The first generation of LLMs, like GPT-4 and PaLM, is mostly focused on text generation, which has been great for writing and coding.
But text doesn’t give the full picture of how humans understand the world—like knowing gravity makes things fall.
That’s stuff we know without being told, and language skips over it.
Text-trained LLMs can lack common sense. Adding more text to their training helps, but they can still get tripped up.
That's why there's a push for multimodal AI —one that can process images, sounds, and text.
Multimodality can broaden the LLMs' understanding, allowing them to tackle new tasks and offer unique experiences for end users.
But which models are available and how can you access them?
And what exactly can you build with them?
We'll answer all these questions and more in this blog post, so keep reading!
What is Multimodal AI?
Multimodality in AI refers to the ability of models to understand and interpret different types of data simultaneously. This can include text, images, video, and audio.
This is a significant leap from traditional models like GPT-4 that typically focus on a single type of data.
Imagine an AI that can summarize restaurant reviews, look at food pictures to see if the food is tasty, and listen to a video to tell you if the place has a nice vibe to it.
This is the power of multimodal LLMs – it processes and understands different types of data much like a human would.
Benefits of Multimodal AI
Multimodal AI models are designed to mimic human cognition.
When you’re driving for example, you use your eyes to see where you’re going, your ears to hear if there’s anything coming your way like cars or people talking, and your sense of touch to feel the movement.
Just as we use multiple senses to perceive and interact with the world, these models can use multiple data types to understand and generate accurate and nuanced responses to solve new tasks much faster.
For example: Multimodal AI can be used for better diagnosis by analyzing a mix of medical imaging data, textual reports, and lab results. Imagine the impact this might have on radiologist productivity and patients.
And there are more tasks that Multimodal AI can help with.
Multimodal AI tasks
Multimodal AI can handle a wide range of tasks. Here are a few examples:
Visual Question Answering: Answering questions about images Image captioning: Generating a descriptive caption for an image Sentiment analysis: Analyzing text, image, audio data to determine sentiment Content recommendation: Using user behavior and content data to recommend relevant content Optical Character Recognition (OCR): translating words from images, extracting other characters from images Math OCR: Solving math problems that have visual representation
Although there are a few hard challenges to solve to achieve great multimodal AI capabilities, there are 3 multimodal LLM models that are making progress and working pretty well right now.
We cover them in the next section.
Multimodal Models: How to Access and Use Them
There are several multimodal models available today, and here’s how you can access and use each of them.
GPT4-V by OpenAI
GPT4-V or “ GPT-4 Turbo with Vision ” is a model that can accept images as inputs in the Chat Completions API, enabling use cases such as generating captions, analyzing real world images in detail, and reading documents with figures.
The knowledge cutoff is April 2023, and it accepts up to 128,000 input tokens, and can return a maximum of 4,096 output tokens.
Developers can access this model by using gpt-4-vision-preview in the API. OpenAI will soon roll out vision support to the main GPT-4 Turbo model as part of its stable release.
This is currently the only multi-modal model available for commercial use. So, pricing will depend on the input image size. For instance, passing an image with 1080×1080 pixels to GPT-4 Turbo will cost $0.00765. And for text it will cost $0.01 / 1K tokens for input, and $0.03 / 1K tokens for output.
GPT4-V Performance & Limitations
First impressions from this model show that GPT4-V does well at various general image questions and demonstrated awareness of context. It can also create code for a website using a napkin drawing:
This is incredible how people use GPT-4 with Vision. pic.twitter.com/1O3AW7DJDr — Hushen Savani (@hushensavani) September 27, 2023
From the GPT-4 system card we can see that the model has it’s limitations such as:
Missing text or characters in an image Missing mathematical symbols Being unable to recognize spatial locations and colors
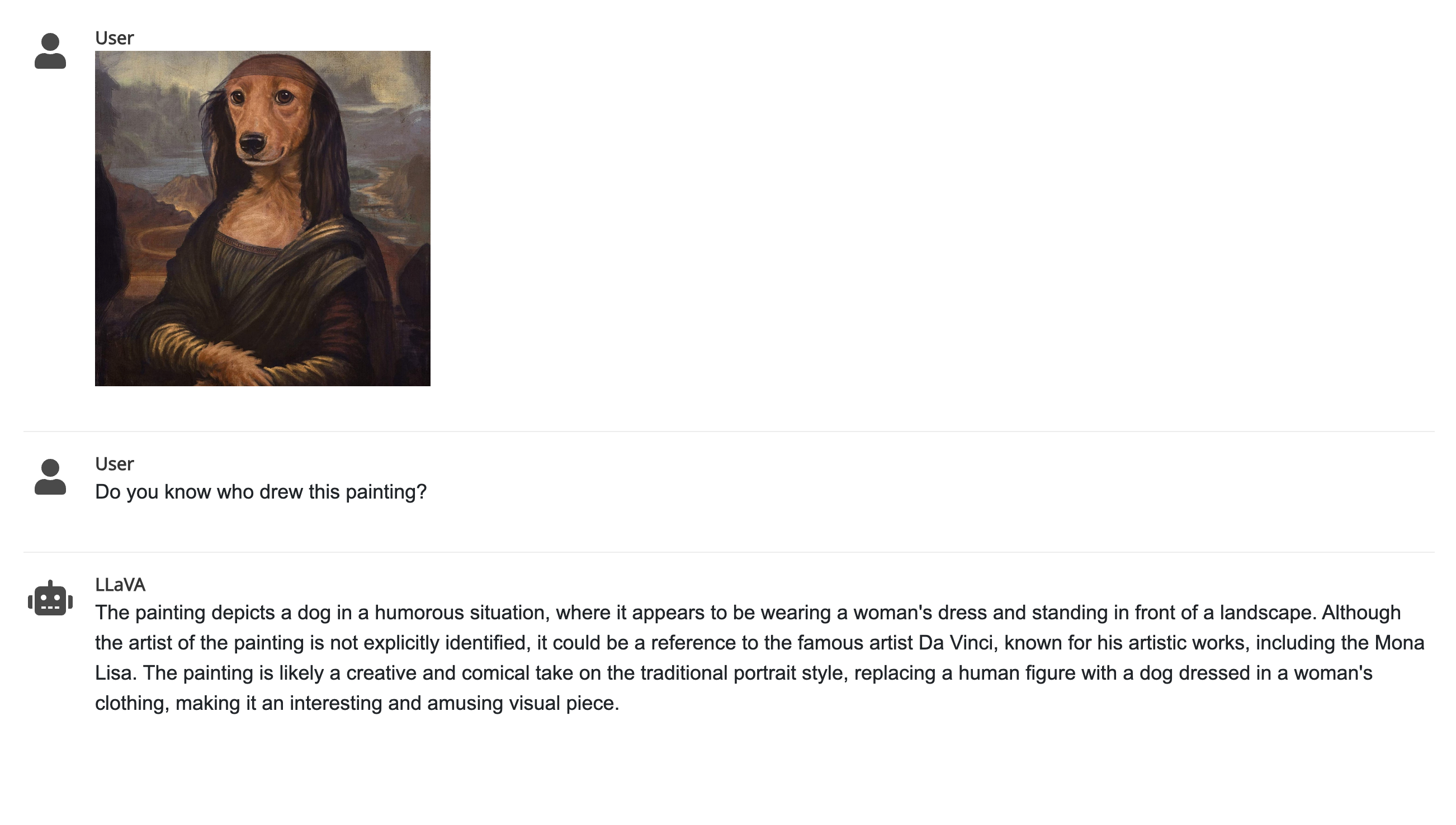
LLava 1.5
LLaVa 1.5 was released by a team of researchers, and like GPT-4V, can answer questions about images. What’s interesting about this model is that it’s easy to get it running on consumer-level hardware (GPU with less than 8GB of VRAM) and it set a new state-of-the-art accuracy on Science QA.
You can try LLava 1.5 on this demo page . They also released the data , code and model , but can’t be used for commercial purposes.
LLava 1.5 performance and limitations
This model can easily locate an object in a photo, explain the context of the image, can explain memes, but it can’t reliably recognize text from an image.
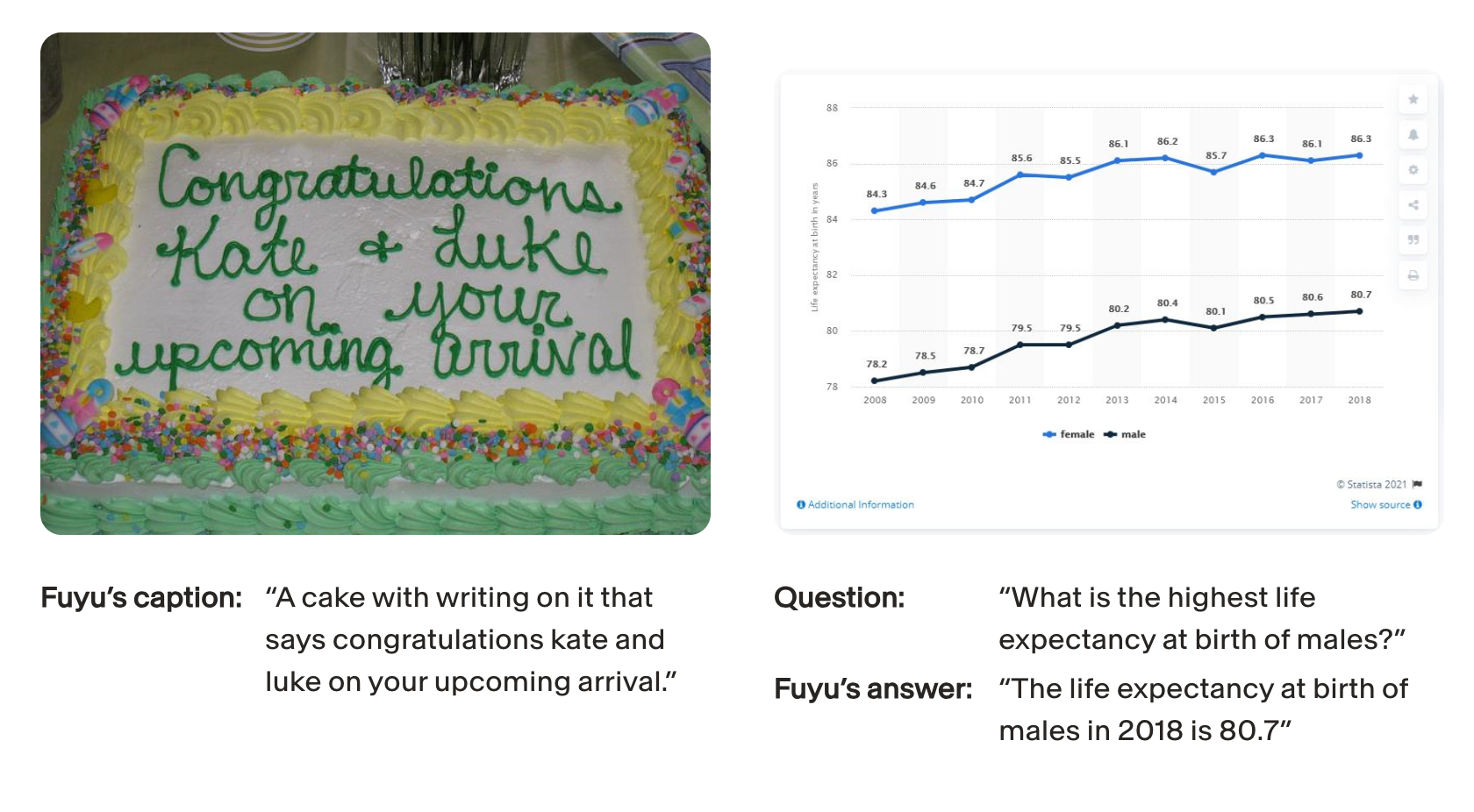
Fuyu-8B by Adept
Fuyu-8B is an open-source multimodal model by Adept. It understands “knowledge worker” data such as charts, graphs and screens, enabling it to manipulate — and reason over — this data.
The base model is available on HuggingFace , and it’s expected to be finetuned for specific use cases like verbose captioning or multimodal chat. The model responds well to few-shotting and fine-tuning for a variety of use-cases. The model is intended for research purposes only.
Fuyu-8b performance and limitations
This model can:
locate very specific elements on a screen; extract details from software’s UI; answer questions about charts/diagrams;
However the released model is still new, and there are no moderation mechanisms or prompt injection guardrails. Also it can’t generate faces and people properly.
What You Can Build with Multimodal AI models
The possibilities with multimodal AI are endless. You can build applications that offer a more comprehensive understanding of user input.
Here are two real-life applications that you can build and improve using Multimodal LLM models:
Smarter AI Chatbots
Imagine how much more powerful AI chatbots can become if they can handle more than just text.
You can let users show or tell your app their problems with a photo or voice message. The app finds matching images, figures out what's wrong, and talks them through a fix.
For example, let’s imagine that you're crafting a "Home Helper" chatbot app for DIY repairs.
If a person is stuck under a sink and wants to use your app to figure out a broken pipe, they might do it faster by taking a photo and/or verbally explaining what happened. The "Home Helper" chatbot would then analyze the context of the photo and verbally guide them through the repair process step by step, so they don't have to move or read a manual.
UX/UI feedback app
Another interesting example is an app equipped with AI that can capture a snapshot of your website or application. This AI would then scrutinize the layout, design, and overall user experience of the page.
It doesn't stop there; it could also evaluate the written content, offering insights on how to enhance the text for clarity and impact.
Want to use Multimodal AI for your app?
As you can see, there are many tasks that can be improved by using multimodal AI.
If you want to get tailored advice on your use-case, and want to streamline and test these new multimodal capabilities, Vellum can help.
Our platform can help you prototype, choose the best model for the job, then push to production and monitor the results. If you want to get a demo, request it here , or contact us on support@vellum.ai .