The Llama 3.1 405B model, with its 405 billion parameters, offers exceptional capabilities but requires substantial computational resources.
Running this model effectively requires high-performance hardware, including multiple GPUs with extensive VRAM.
SambaNova addresses these computational demands through its SN40L Reconfigurable Dataflow Unit (RDU) , a processor specifically designed for AI workloads. The SN40L features a three-tier memory system comprising on-chip distributed SRAM, on-package High Bandwidth Memory (HBM), and off-package DDR DRAM. This architecture enables the chip to handle models with up to 5 trillion parameters and sequence lengths exceeding 256,000 tokens on a single system node.
Today, they offer the Llama 3.1 405B model (comparable to GPT-4o) at speeds of up to 200 tokens per second—2x faster than GPT-4o.
With this integration, you can test the Llama 3.1 405B model, and evaluate how it compares with your current model selection.
How the native integration works
Starting today, you can enable the Llama 3.1 405b - Samba Nova model in your workspace.
To enable it, you only need to get your API key from your SambaNova profile, and add it as a Secret named SAMBANOVA on the “API keys” page:
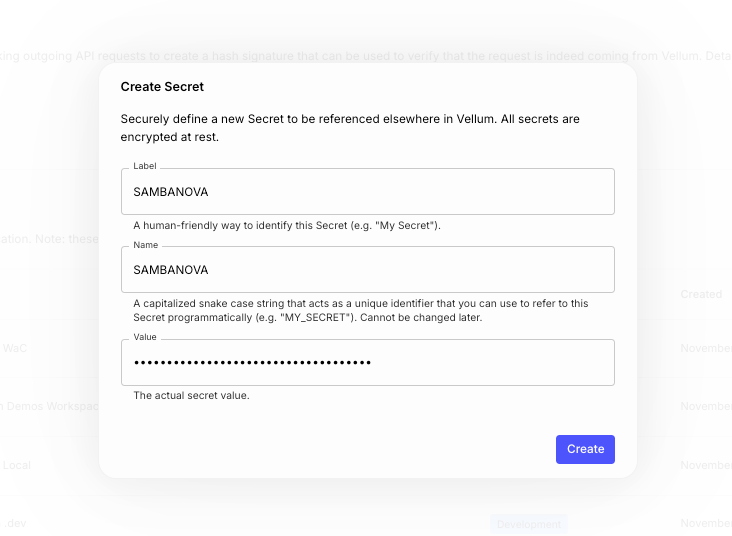
Then, you should enable the model from your workspace, by selecting the secret you just defined:
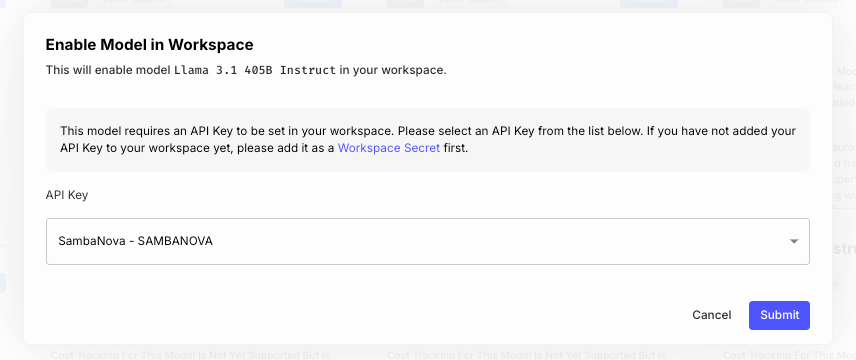
Then, in your prompts and workflow nodes, simply select the model you just enabled:
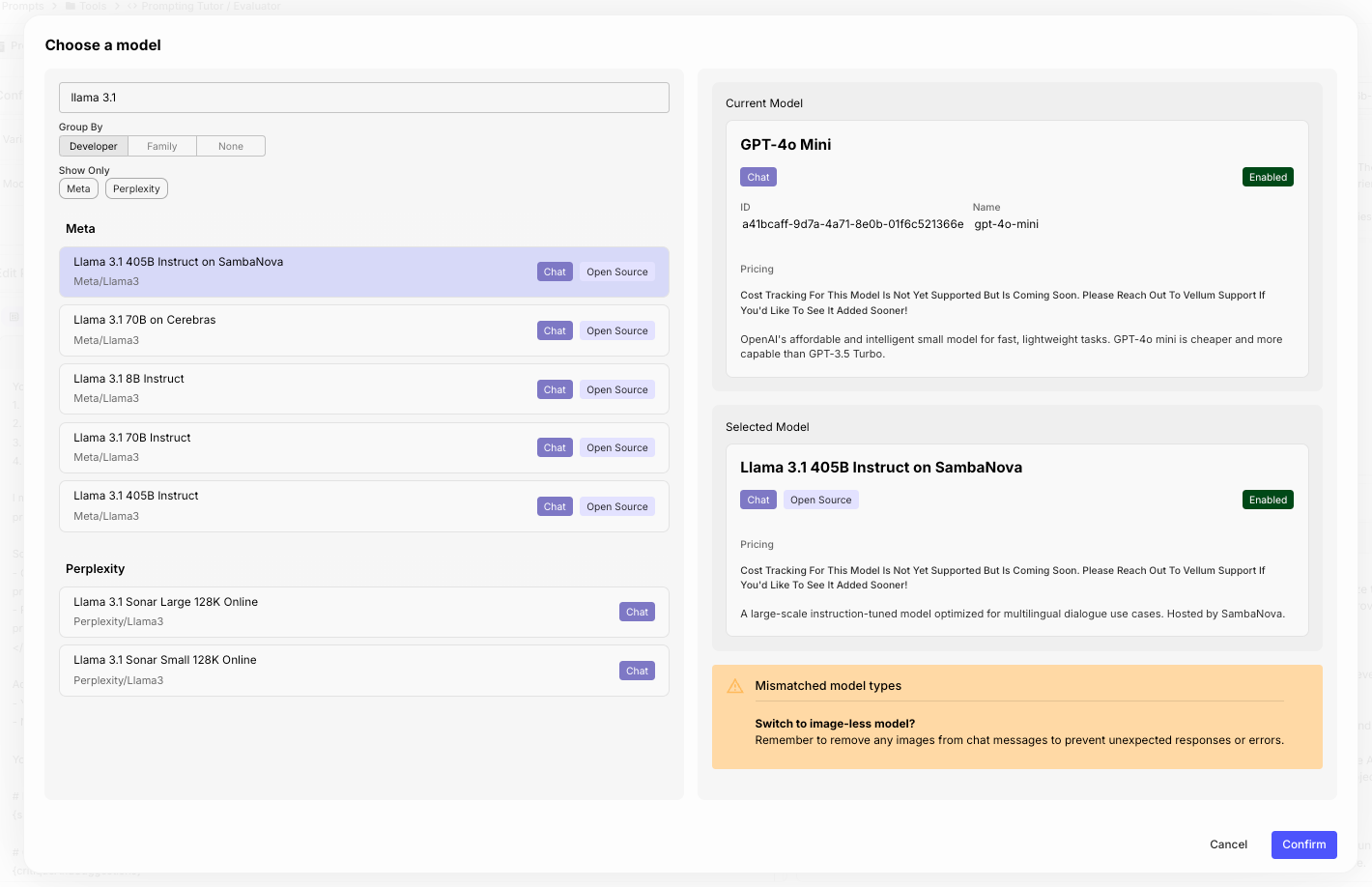
What do you get with SambaNova
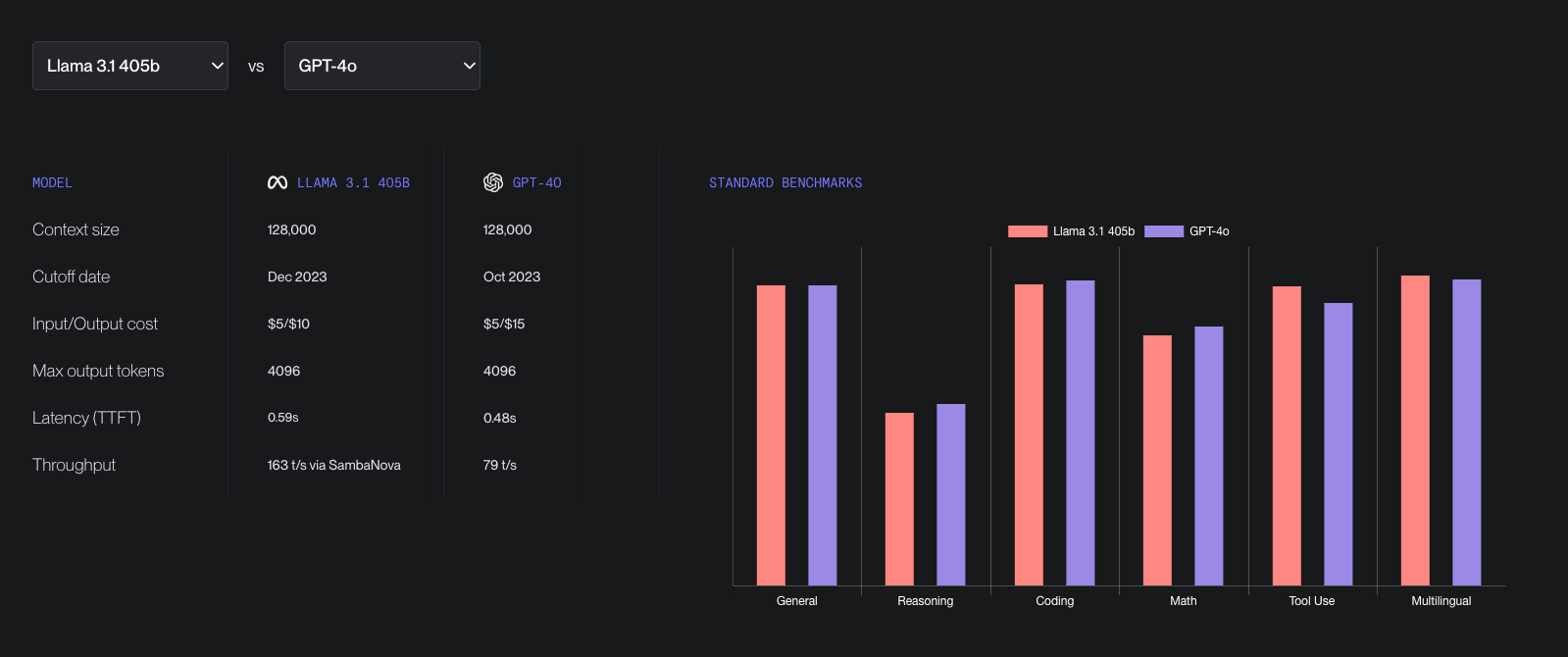
SambaNova's integration with Vellum brings key advantages for developers working with the Llama 3.1 405B model:
Fast Performance: SambaNova Cloud runs Llama 3.1 405B at 200 tokens per second, which is 2x faster than running GPT4o.
Lower output cost : SambaNova's picing is $5 for input tokens and $10 for output tokens, compared to GPT-4o’s $5 for input and $15 for output.
Accurate Outputs : SambaNova keeps the original 16-bit precision of the model, so you get reliable and accurate results without cutting corners. Check how the Llama 3.1 450b compares with other models in our LLM leaderboard .
Handles Complex Applications : The platform is designed to support demanding use cases like real-time workflows and multi-agent systems, making it flexible for a variety of projects.
If you want to test the inference speed with SambaNova — get in touch ! We provide the tooling & best practices for building and evaluating AI systems that you can trust in production.