
Everything You Need to Know About GPT-5.5
OpenAI released GPT-5.5, the first fully retrained base model since GPT-4.5. Here's the full benchmark breakdown, how it compares to Claude Opus 4.7, pricing, and what developers are saying.

OpenAI released GPT-5.5, the first fully retrained base model since GPT-4.5. Here's the full benchmark breakdown, how it compares to Claude Opus 4.7, pricing, and what developers are saying.

Karpathy calls it AI psychosis. Garry Tan calls it cyber psychosis. Researchers call it brain fry. I call it competence addiction. Here's what's actually happening to the people building with AI.
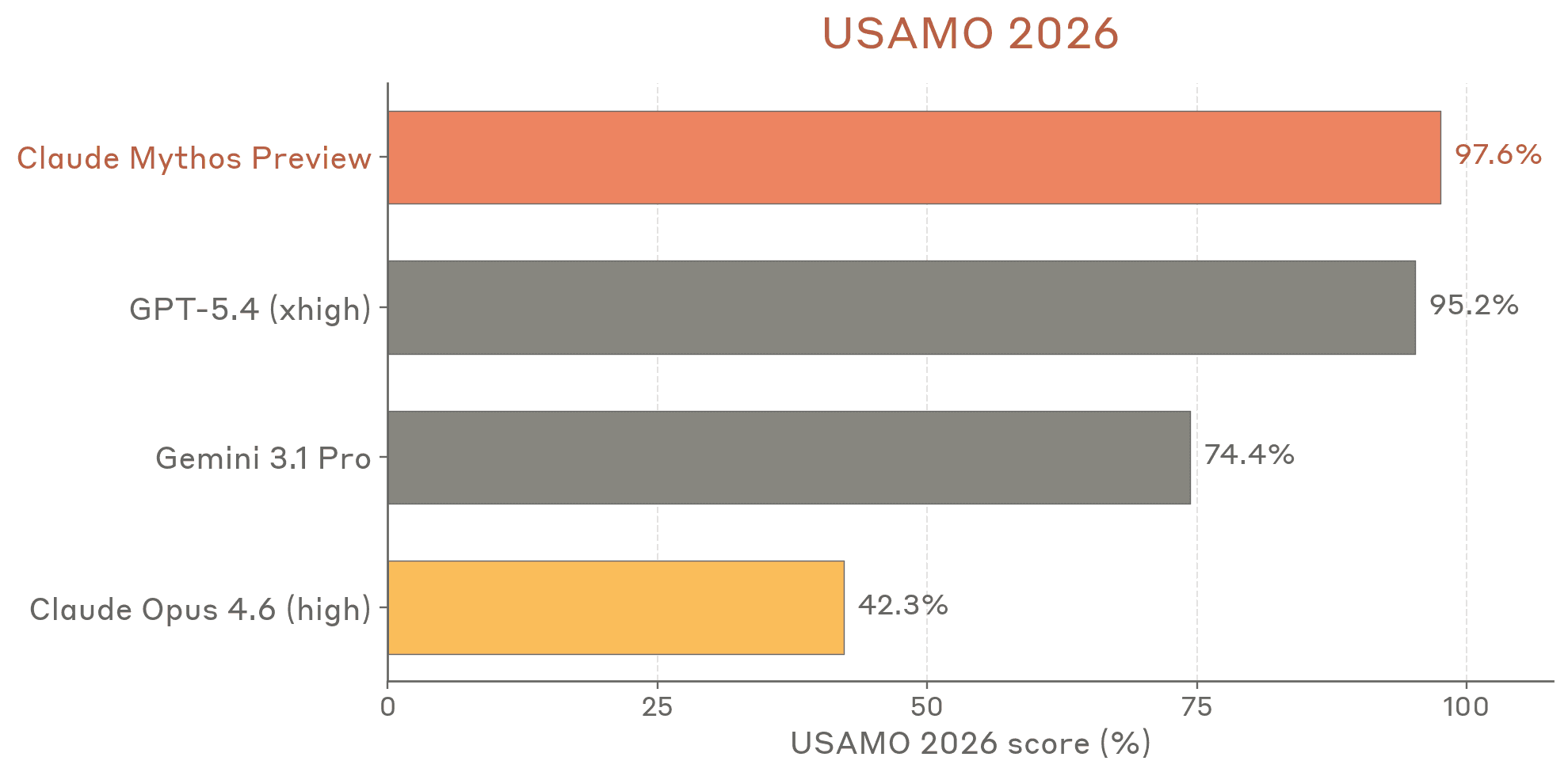
Anthropic published a 200+ page system card for Claude Mythos — their most capable model yet. Here's what's in it and why it matters.

Learn what OpenAI's logprobs are and how can you use them for your LLM applications

A choice dependent on specific needs, document types and business requirements.

See how GPT-5 performs across benchmarks; with a big focus on health

How verifiable mandates are creating a secure foundation for AI-driven commerce.

Think your APM tool has your AI covered? Think again. LLMs need their own observability playbook.

A breakdown of OpenAI’s new Agent Builder and what it signals for the future of building and deploying AI agents.

Exploring zero-shot & few-shot prompting: usage, application methods, and limits.

We break down when Chain-of-Thought adds value, when it doesn’t, and how to use it in today’s LLMs.

Compare top AI platforms for fast, reliable development in 2025.

You can’t improve what you can’t see, so start tracking every decision your agent makes.

A practical guide to deploying agentic capabilities: what works, what doesn’t, and how to keep it reliable in prod.

Building AI agents is 10x easier with 10,000+ tools and built-in LLM tooling support
Just another eval confirming 90% discount with highest performance from GPT-OSS 120b.

A curated list of best practices, techniques and practical advice on how to get better at prompt engineering.

LLMs carry hidden traits in their data and we have no idea how.

Go from idea to AI workflow in seconds and continue to build in the UI or your IDE.
Complete control over the business logic and runtime of your AI workflows in Vellum.

What’s shaping AI products, agents, and infrastructure in 2025.

A side-by-side look at Humanloop and 10 other LLM platforms.

Analyzing the difference in performance, cost and speed between the world's best reasoning models.

Build a functional chatbot using Vellum AI Workflows and Lovable with just a few prompts.

A quick guide to picking the right framework for testing your AI workflows.
Evaluating SOTA models if they can really reason

A wake up call to not underestimate the unique challenges of working with LLMs.

LLMs are stepping outside the sandbox. Should you let them?

See how Drata leveraged Vellum to build enterprise-grade AI workflows that enhance GRC automation.

Support for IBM granite models in Vellum.
Comparing GPT-4.5 and Claude 3.7 Sonnet on cost, speed, SAT math equations, and adaptive reasoning skills.

Feels more natural, hallucinates less, can be persuaded—and it’s not a game-changer.
Learn how the latest Anthropic's model compares to similar top-tier reasoning models on the market.

Learn how Vellum enables Rely Health to rapidly build, test, and deploy AI-powered patient care solutions.

Learn how to optimize prompt versioning, debug efficiently, and make real-time updates to boost AI performance.

Evaluating the 'thinking' of Claude 3.7 Sonnet and other reasoning models to understand how they really reason.

Explore how O1 and R1 perform on well-known reasoning puzzles—now tested in new contexts.

Learn how DeepSeek achieved OpenAI o1-level reasoning with pure RL and solved issues through multi-stage training.
Rate limiting and downtime are common issues with LLMs — here’s how to manage it in production.

Learn how the latest model from Meta, Llama 3.3 70b compares to GPT-4o on three tasks

Now you can run Llama 3.1 405b, with 200 t/s via SambaNova on Vellum!

Share your AI process in our 4-minute anonymous survey. Get early insights and a chance to win a MacBook M4 Pro.

Starting today, you can unlock 2,100 t/s with Llama 3.1 70B in Vellum for real-time AI apps.

Discover how Glowing leverages Vellum's Workflows to create innovative AI solutions for the hospitality industry.

Learn how to prompt OpenAI o1 models, understand their limits and the opportunities ahead.
Understand the latest benchmarks, their limitations, and how models compare.

Learn how Woflow sped up AI development by 50% — making it easier to handle errors, improve models and ship updates.

Explore how a leading EdTech company saves 50 eng hours per month and empowers everyone on the team to contribute.

Learn critical strategies to build and launch AI systems quickly and reliably.

Learn how Odyseek used Vellum to simplify AI development and improve team collaboration.
Discover How Llama 3.1 405b Stacks Up Against GPT-4o, Gemini 1.5 Pro, and Claude 3.5 Sonnet on Three Tasks
Explore Llama 3.1 70b's upgrades and see how it stacks up against same-tier closed-source models.
Learn how Claude 3.5 Sonnet compares to GPT4o on data extraction, classification and verbal reasoning tasks.

Find out how Llama 3 70B stacks up against GPT-4 in terms of cost, speed, and performance on specific tasks.

Learn how Rentgrata used Vellum to evaluate their chatbot, and cut development time in half.
Discover what are the main differences between LangChain and LlamaIndex, and when to use them.
Learn how RAG compares to fine-tuning and the impact of both model techniques on LLM performance.
Learn how to use OpenAI function calling in your AI apps to enable reliable, structured outputs.

Iterating on prompts using OpenAI's playground & Azure AI studio was challenging, until Autobound discovered Vellum.

Discover how Redfin used Vellum to develop and evaluate a production-ready AI assistant, now live in 14 markets.
Learn how to use Tiktoken and Vellum to programmatically count tokens before running OpenAI API requests.

Learn how to improve LLM outputs, and make your setup more reliable using prompt chaining.
Learn how to use retrieval and content generation metrics to consistently evaluate and improve your RAG system.
Learn prompt engineering tips on how to make GPT-3.5 perform as good as GPT-4.

Learn how Lavender develops and manages more than 20 LLM features in production.

Learn how to prompt Claude with these 11 prompt engineering tips.

Learn how Vellum helped Codingscape to ship AI apps quicker and win more projects.
Learn how to build and evaluate intent handler logic in your chatbot workflow
Methods and techniques to reduce hallucinations and maintain more reliable LLMs in production.

What is LLM hallucination & the four most common hallucination types and the causes for them
Comparing the performance of Gemini Pro with zero and few shot prompting when classifying customer support tickets
Comparing GPT3.5 Turbo, GPT-4 Turbo, Claude, and Gemini Pro on classifying customer support tickets.
Learn how to use Tree of Thought prompting to improve LLM results
Discover how recent OpenAI developments have influenced user confidence and interest in OpenAI alternatives
Assistants API: Easy assistant setup with memory management - but what's under the hood?

How to use Multimodal AI models to build apps that solve new tasks and offer unique experiences for end users.
LLMs can label data at the same or better quality compared to human annotators, but ~20x faster and ~7x cheaper.

Learn how Vellum helped Narya.AI save time and make AI easy for everyone on their team.