Comparing Llama 3.1 70b vs. GPT-4o mini vs. Gemini 1.5 Flash vs. Claude 3.5 Haiku on Three Tasks
Open-source models are getting more powerful!
Apart from their largest model Llama 3.1 405b (which we evaluated here), Meta introduced a performance upgrade and 128K context window to their previous 70b model.
With this experiment we wanted to evaluate the 70b model on three tasks, math riddles, classification and verbal reasoning, and try to answer these questions:
How much better is the the new 70b model compared to the old one we compared in this analysis ? How does it compare to GPT-4o mini, Claude 3.5 Haiku, and Gemini 1.5 Flash?
Our findings show that the Llama 3.1 70b model improves over the previous version with 15% better accuracy in math tasks, 12% regression for reasoning tasks, and no change in customer ticket classification.
Also, when compared to the other models we learned that:
For math riddles , GPT-4o mini got 86% of the riddles right. In second spot we have Gemini 1.5 Flash with 71% accuracy, followed by Llama 3.1 70b with 64.% accuracy. Claude 3 Haiku was really bad at this task (29% accuracy) For classification of customer tickets , GPT-4o mini has the highest accuracy (72%) and precision (89%), showing it is very good at predicting positives correctly but misses many actual positives (for this task we care about precision). However, Claude 3.5 Haiku has the best F1 score at 75%, indicating a good balance between precision and recall, which can be a great option for specific use-cases like spam detection. For reasoning tasks , GPT-4o mini has the highest accuracy for these reasoning questions (63%). Claude 3.5 Haiku has the lowest accuracy (38%). Using open-source models through providers isn't the cheapest option. Other models, like GPT-4 mini, are much more affordable at $0.15 per 1M input tokens and $0.6 per 1M output tokens. High speed (throughput) and low latency remain advantages of open-source models, especially when run via providers like Groq or FireworksAI. Running Llama 70b opens up numerous multi-agent workflows that were previously hindered.
Our Approach
The main focus on this analysis is to compare Llama 3.1 70b with GPT-4o mini, Gemini 1.5 Flash and Claude 3.5 Haiku. We look at standard benchmarks, community-ran data, and conduct a set of our own small-scale experiments.
In the next two sections we cover:
Cost comparison Performance comparison (Latency, Throughput) Standard benchmark comparison (example: what is the reported performance for math tasks between Llama 3.1 70b vs GPT-4o?)
Then, we run small experiments and compare the models on three tasks:
Math Riddles Classification Verbal reasoning
You can skip to the section that interests you most using the "Table of Contents" panel on the left or scroll down to explore the full comparison between the models.
Cost Comparison
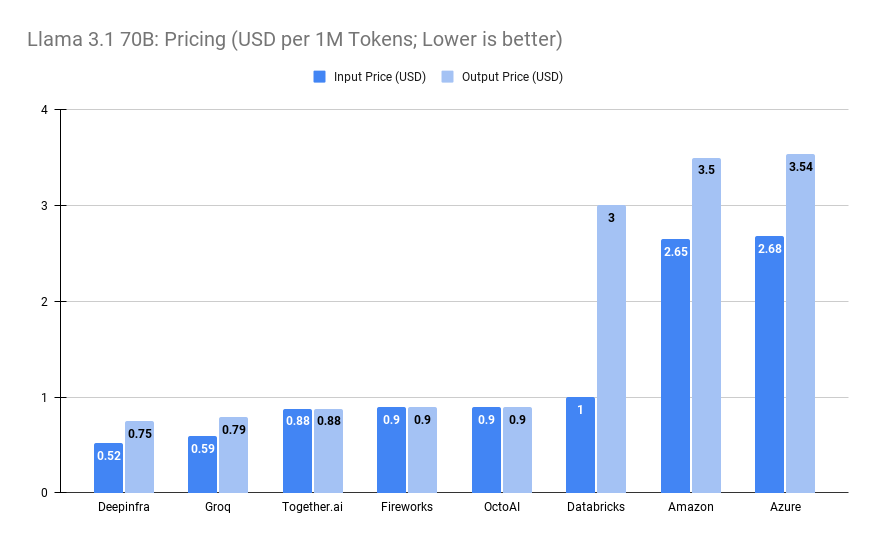
Since Llama 3.1 70B is open-sourced, you have many options to run it. You can decide to run it locally, or via a hosted version from various providers. Running these open source models was one of the cheapest options, but closed-source models are continuing to lower their prices as well.
For exmaple, OpenAI launched a pretty powerful but cheap model (GPT-4o mini) that costs $0.15 per 1M input tokens and $0.6 per 1M output tokens, which is very cheap considering that it’s a proprietary model.
Also, Claude 3.5 Haiku goes for $0.25/$1.25, Gemini 1.5 Flash for $0.35/$1.05 respectively which is still on the low end pricing even when compared to the cost to run Llama 3.1 70b.
But are closed-source models as fast as the open-source models running on providers like Groq or Fireworks?
Speed Comparison
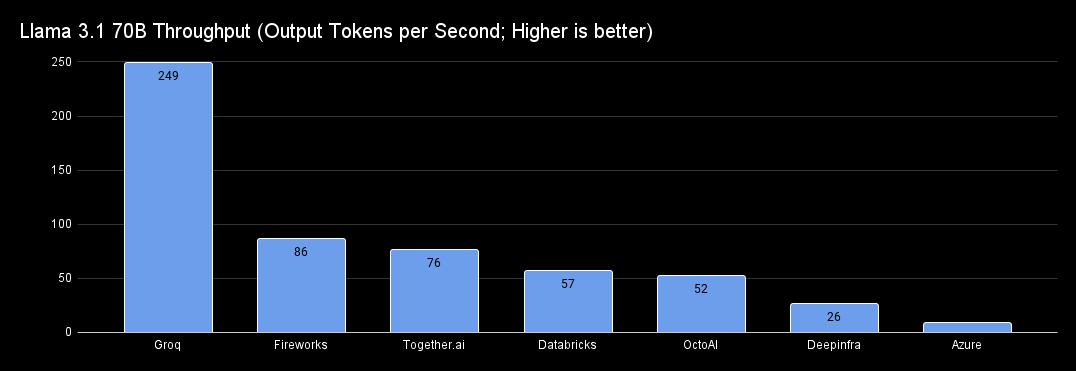
Open-source models run exceptionally fast with providers like Groq and Fireworks.
The Llama 3.1 70b can output ~250 tokens per second, which is very impressive. GPT-4o mini however is not that far as before, and it can output 103 tokens. The other two models are even faster with Claude 3.5 Haiku outputting 128 tokens, and Gemini 1.5 Flash 166 tokens.
Latency Comparison
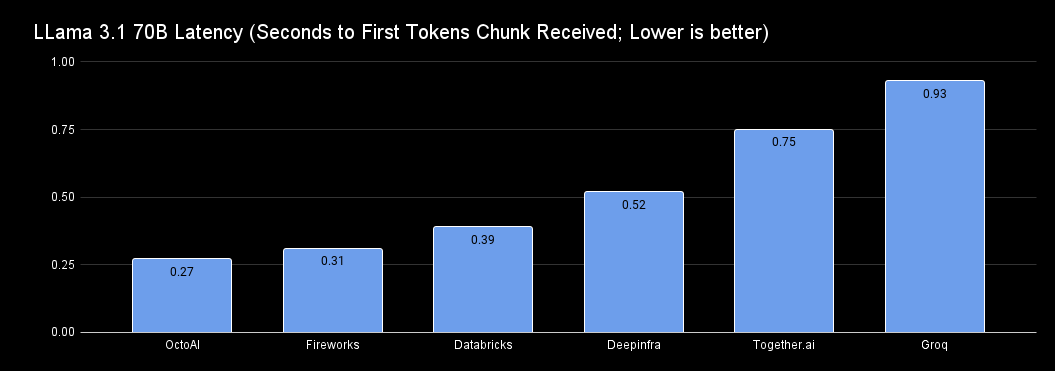
GPT-4o mini has a latency of 0.56 seconds, Claude 3.5 Haiku is at 0.52 seconds, and Gemini 1.5 Flash is at 1.05 seconds. With Llama 3.1 70b, you have at least four providers to choose from that can match or even offer lower latency than equivalent proprietary models.
Reported Capabilities
Standard benchmarks
When new models are released, we learn about their capabilities from benchmark data reported in the technical reports. The image below compares the performance of Llama 70b on standard benchmarks against the top five proprietary models and one open-source model.
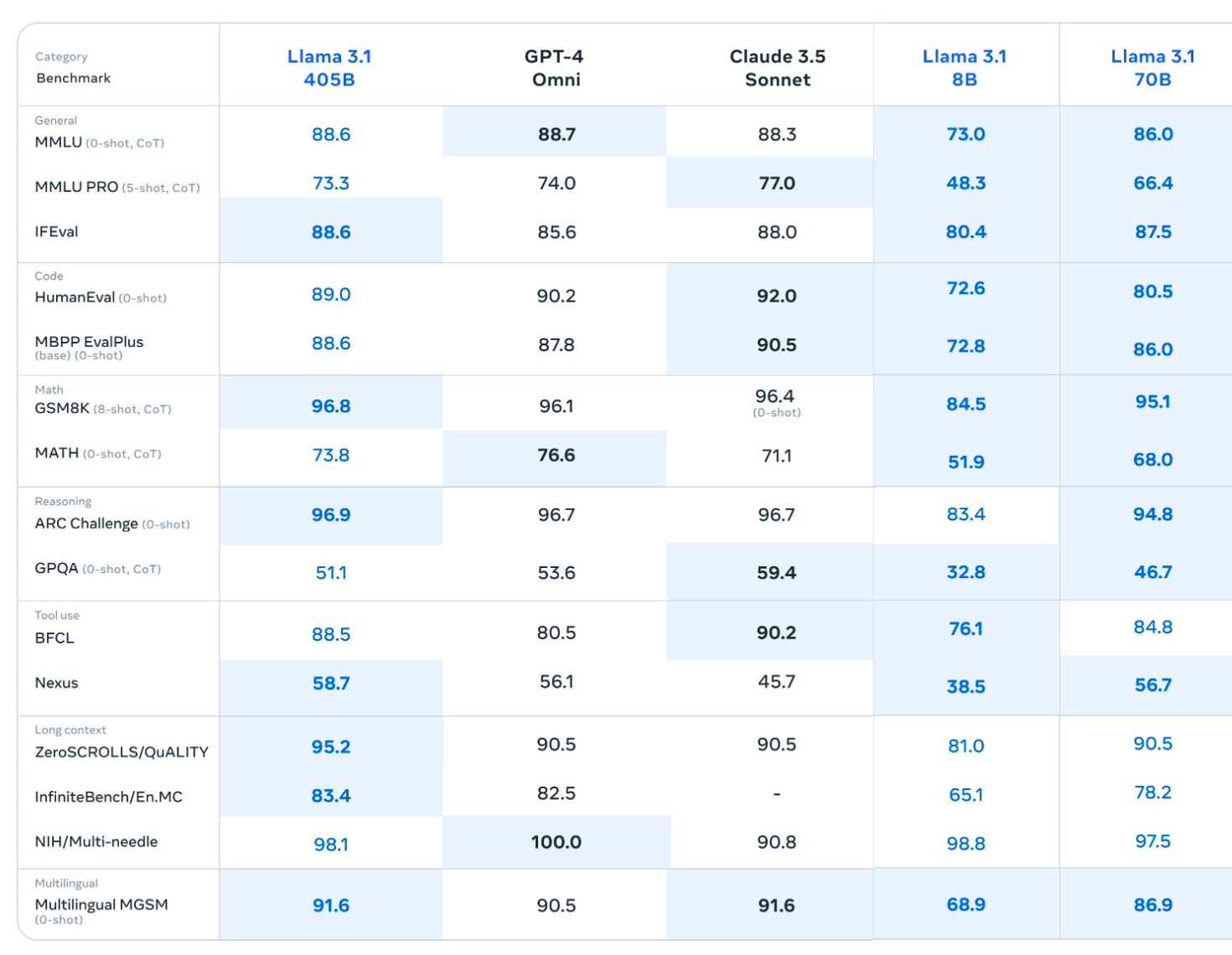
The data above shows that Llama 3.1 70b performs very well on math and reasoning tasks.
The 405b model is showing even better results compared to GPT-4o and Claude 3.5 Sonnet, and you can check our evaluation results here.
Now let’s look at our own small experiments.
Task 1: Math Riddles
In the previous section, we saw that Llama 3.1 70b is getting quite good at math tasks. Now, let's do a quick experiment to see if that's the case.
We picked a set of seven math riddles designed for students not yet in middle school and seven more at the middle school level as the cornerstone of the test. Here are a couple of example riddles and their source .
Here’s how the evaluation looks like in Vellum:
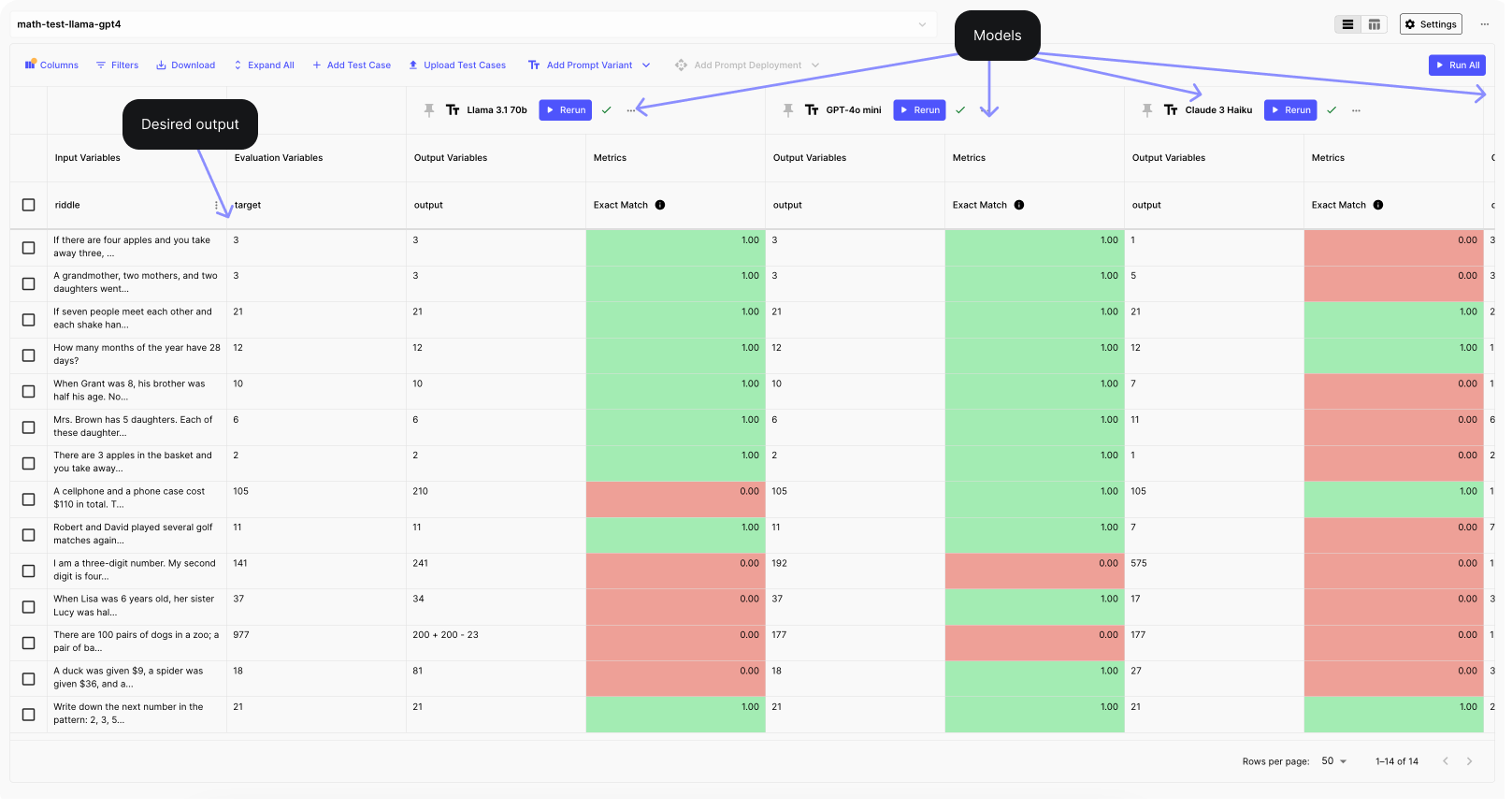
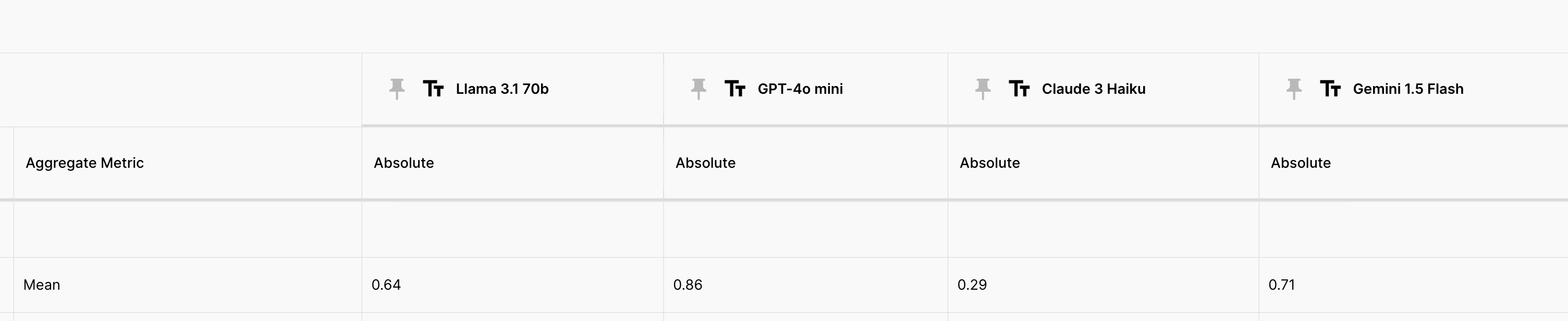
And here are the results we got when we ran the evaluation between all models:
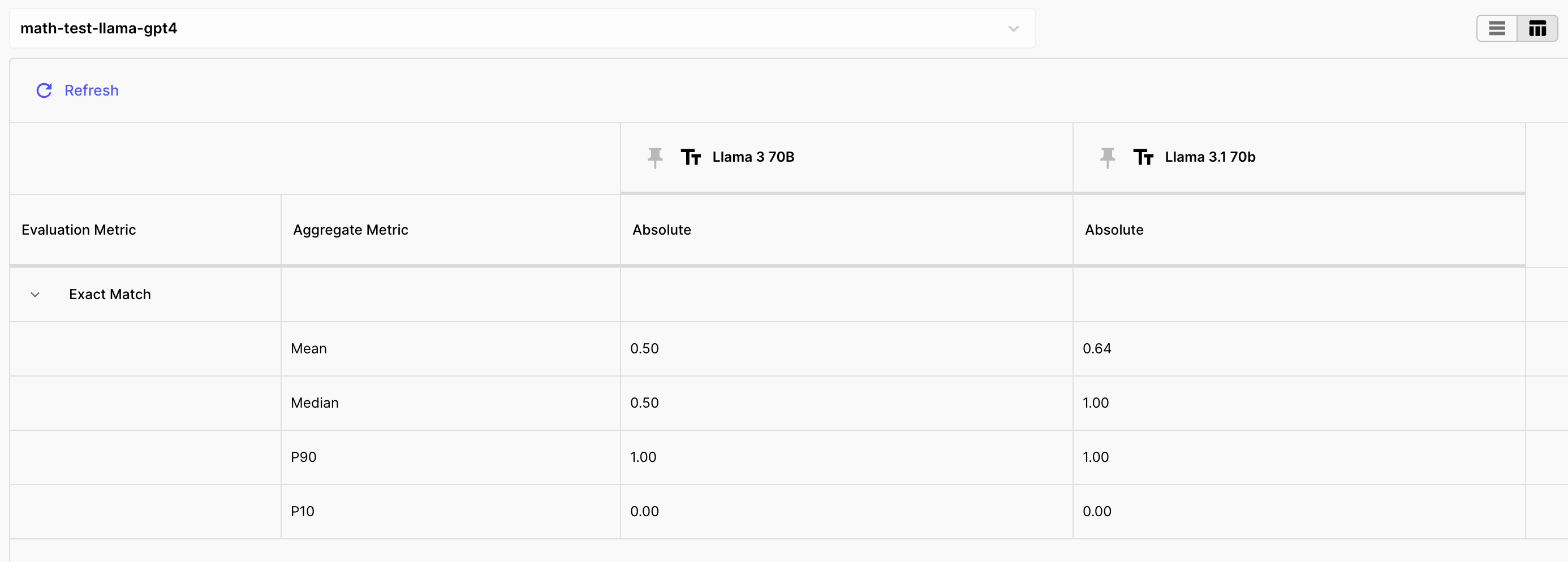
We also compared the previous Llama 70b model with the latest one:
Key Takeaways:
The latest Llama 3.1 70b shows a 14% improvement in Math questions compared to its previous version. GPT-4o mini is an absolute winner here, with 86% accuracy. In second spot we have Gemini 1.5 Flash with 71% accuracy. Claude 3 Haiku is really bad at this task, and only scored 29% accuracy.
Winner: GPT-4o mini.
Task 2: Classification
In this evaluation, we had all models to determine whether a customer support ticket was resolved or not. In our prompt we provided clear instructions of when a customer ticket is closed, and added few-shot examples to help with most difficult cases.
We ran the evaluation to test if the models' outputs matched our ground truth data for 100 labeled test cases.
From the evaluation report below we can see that GPT-4o mini got the highest accuracy (72%) out of them all. Interestingly enough, all the rest of the models showed similar accuracy ~ 68%.

While accuracy is important, it’s not the only metric to consider, especially in contexts where false positives (incorrectly marking unresolved tickets as resolved) can lead to customer dissatisfaction. To show which model is actually the best one for this task, we calculated the precision, recall and f1 score:
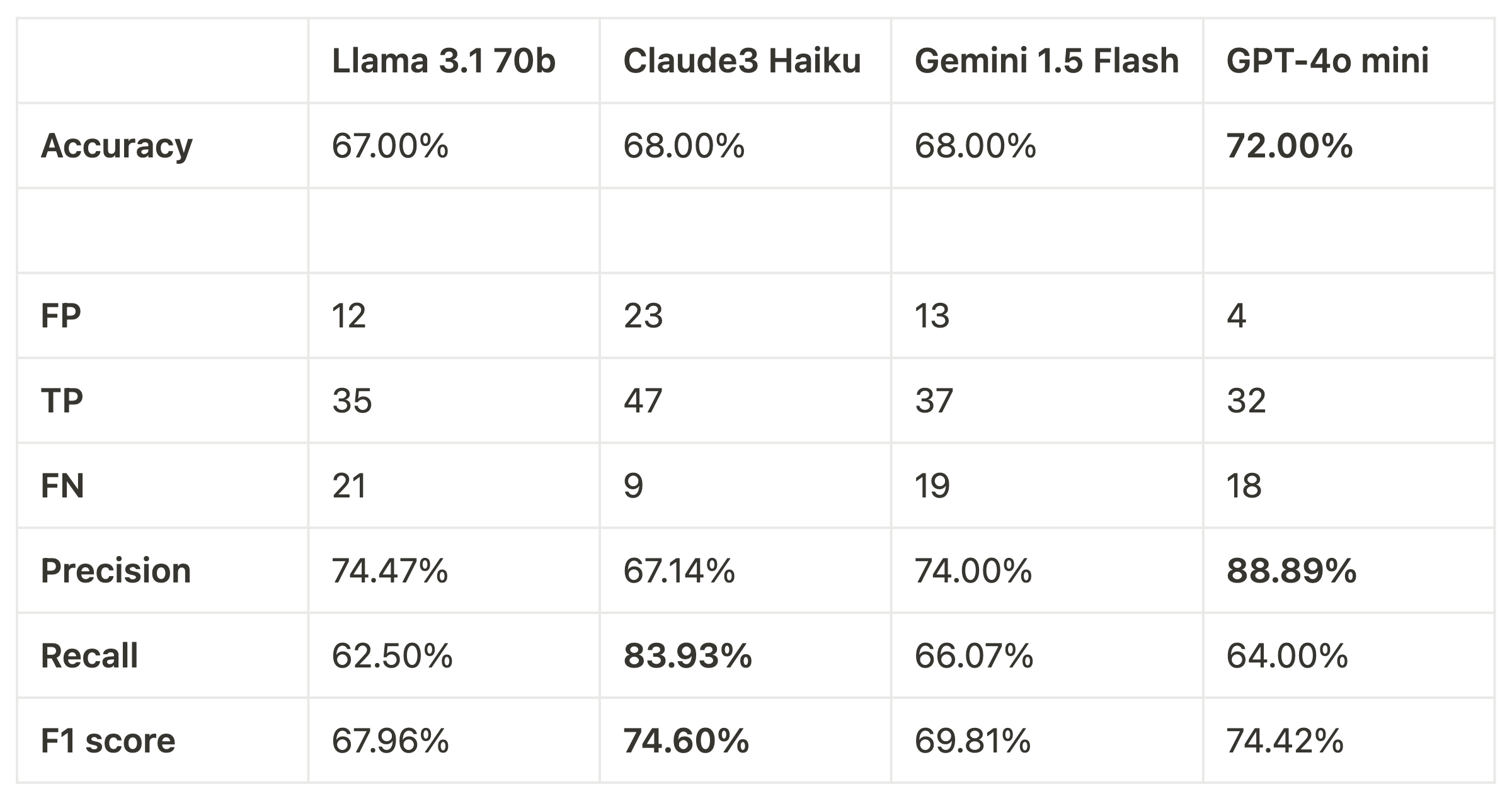
Key takeaways:
Best F1 Score : Claude 3.5 Haiku has the best F1 score at 75%, indicating a good balance between precision and recall, which can be a great option for specific use-cases like spam detection. GPT-4o is the second best here. Precision vs Recall Tradeoff : GPT-4o mini has the highest accuracy (72%) and precision (89%), showing it is very good at predicting positives correctly but misses many actual positives.
In classification tasks, it is important to balance various performance metrics based on the specific needs of the task. For our use-case (classifying customer tickets) we really care about correctly identifying not-resolved tickets and we really need precision to be high.
Winner: GTP-4o mini demonstrates better precision and accuracy than all other models. This would be our preferred model for this task.
Task 3: Reasoning
From the standard benchmarks, we saw that Llama 3.1 70b has pretty solid reasoning results. So we’ll run a small test to see how they actually compare. We picked a set of seven verbal reasoning questions and seven more arithmetic reasoning questions as the cornerstone of the test. Here is the source of the reasoning quesitons.
As you can see in the evaluation report below, GPT-4o demonstrates the highest accuracy (63%) for these reasoning questions. Llama 3.1 70b and Gemini 1.5 Flash have the same accuracy (44%).

We also ran an evaluation to compare Llama 3.1 70b with the previous version, and we see that there is 12% regression for this task:
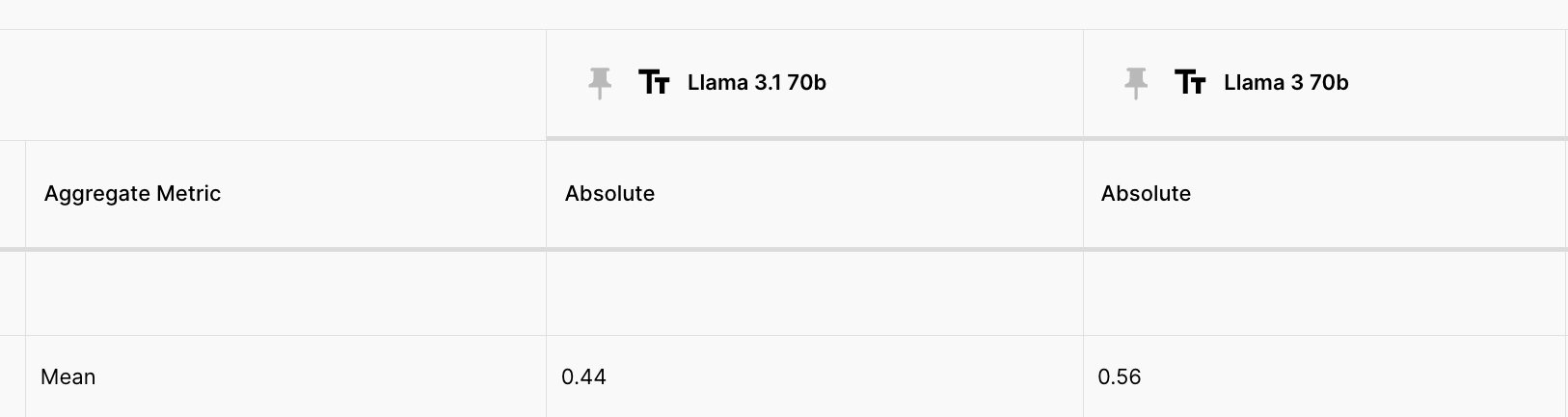
Key Takeaways:
Key Takeaways: GPT-4o mini has the highest accuracy for these reasoning questions (63%). Claude 3.5 Haiku has the lowest accuracy (38%). Llama 3.1 70B shows a 12% regression in reasoning tasks compared to its previous version.
Winner: GTP-4o has the highest accuracy for reasoning.
Summary
In this article we looked at standard benchmarks, we ran small scale experiments and looked at independent evaluations. Below is the summary of our findings.
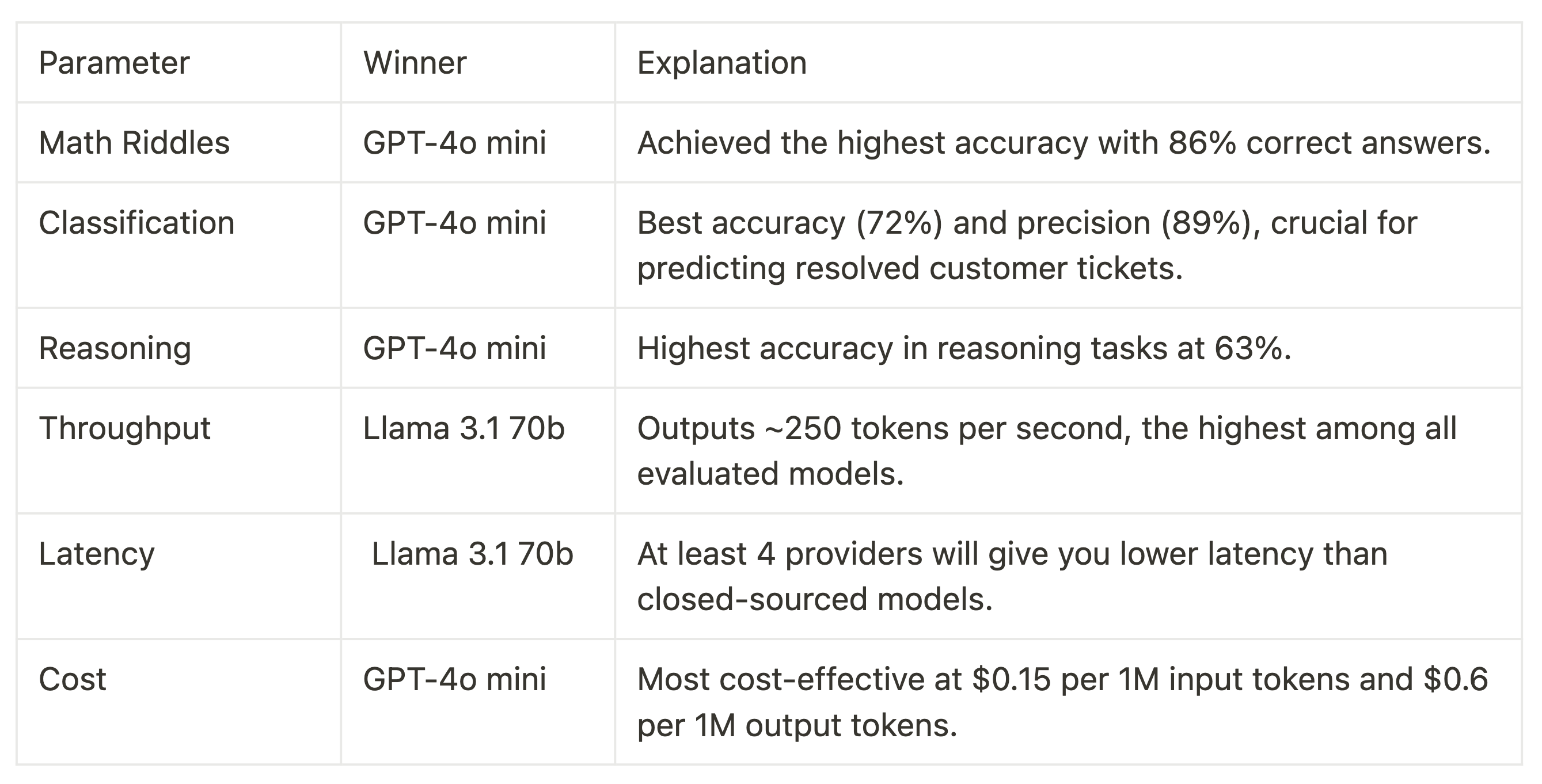
Conclusion
The evaluation highlights the growing power and relevance of open-source models like Llama 3.1 70b, which offer significant benefits in speed, efficiency, and cost. Meanwhile, proprietary models like GPT-4o mini excel in accuracy and precision, providing robust solutions for high-stakes tasks.
Choosing the right model depends on the application's needs. GPT-4o mini is ideal for tasks requiring high accuracy and detailed analysis, leading in cost and performance. For faster generation with acceptable performance, open-source models are a great option.
Source for throughput & latency: artificialanalysis.ai
Source for standard benchmarks: https://ai.meta.com/blog/meta-llama-3-1/






