TLDR;
We're excited to announce that Vellum now has a native integration with Cerebras - the fastest AI inference solution in the world, allowing customers to run 2,100 tokens per second for Llama3.1 70B(3x faster than the current best-in-market / that's 1 book per minute!), with flexible rate limits! This sets an industry record for inference speed, and starting October 24, 2024, Vellum users can benefit from this incredible performance boost to build faster, real-time AI applications.
As a development platform that enables companies around the world to build reliable AI systems with LLMs, we know that striking the right balance between accuracy, speed, and cost is a top priority for many companies today.
But, with the rise of more sophisticated AI applications—from traditional routing systems to more dynamic, agent-driven workflows—having fast response times is essential to handle the intricate logic involved.
Today, we’re excited to announce our native integration with Cerebras , the fastest AI inference solution that delivers 2,100 tokens/second for the Llama 3.1 70B model, using the original 16-bit weights released by Meta. This solution is 16x faster than any known GPU and 68x faster than hyperscale clouds, according to third-party benchmarks. Even more impressive, Cerebras Inference serves Llama 70B models over 8x faster than GPUs serve Llama 3B.
“Our customers are blown away with the results! Time to completion on Cerebras is hands down faster than any other inference provider and I’m excited to see the production applications we’ll power via the Cerebras inference platform. - Akash Sharma, CEO of Vellum
How the native integration works
All public models on Cerebras are now available to add to your workspace.
For example, to enable the Llama 70b model hosted on Cerebras into your workspace, you only need to get your API key from your Cerebras profile, and add it as a Secret named CEREBRAS on each of the model pages:
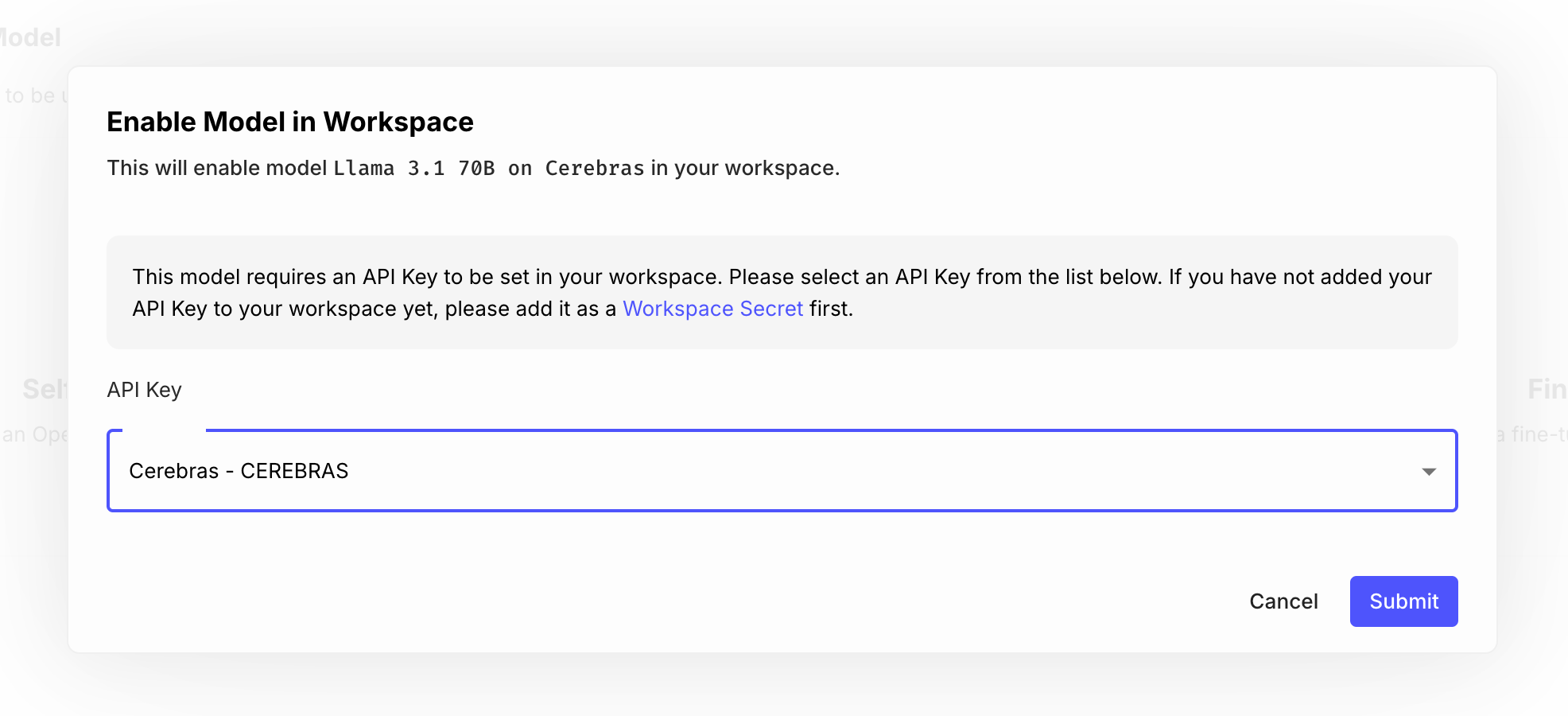
Then, in your prompts and workflow nodes, simply select the model you just enabled:
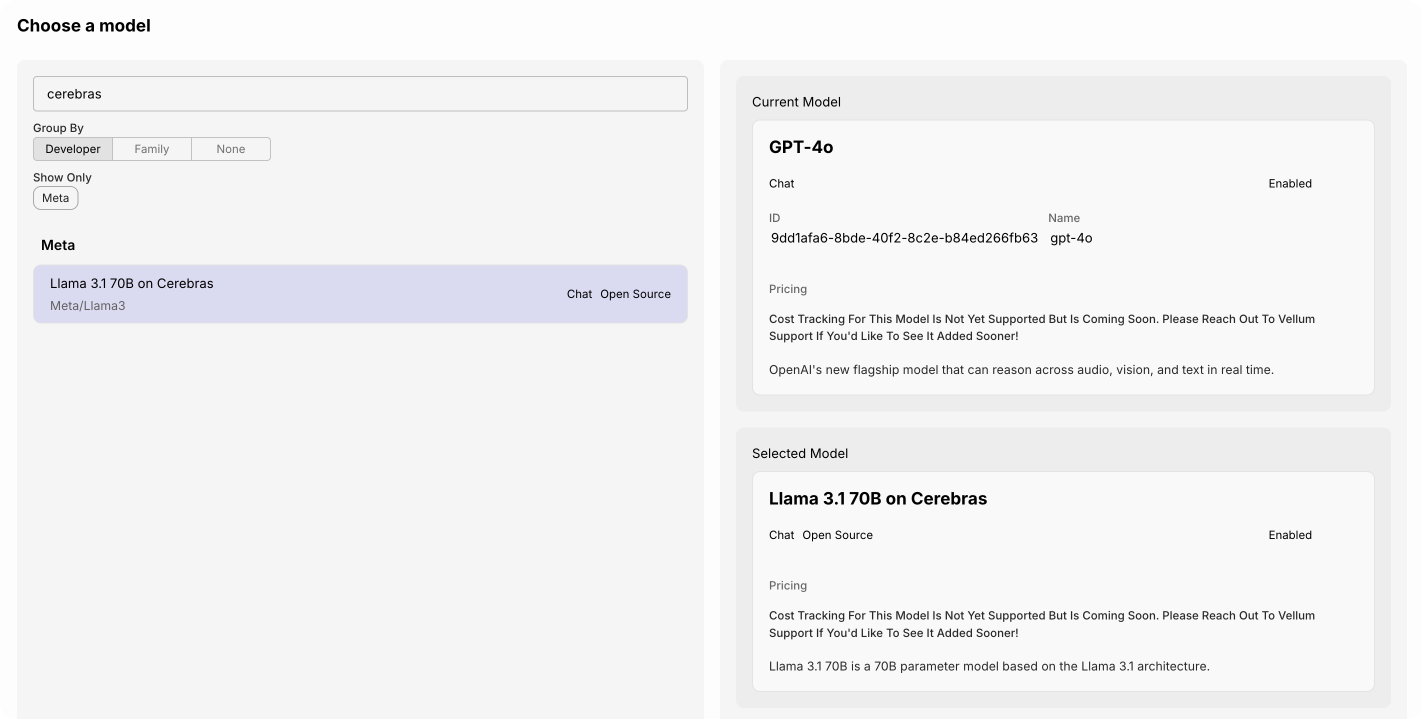
What do you get with Cerebras inference
The Cerebras inference solves the memory bandwidth bottleneck by building the largest chip in the world and storing the entire model on-chip without sacrificing weight precision. They currently support only Llama 70b, and you get the best model in terms of speed, accuracy and cost.
High speed

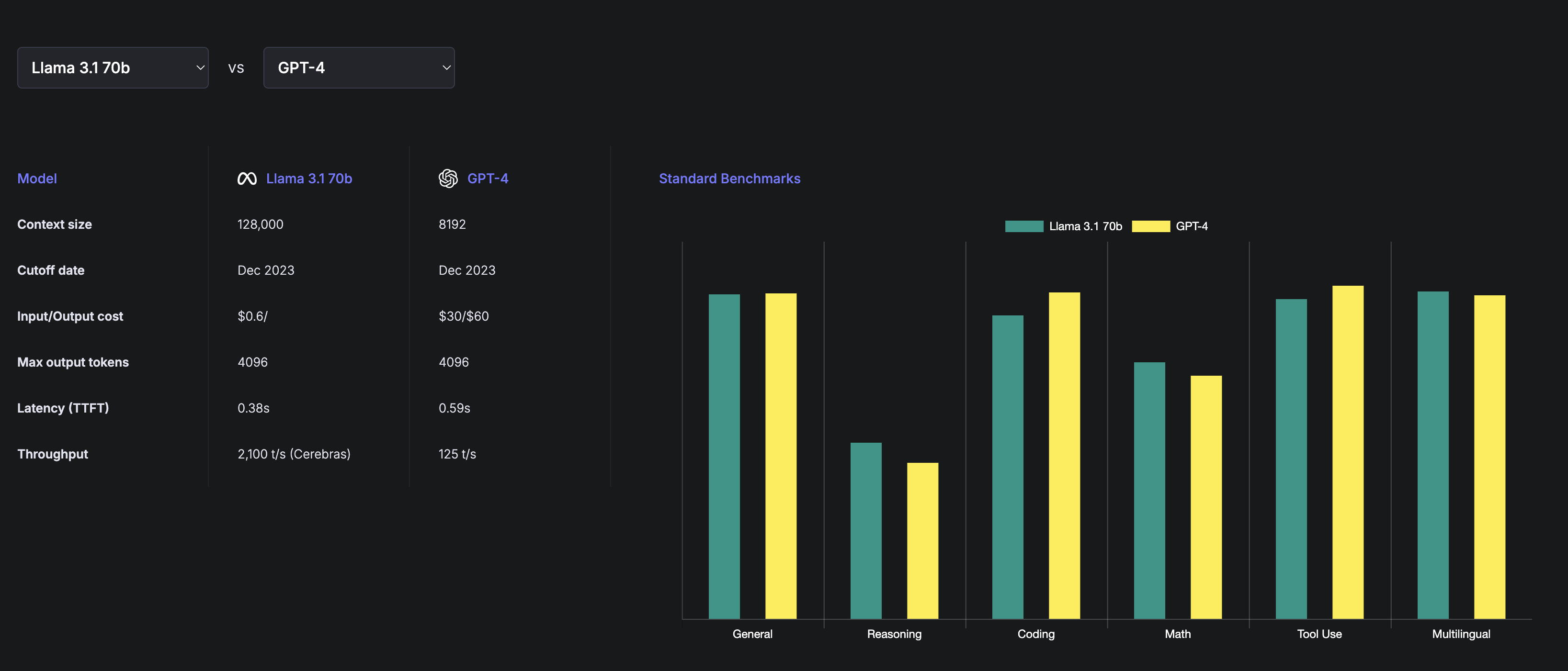
For Llama 3.1-70B , Cerebras generates instant responses at 2,100 tokens per second, which is is 16x faster than any known GPU solution and 68x faster than hyperscale clouds as measured by third-party benchmarking organization.
The most interesting part is that Cerebras Inference serves Llama 70B more than 8x faster than GPUs serve Llama 3B.
Highest accuracy
Regarding accuracy, Cerebras doesn’t reduce weight precision from 16-bit to 8-bit to overcome the memory bandwidth bottleneck. They use the original 16-bit weights released by Meta, ensuring the most accurate and reliable model output — Evaluations and third-party benchmarks show that 16-bit models can score up to 5% higher than their 8-bit counterparts.
The Llama 3.1 70b model is already climbing up the ranks in various fields like math, reasoning and and coding, and being able to run them 68 times faster is unlocking many new use-cases.
Lowest cost
Developers can easily access the Cerebras Inference API, which is fully compatible with theOpenAI Chat Completions API, making migration seamless with just a few lines of code.
Cerebras Inference offers three pricing tiers for its AI inference service: Free, Developer, and Enterprise:
Free : Offers API access and generous usage limits (1 million free tokens daily) Developer : Offers an API endpoint at a fraction of the cost of alternatives, with models priced at 10 cents and 60 cents per million tokens Enterprise: Offers provisioned throughput, production-grade service level agreements, fine-tuned models, and dedicated support.
If you want to test the inference speed with Cerebras — get in touch ! We provide the tooling & best practices for building and evaluating AI systems that you can trust in production.