
Anthropic just dropped Claude 3.7 Sonnet, and it’s a textbook case of second-mover advantage. With OpenAI’s o1 and DeepSeek’s R1 already setting the stage for reasoning models, Anthropic had time to analyze what worked and what didn’t—and it shows.
What’s most interesting is their shift in focus.
Instead of chasing standard benchmarks, they’ve trained this model for real business use cases. They’re doubling down on coding and developer tools—an area where they’ve had an edge from the start.
The response?
Developers are already building pokemon agents, recreating games — all happy vibes indeed
openai releases a model literally beats every existing benchmark, sith dark lord vibes, ASI timeline accelerated claude releases a model plays pokemon, happy vibes, everyone starts vibecoding — atlas (@creatine_cycle) February 24, 2025
Another standout feature is the ability to dynamically switch between standard and advanced reasoning. The API lets you control how many tokens the model spends on "thinking time," giving you full flexibility. So so smart Anthropic!
In this article we’ll compare the latest reasoning models (o1, o3-mini and DeepSeek R1) with the Claude 3.7 Sonnet model to understand how they compare on price, use-cases, and performance!
Results
In this analysis, We look at standard benchmarks, human-expert reviews, and conduct a set of our own small-scale experiments.
Here are our findings:
Pricing: Claude 3.7 Sonnet sits in the middle—cheaper than OpenAI’s o1 model but pricier than DeepSeek R1 and OpenAI’s O3-mini. However, its ability to adjust token usage on the fly adds significant value, making it the most flexible choice. Latency : It’s hard to pin down the exact latency with extended thinking for Claude 3.7 Sonnet, but being able to set token limits and control response time for a task is a solid advantage. This dual-mode approach means developers no longer need separate fast vs. smart models. You get configurable latency which is a huge deal not available to any other model at the moment. This is somewhat similar to OpenAI’s o3-mini model that has pre-built low, middle, and high reasoning modes , but there is no direct control on ‘thinking token spend’. Standard Benchmarks: Claude 3.7 Sonnet is strong in reasoning (GPQA: 78.2% / 84.8%), multilingual Q&A (MMLU: 86.1%), and coding (SWE-bench: 62.3% / 70.3%), making it a solid choice for businesses and developers. Anthropic really wanted to solve for real business use-cases, than math for example — which is still not a very frequent use-case for production-grade AI solutions. Math reasoning: Our small evaluations backed Anthropic’s claim that Claude 3.7 Sonnet struggles with math reasoning. Surprisingly, OpenAI’s o1 didn’t perform much better. Even o3-mini, which should’ve done better, only got 27/50 correct answers, barely ahead of DeepSeek R1’s 29/50. None of them are reliable for real math problems. Puzzle Solving: Claude 3.7 Sonnet led with 21/28 correct answers, followed by DeepSeek R1 with 18/28, while OpenAI’s models struggled. It looks like OpenAI and Gemini 2.0 Flash are still overfitting to their training data, while Anthropic and DeepSeek might be figuring out how to make models that actually think .
Methodology
In the next two sections we will cover three analysis:
Latency & Cost comparison Standard benchmark comparison (example: what is the reported performance for math tasks between Claude 3.7 Sonnet vs OpenAI o1?) Independent evaluation experiments (math equations and puzzles)
Evaluations with Vellum
To conduct these evaluations, we used Vellum’s AI development platform , where we:
Configured all 0-shot prompt variations for both models using the LLM Playground. Built the evaluation dataset & configured our evaluation experiment using the Evaluation Suite in Vellum. We used an LLM-as-a-judge to analyze generated answers to correct responses from our benchmark dataset for the math/reasoning problems.
We then compiled and presented the findings using the Evaluation Reports generated at the end of each evaluation run.
You can skip to the section that interests you most using the "Table of Contents" panel on the left or scroll down to explore the full comparison between OpenAI o1, o3-mini Claude 3.7 Sonnet, and DeepSeek R1.
Pricing
Claude 3.7 Sonnet keeps the same pricing as earlier models— $3/M input tokens, $15/M output tokens ($0.003 and $0.015 per 1K). This applies to both standard and extended thinking modes, with thinking tokens counted as output. No extra surcharge for reasoning.
Compared to competitors, Claude 3.7 is much cheaper than OpenAI’s o1 ($15/M in, $60/M out) but more expensive than o3-mini, which costs $1.10/M in, $4.40/M out. Meanwhile, DeepSeek R1 undercuts them all at $0.14/M in, $0.55/M out, though with trade-offs. Claude 3.7 sits in the middle— cheaper than top-tier closed models, but pricier than open alternatives

For anyone looking to test Claude 3.7 Sonnet: the token budget control is the key feature to master. Being able to specify exactly how much "thinking" happens (50-128K tokens) creates entirely new optimization opportunities.👇🏻
Latency
Claude 3.7 introduces a hybrid reasoning architecture that can trade off latency for better answers on demand. In standard mode, it’s extremely fast – Anthropic cites ~200 ms latency for quick responses (presumably time to first token or for short answers). The average latency according to a independently run evaluation sits at 1.16s.

In extended thinking mode, the model can take up to 15 seconds ( reportedly ) for deeper reasoning, during which it internally “thinks” through complex tasks. It’s hard to pin down the exact latency with extended thinking, but being able to set token limits and control response time for a task is a solid advantage.
This dual-mode approach means developers no longer need separate fast vs. smart models. You get configurable latency which is a huge deal not available to any other model at the moment. This is somewhat similar to OpenAI’s o3-mini model that has pre-built low, middle, and high reasoning modes , but no direct control on ‘thinking token spend’.
More tokens for thinking will add more latency, but will definitely lead to better performance for harder tasks. As shown in the AIME 2024 performance graph below, accuracy improves as more tokens are allocated, following a logarithmic trend.
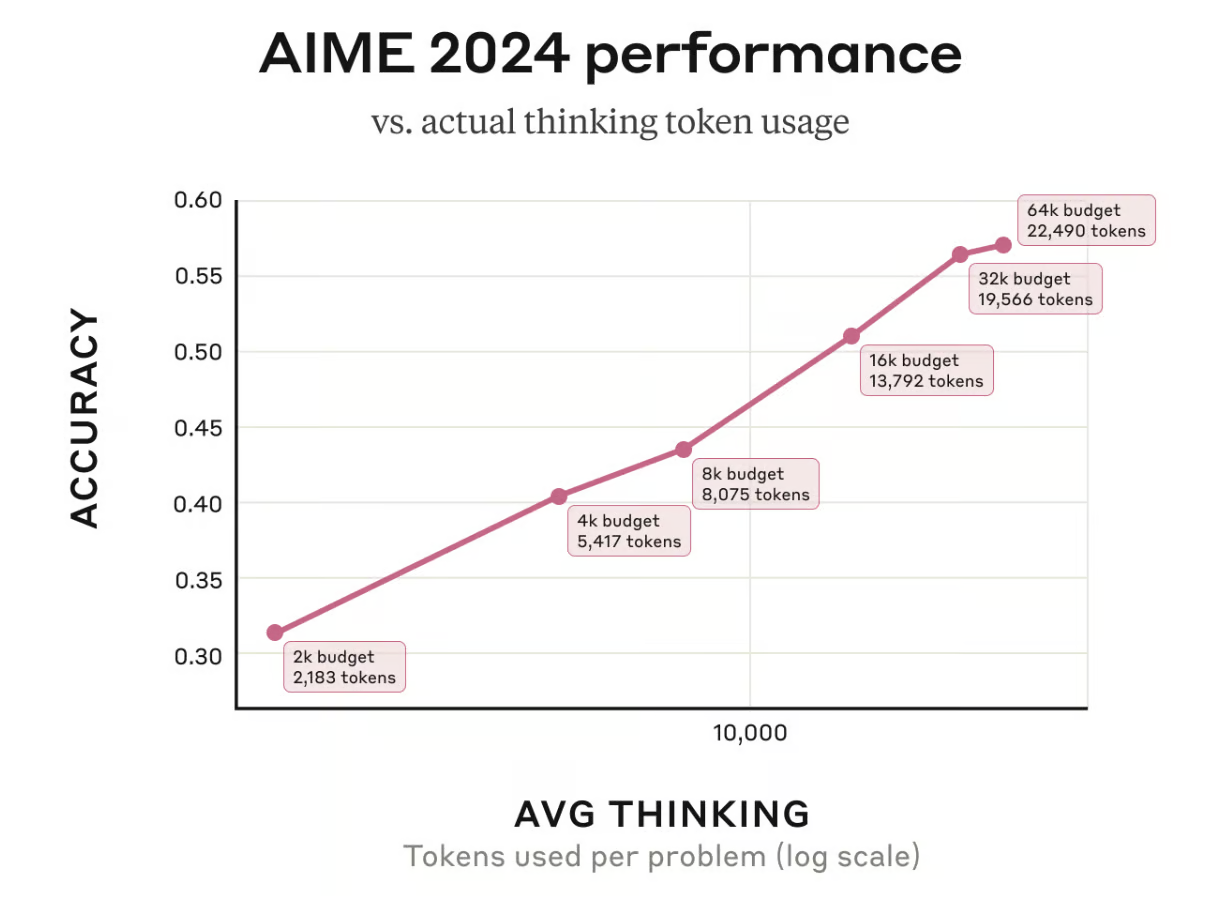
Benchmarks
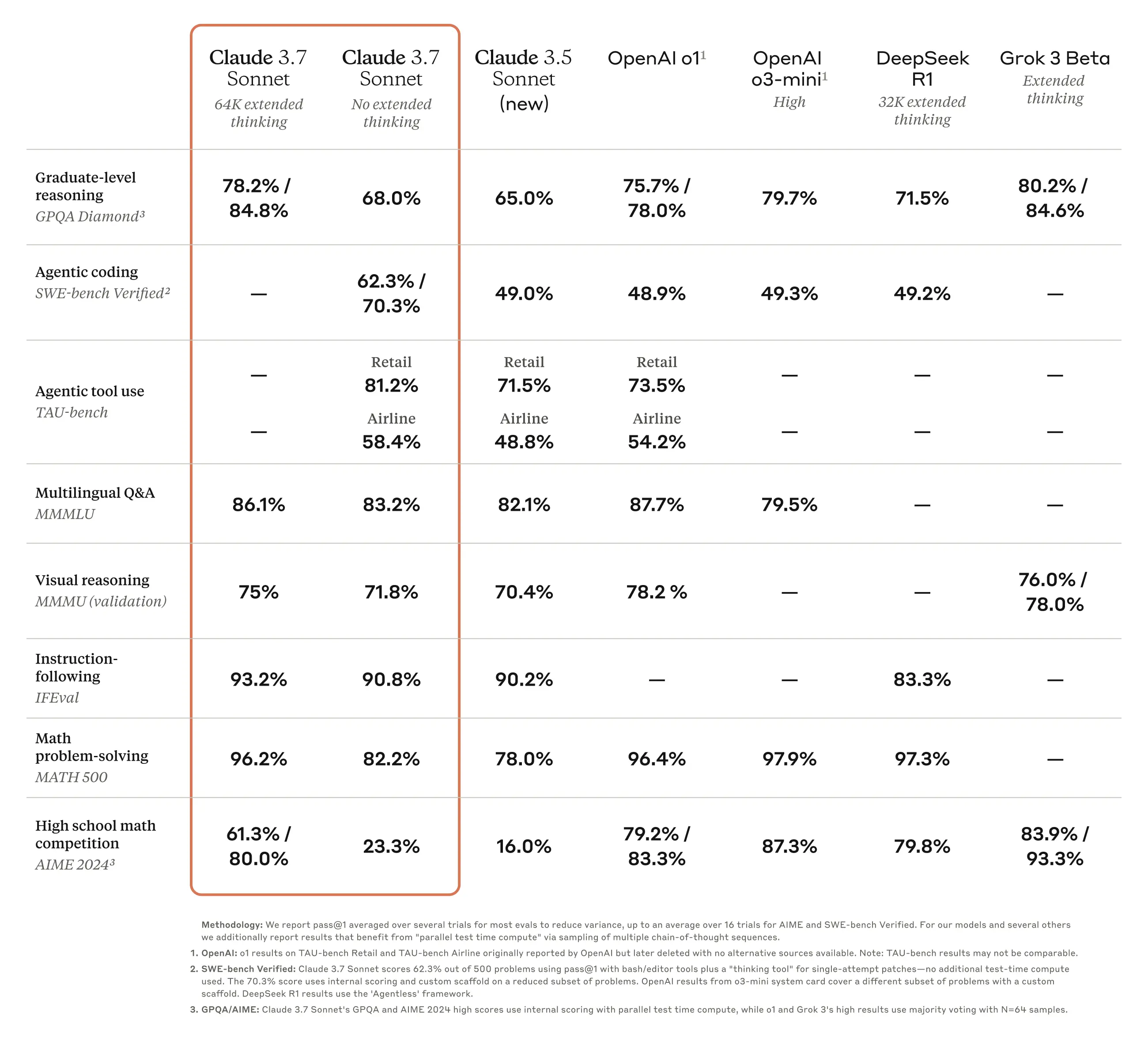
Claude 3.7 Sonnet is a well-rounded model, excelling in graduate-level reasoning (GPQA Diamond: 78.2% / 84.8%), multilingual Q&A (MMLU: 86.1%), and instruction following (IFEval: 93.2%), making it a strong choice for business and developer use cases.
Its agentic coding (SWE-bench: 62.3% / 70.3%) and tool use (TAU-bench: 81.2%) reinforce its practical strengths.
While it lags in high school math competition scores (AIME: 61.3% / 80.0%), it prioritizes real-world performance over leaderboard optimization—staying true to Anthropic’s focus on usable AI.
It’s also interesting to see that the Claude 3.7 Sonnet without extended thinking is showcasing great results on all these benchmarks.
Independent Evals
Task 1: Math
For this task, we’ll compare the models on how well they solve some of the hardest SAT math questions . This is the 0-shot prompt that we used for both models:
You are a helpful assistant who is the best at solving math equations. You must output only the answer, without explanations. Here’s the <question>
We then ran all 50 math questions and here’s what we got:
Click to Interact
×
From this table we can notice that:
All models are particularly bad at solving math problems DeepSeek R1 guessed 29/50 answers right (58%), and the O3-mini (High) got 27/50 answers right. Those two did best on this eval but it’s still a coin toss — we don’t see any meaningful performance at these tasks from these models still. Claude 3.7 Sonnet and OpenAI o1 were the worst, and similarly bad . We proved that Claude 3.7 Sonnet is really not good at math, as they actually stated in the announcement. However, we expected better performance from OpenAI o1 and o3-mini.
Task 2: Puzzles
We tested OpenAI-o1, DeepSeek-R1, Claude 3.7 Sonnet, and OpenAI o3-mini on 28 well-known puzzles. For this evaluation, we changed some portion of the puzzles, and made them trivial. We wanted to see if the models still overfit on training data or will adapt to new contexts.
For example, we modified the Monty Hall problem:
Suppose you're on a game show, and you're given the choice of three doors: Behind one door is a gold bar; behind the others, rotten vegetables. You pick a door, say No. 1, and the host asks you, 'Do you want to pick door No. 2 instead?' What choice of door now gives you the biggest advantage?
In the original Monty Hall problem, the host reveals an extra door. In this case, it does not, and since there is no additional information provided, your odds remain the same.
The correct answer here is: “It is not an advantage to switch. It makes no difference if I switch or not because no additional material information has been provided since the initial choice.”
Most models had trouble working with the new context, but Claude 3.7 Sonnet performed noticeably better:
Click to Interact
×
From this evaluation we can clearly see that:
Claude 3.7 Sonnet got 21/28 answers right, hitting 75% accuracy. DeepSeek R1 followed with 18/28 correct guesses and 64% accuracy. For the rest of the models, getting the right answer was basically a coin flip. OpenAI’s models and Gemini 2.0 Flash Thinking still seem to overfit, likely optimizing too much for benchmark data. Meanwhile, Anthropic and DeepSeek may have figured out a different approach—improving their models without leaning too heavily on benchmarks and training data.
Evaluate with Vellum
At Vellum, we built our evaluation using our own AI development platform —the same tooling teams use to compare, test, and optimize LLM-powered features.
With the LLM Playground , we configured controlled zero-shot prompts across models. The Evaluation Suite helped us automate grading, ensuring a fair and structured comparison. And with Evaluation Reports , we could quickly surface insights into where each model excelled (or struggled).
If you need to run large-scale LLM experiments — book a demo with one of our experts here.
Conclusion
Claude 3.7 Sonnet proves that Anthropic is playing the long game—prioritizing real-world usability over leaderboard flexing. The model isn’t flawless (math is still a weak spot), but its ability to dynamically adjust reasoning depth and token spend is a genuine step forward.
Our evaluations showed it leading in puzzle-solving and reasoning, while OpenAI’s models still seem to overfit on training data. DeepSeek R1 remains a strong contender, especially given its pricing, but lacks the same flexibility.
For developers and businesses, the takeaway is clear: if you need fine-tuned control over performance and cost, Claude 3.7 Sonnet is one to watch.




