


.webp)







.avif)
.avif)
.avif)



What Our Customers Say About Vellum
Loved by developers and product teams, Vellum is the trusted partner to help you build any LLM powered applications.
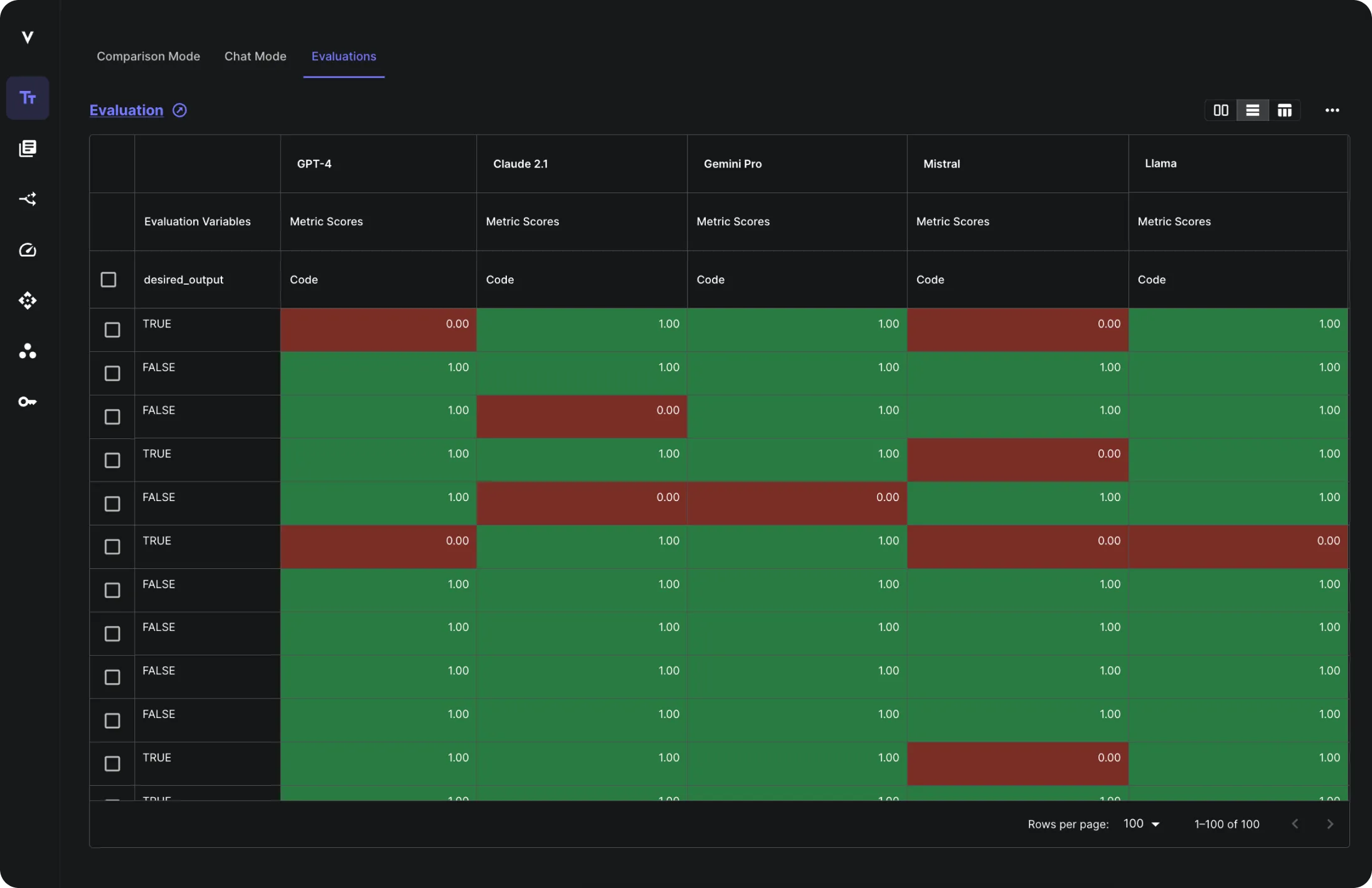
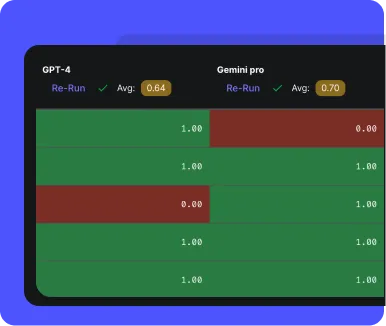
Vellum’s Evaluations framework makes it easy to measure the quality of your AI systems at scale. Confidently iterate on your AI systems and quickly determine whether they’re improving or regressing.
.avif)








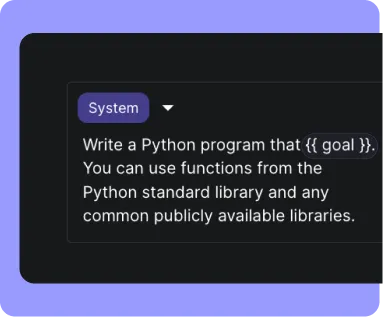
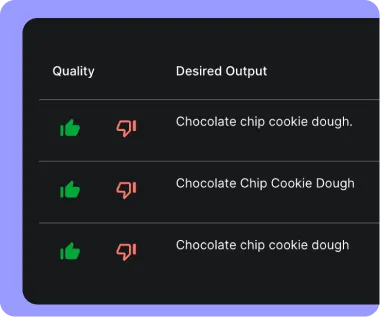
Empower your technical and non-technical teams to set up the safeguards they need to iterate on AI systems until they meet agreed-upon criteria. Accumulate a bank of hundreds of test cases and populate via UI, CSV, API, or add as you come across edge cases in the wild.


Vellum provides ready-to-use metrics for evaluating standalone prompts, RAG, and end-to-end AI systems, making it easy to start quantitatively testing any AI use-case.
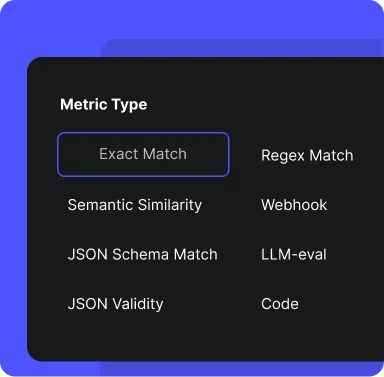
Advanced AI use-cases require advanced eval metrics. Fork off of Vellum’s default metrics or define your with Python or Typescript. For non-deterministic use-cases, leverage LLM as a Judge to have AI grade your AI.






Vellum helped us quickly evaluate prompt designs and workflows, saving us hours of development. This gave us the confidence to launch our virtual assistant in 14 U.S. markets.


We accelerated our 9-month timeline by 2x and achieved bulletproof accuracy with our virtual assistant. Vellum has been instrumental in making our data actionable and reliable.

AI development doesn’t end once you've defined your system. Learn how Vellum helps you manage the entire AI development lifecycle.
















.png)
.avif)

