
Meta just announced their new Llama 3.3 70B model, designed to perform similarly to the larger but slower Llama 3.1 405B.
With this release, we decided to run a comparison against GPT-4o, OpenAI's most powerful model. We’re skipping OpenAI's O1 model for now since it's built differently and targets specific use cases. If you’re curious about how O1 stacks up against GPT-4o, check out this detailed breakdown .
This evaluation reveals that while proprietary models like GPT-4o excel in certain tasks, open-source models like Llama 3.3 70B remain highly competitive—especially when considering factors like cost, customization, and deployment flexibility.
Let’s get specific!
Results
We compared these models across three key tasks: reasoning, math, and classification. Along the way, we explored the latest benchmarks, evaluated the input and output token costs, assess latency and throughput, and provide guidance on the best model choice for your needs.
From this analysis we learn that:
Price & Speed: Groq is the most optimal inference provider choice for Llama 3.3 70b if you’re looking for balance between cost, speed and latency. If you only care about pricing, the cheapest offer is via Deepinfra ($0.23/$0.40 input/output cost per 1M tokens). Math Problems: Both GPT-4o and GPT-4o Mini outperformed Llama 3.3 70b and the 405b model. GPT-4o had the highest score (55% accuracy). Reasoning tasks: In our reasoning tests, GPT-4o, Llama 405B, and GPT-4o Mini all performed equally well at 69%, while the newer Llama 3.3 70B only achieved 44%. This was surprising since Meta claimed Llama 3.3 70B would match the 405B model, but our results showed otherwise. Classifying customer tickets : GPT-4o and Llama 3.3 70b have comparable results, and both can be used to classify customer support tickets using few-shot prompts. Standard benchmarks: Based on standard benchmark reports, Llama 3.3 70b excels in coding, tool use (agentic capabilities), and multilingual support. These are critical areas we believe every business should assess for accuracy and relevance.
💡If you're looking to evaluate the Llama 3.3 70b on your own use-cases — Vellum can help. Book a call with one of our AI experts to set up your evaluation.
Methodology
The main focus on this analysis is to compare Llama 3.3 70b and GPT-4o ( gpt-4o 2024-08-06). We look at standard benchmarks, human-expert reviews, and conduct a set of our own small-scale experiments.
Analysis overview
In the next two sections we will go over:
Latency and Cost comparison Standard benchmark comparison (example: what is the reported performance for math tasks between GPT-4o vs Llama 3.3 70b?) Independent evaluation experiments: Math equations and reasoning problems with 0-short prompts, and Classification problems with 4-shot prompts (we added 4 resolved customer tickets in the prompt).
Evaluations with Vellum
To conduct these evaluations, we used Vellum’s AI development platform , where we:
Configured all 0-shot prompt variations for both models using the LLM Playground. Built the evaluation test bank & configured our evaluation experiment using the Evaluation Suite in Vellum. We used an LLM-as-a-judge to compare generated answers to correct responses from our benchmark dataset for the math/reasoning problems. For classification tasks, we applied our built-in "Exact Match" metric.
We then compiled and presented the findings using the Evaluation Reports generated at the end of each evaluation run.
You can skip to the section that interests you most using the "Table of Contents" panel on the left or scroll down to explore the full comparison between Llama 3.3 70b and GPT-4o.
Latency, Cost, Throughput
Today, there are a few inference providers that offer the latest Llama 3.3 70b model. If you want to choose the best provider, you should look at the cost, latency and throughput that you’ll get.
Latency (Seconds to first token received)
The provider with the lowest latency is Groq which serves this model with an average latency of 0.26s. We define latency as seconds to first token received, and this is very important if you have real-time AI features in production.
There are other providers who can provide comparable latency, and in comparison to GPT-4o’s latency of 0.67s, all of those are more favorable.

Pricing for input and output tokens
Price wise, the cheapest option is DeepInfra at $0.23/ 1m tokens, and $0,4/ 1m tokens. If we take into account that Deepinfra has the second best option for latency, this is definitely a good option.
However, there runner ups in this comparison — Hyperbolic, Groq, Together AI — still offer much lower latency numbers when compared to GPT-4o. Even the most expensive Llama 3.3 70b provider (Together AI) is ~2.84x cheaper for input tokens, and ~6x cheaper for output tokens.
However, the cheapest input cost for Llama (via Deepinfra) is 10x cheaper than GPT4o’s, and the cheapest output cost is 25x cheaper than GPT4o’s — which is definitely enticing.

Throughput (Output speed)
The provider with the fastest throughput is Groq , which serves this model at 275 tokens/second. This is ~3x faster than GPT-4o.
There two other options are Fireworks and Together.ai who have solid offerings as well. Sadly, Deepinfra has very low throughput which doesn’t make it a favorable option if you care about speed.

From all these graphs we can conclude that Groq is a favorable option if you care about all parameters of this analysis (cost, latency, speed). If you don’t care about speed of output or latency, you can just choose the cheapest option from the list which is Deepinfra .
Now, while this is important, we also need to look at the benchmarks and how the Llama 3.3 70b compares to GPT4o in performance — across different tasks.
To compare the performance, first we’ll look at standard benchmarks
Standard Benchmarks
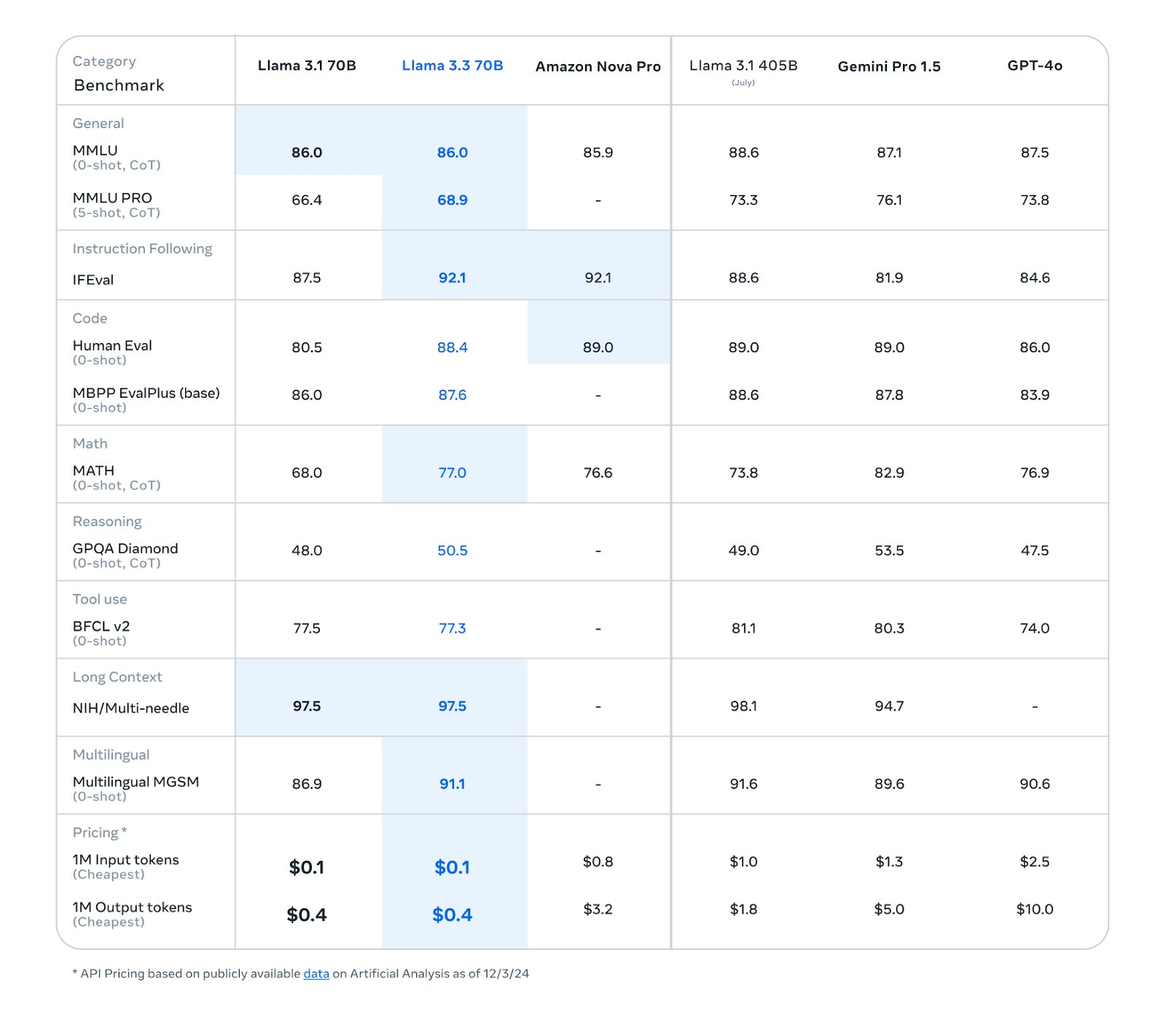
The Meta team has done their own benchmark evaluation and how it compares to the GPT-4o model:
In MMLU (general reasoning) GPT-4o is still outpacing Llama 3.3 70b; In Human Eval (coding) seems like Llama 3.3 70b is better than GPT-4o; In GPQA Diamond (Math reasoning) the Llama model has better performance as well; In MATH, both models are performing similarly In BFCL (Tool use/Agentic capabilities) the Llama model is showing better performance. In MGSM (Multilingual capabilities) the Llama model is slightly stronger.
Standard benchmarks are useful, but we wanted to perform individual small evaluation experiments, to analyze how these models compare on real-world tasks.
Independent evaluation
Math Equation
For this task, we’ll compare the GPT-4o and the Llama 3.3 70b model on how well they solve some of the hardest SAT math questions . This is the 0-shot prompt that we used for both models:
You are a helpful assistant who is the best at solving math equations. You must output only the answer, without explanations. Here’s the <question>
We then ran all 13 math questions and here’s what we got:
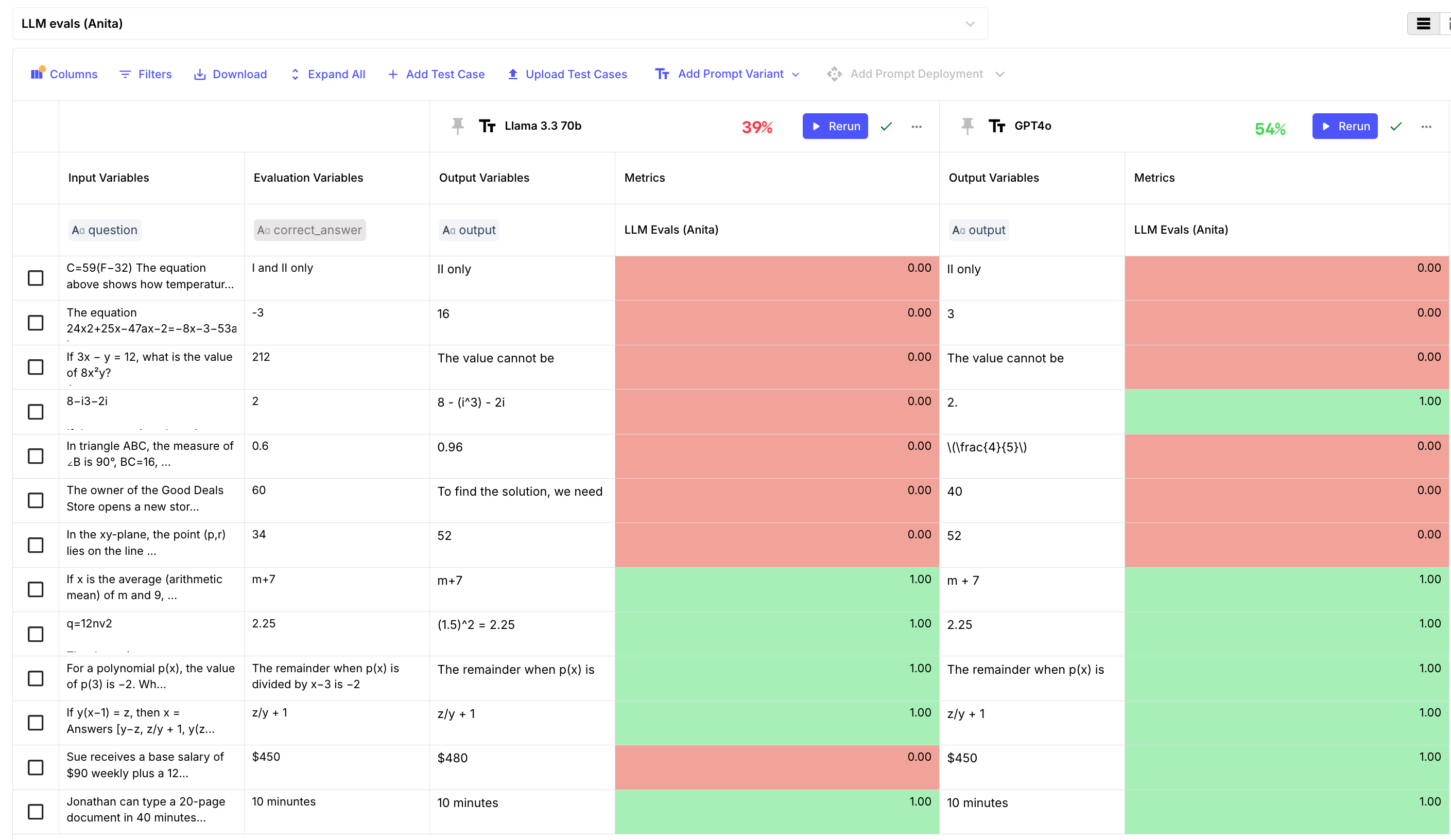
From this table we can notice that Llama 3.3 70b has 15% lower performance than GPT-4o on math problems — which is not surprising.
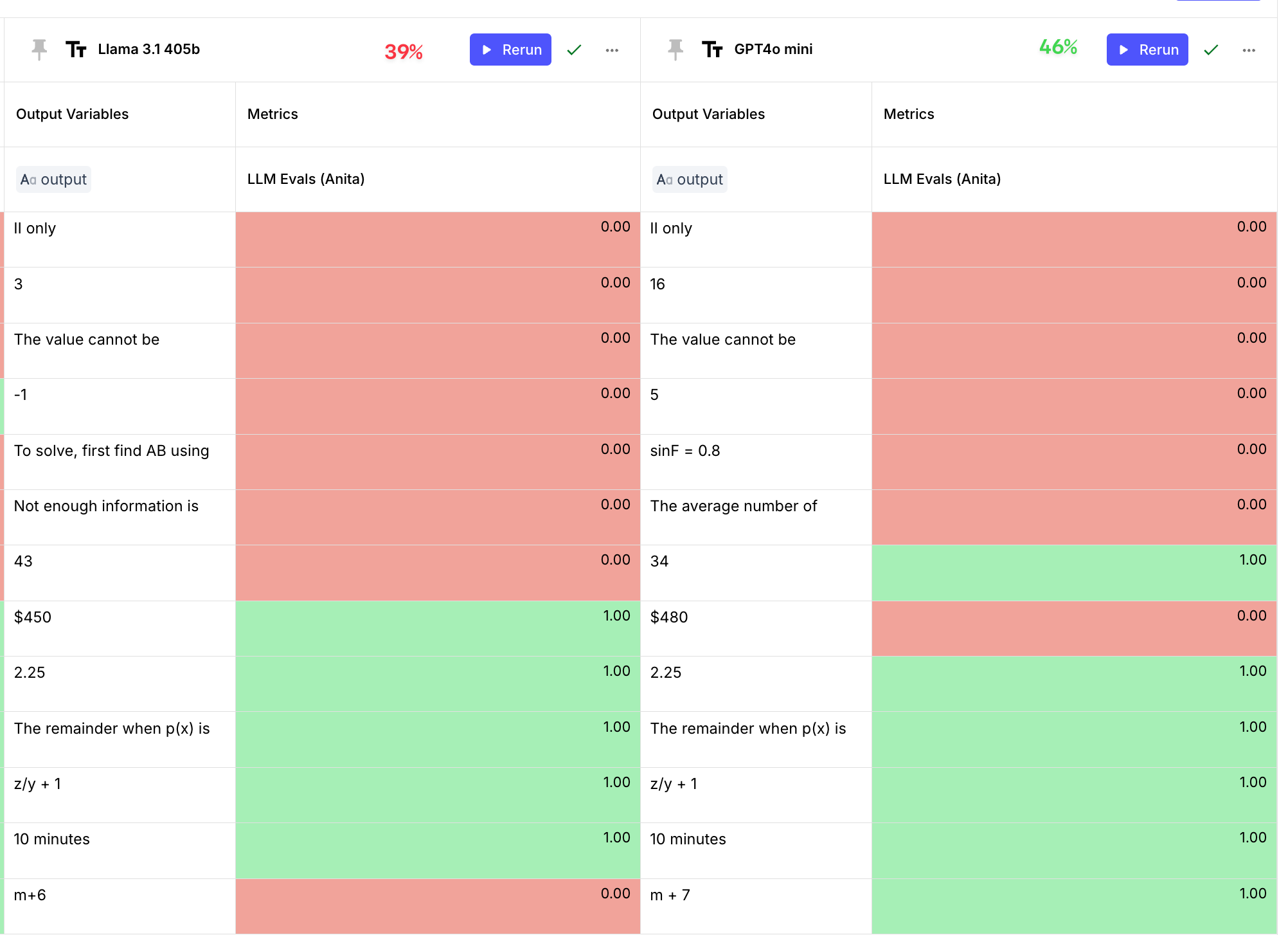
For good measure, we also threw in Llama 405b and GPT-4o mini, and saw that:
GPT-4o mini is outperforming both Llama 405b and 3.3 70b; Llama 3.1 405b and the 3.3 70b model definitely have a similar performance, as reported by the Meta team.
Reasoning Problems
GPT-4o is the best model for reasoning tasks — as we can see from standard benchmarks. But is the Llama 3.3 70b better?
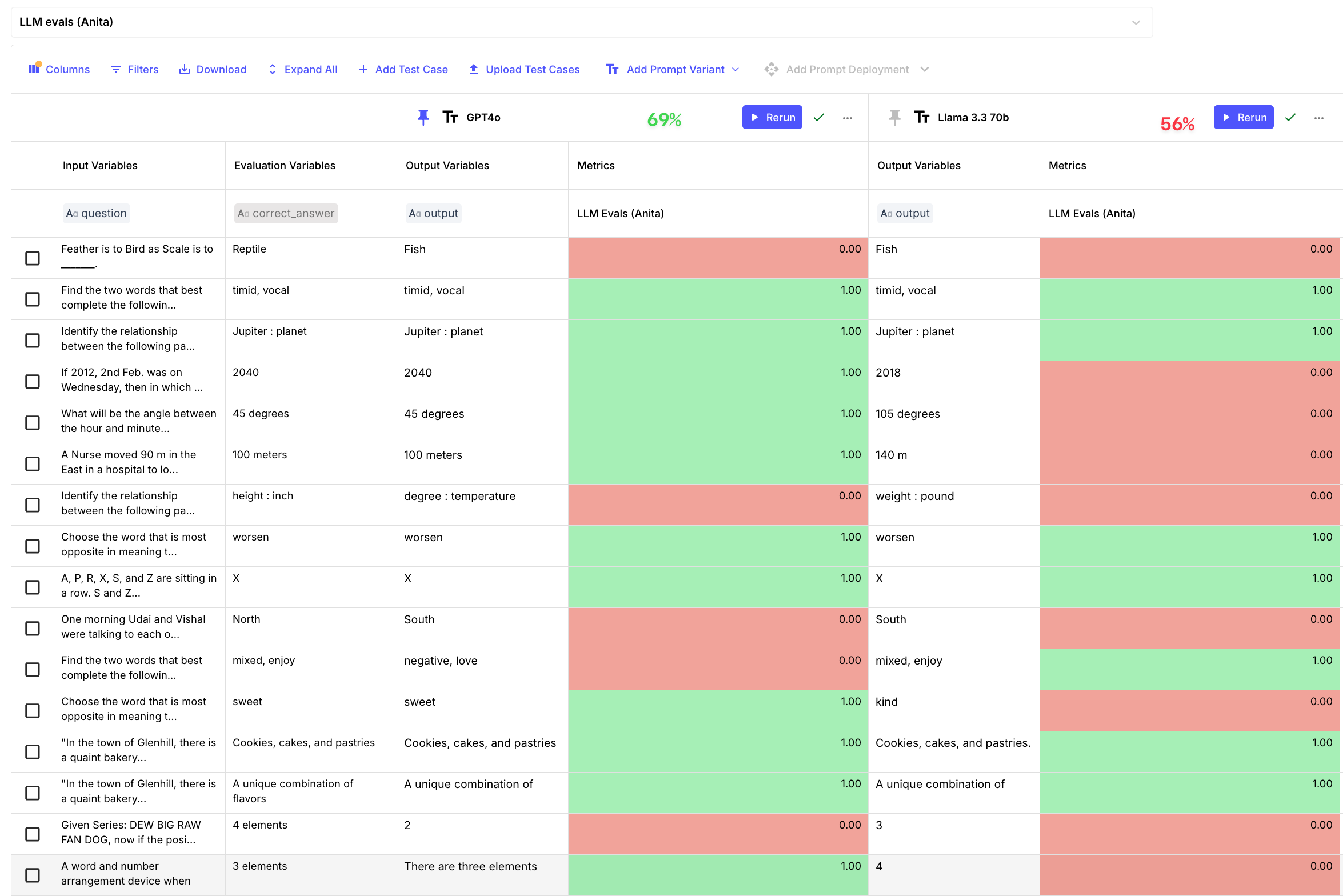
To find out, we selected 16 verbal reasoning questions to compare the two. Here is an example riddle and its sources:
"Choose the word that best completes the analogy: Feather is to Bird as Scale is to _______.
Answers [Reptile, Dog, Fish, Plant]
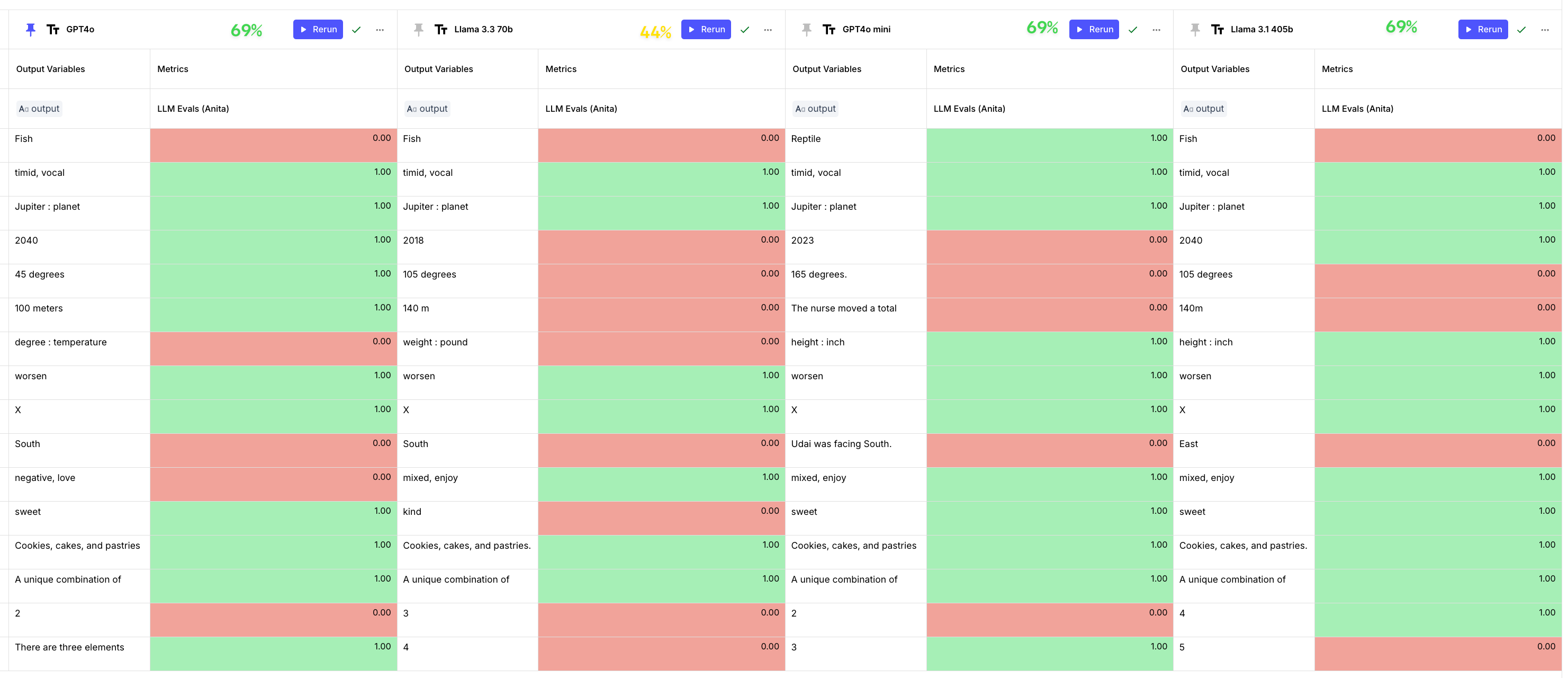
Corerct answer: Reptile" After we ran the evaluation in Vellum, we noticed that GPT-4o is still better when it comes to reasoning challenges with 69% accuracy, vs 56% accuracy for Llama 3.3 70b.
For good measure, we threw in the Llama 3.1 405b model and the GPT-4o mini, and we found out that they too have similar performance to GPT-4o (69%).
More analysis is needed here, but we can see that the 405b model is still outperforming the new 3.3 70b model.
Classification
In this analysis, we had both Llama 3.3 70b and GPT-4o determine whether a customer support ticket was resolved or not. In our prompt we provided clear instructions of when a customer ticket is closed, and added few-shot examples (4 in total) to help with most difficult cases.
We ran the evaluation to test if the models' outputs matched our ground truth data for 100 labeled test cases.
You can see the results we got here:
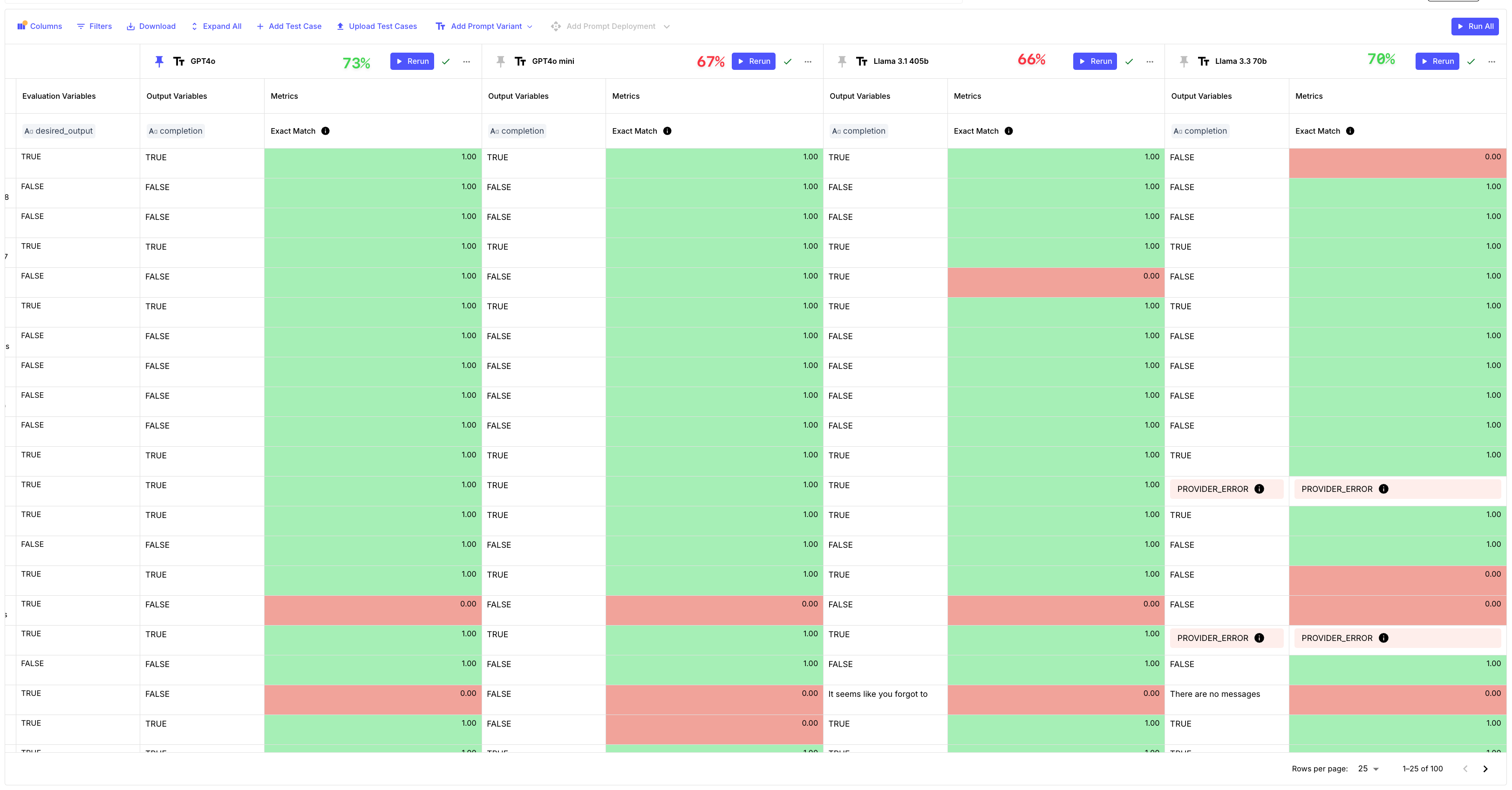
GPT-4o continues to lead in classification tasks (73% accuracy), closely followed by Llama 3.3 70b (70% accuracy). In comparison, GPT-4o Mini and Llama 3.3 405b lag behind, with 67% and 66% accuracy respectively.
Conclusion
Our evaluation reveals that while proprietary models like GPT-4o excel in certain tasks, open-source models like Llama 3.3 70B remain highly competitive—especially when considering factors like cost, customization, and deployment flexibility.
Looking to evaluate these models for your specific use case? Book a call with one of our AI experts to get started. 🚀






