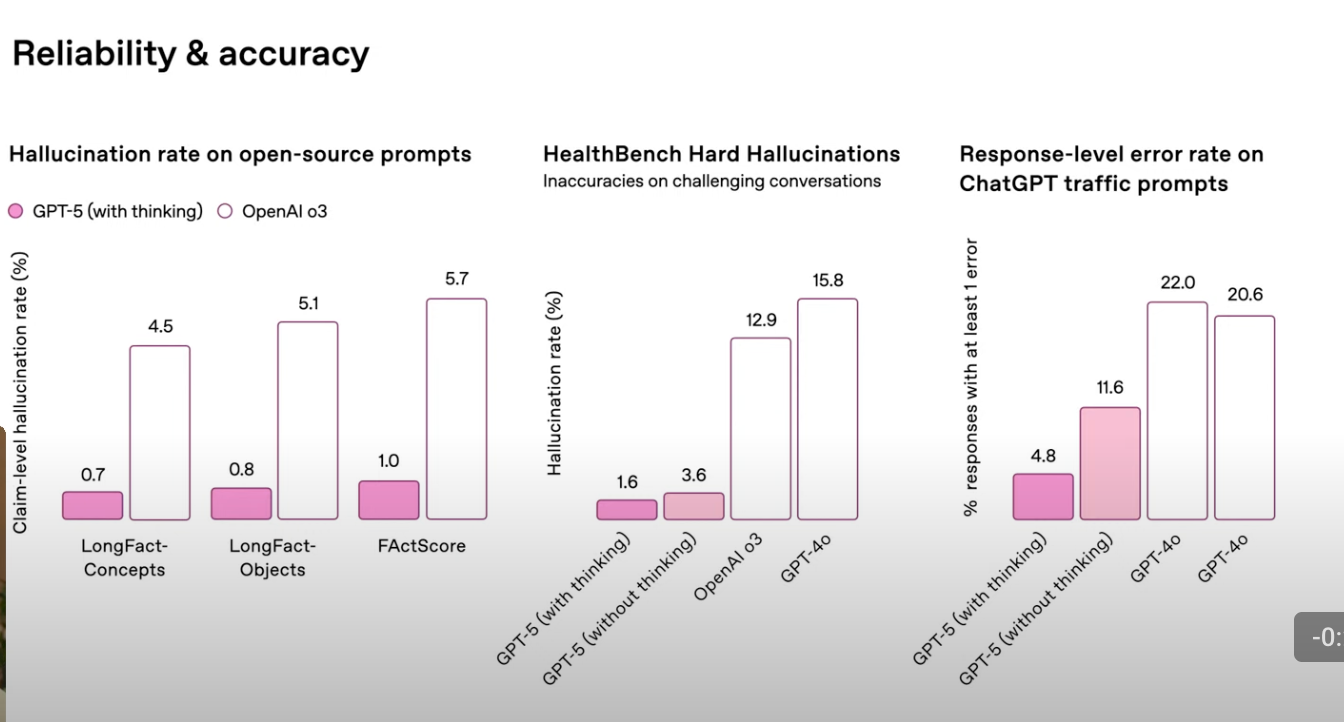
GPT-5 (with thinking) has the lowest hallucination and error rates across all benchmarks. Under 1% on open-source prompts and just 1.6% on hard medical cases (HealthBench). Reasoning mode makes a big difference : GPT-5 drops from 11.6% to 4.8% in real-world traffic error rates when “thinking” is used. GPT-4o seems like a very bad model here. It has very high error rates , especially on HealthBench ( 15.8% ) and traffic prompts ( 22.0% ). OpenAI o3 performs better than GPT-4o , but still lags GPT-5 in all categories
Looks like they meant it when they called GPT-5 the most reliable and factual model yet.
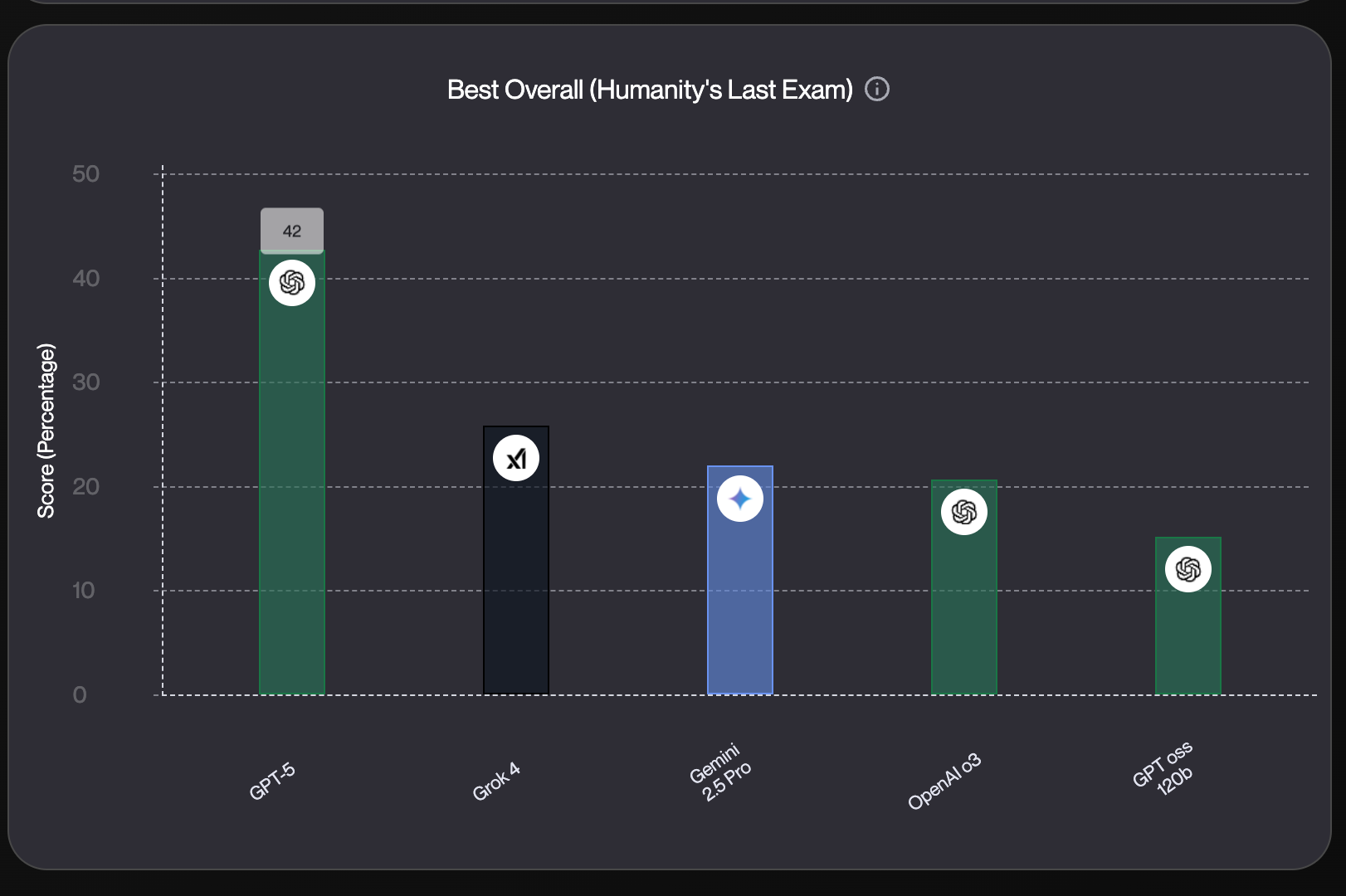
Humanity’s Last Exam
We also benchmark these models on the Humanity’s Last exam which is designed to push AI to its limits across a wide array of subjects.
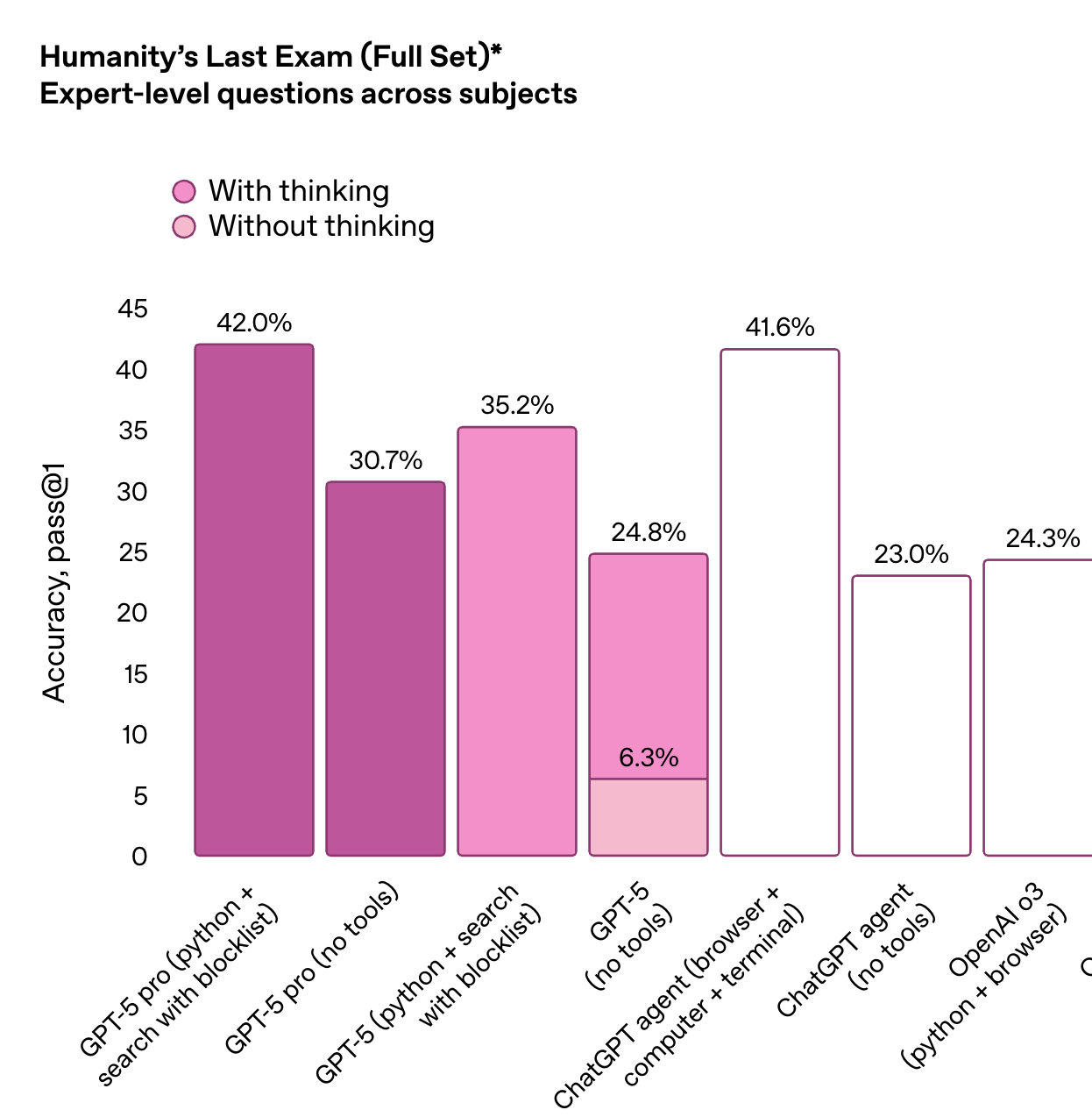
GPT-5 pro (with tools and reasoning) has 42% accuracy on expert-level questions, slightly ahead of the best-performing ChatGPT agent setup (41.6%). "Thinking" dramatically boosts performance , especially for base GPT-5 (no tools), jumping from 6.3% to 24.8% . Agent-based setups (using tools like browser and terminal) still lag behind GPT-5 pro, showing there’s room for improvement in tool orchestration.
And even across ALL other models, the jump in performance from GPT-5 is staggering. They almost doubled the accuracy from the previous OpenAI O3 model, and it’s noticeably more ahead from any other model on the market.
Conclusion
I’ll keep it short.
Seems like OpenAI has the leading model on the market, once again. Go update all of your models :)
Extra resources
Beginner’s Guide to Building AI Agents → Best Enterprise AI Agent Builder Platforms → Best Low code AI Workflow Automation Tools → Guide: No Code AI Workflow Automation Tools → Best AI Workflow Platforms →
{{general-cta}}






