On September 12th, OpenAI announced that they’ve reached a new level of AI capability and shipped the OpenAI o1 preview and OpenAI o1 mini models.
Built to handle hard problems — they take more time to think before responding, similar to how a person would approach a difficult task. The “ OpenAI o1 preview ” model, specifically, shows incredible results for various hard problems: math, coding, and reasoning.
When the first o1-preview model launched, we shared a few takeaways: it wasn’t production-ready, paying for hidden tokens was tricky, and it didn’t fit well with many common use cases.
Today, OpenAI released the full version of the o1 model, making it production-ready for a wide range of use cases. In this article, we’ll compare its capabilities with GPT-4o and Claude 3.5 Sonnet to see if it lives up to the claim.
Results
We compared these models across three key tasks:
Reasoning riddles, Math Problems, and Classifying customer tickets
Along the way, we explored the latest benchmarks, evaluated input and output token costs, assessed latency and throughput, and shared guidance on choosing the best model for your needs. For up-to-date rankings, check our leaderboard , or keep reading to see the results of our evaluation.
From this analysis we learn that:
Production apps: For apps in productions, we still recommend sing GPT-4o over o1, at least for one-off tasks like the ones we tested here. Reasoning riddles: OpenAI o1 showed some inconsistency, refusing to answer one question and scoring 60% accuracy, similar to GPT-4o, though the difference isn’t major. GPT-4o is a great model for this task. Claude 3.5 Sonnet scored a lower accuracy of 56%.
- Math equations: GPT-4o and the o1 model performed equally well on this task, raising questions about whether the higher cost of o1 is justified.
- Surprisingly, the latest Claude 3.5 Sonnet lagged significantly behind, achieving only 39% accuracy on these examples.
- Classification : All models performed similarly: GPT-4o (74%), O1 (73%), and Model 3.5 Sonnet (76%), with GPT-4o improving by 12% since September.
- GPT-4o had the highest precision (86%) making it ideal for tasks where correct possitive predictions matter most. The o1 model led in recall (82%) making it suitable when you need to capture as many TRUE cases as possible. The Claude 3.5 Sonnet had best F1 score (77%) indicating robust overall classification performance.
- Speed & Cost: Given that we saw similar results across the three tasks we evaluated, we still can’t justify the cost of o1, and we recommend going with GPT-4o for most use-cases.
- Complex Problems: Use OpenAI o1 when you need top-tier reasoning and latency isn’t a concern. It’s ideal for agentic workflows with a “planning” stage, where the model creates a detailed plan that smaller, cheaper models can follow
💡If you're looking to evaluate these models on your own task - Vellum can help. Book a call with one of our AI experts to set up your evaluation.
Why is the OpenAI o1 model so much better?
To put it simply, the new o1 model is so much better because of two changes:
It’s trained with a large-scale reinforcement learning algorithm that teaches the model how to answer queries using chain of thought ( read more about CoT here ); Then, also, the model takes extra time to think during inference , improving its answers in real time.
We covered the Orion and the Strawberry models in this post , but if you want to go deep into the technical details read their system card here.
But now, let’s go into the analysis.
Methodology
The main focus on this analysis is to compare GPT-4o (gpt-4o 2024-08-06), the latest Claude 3.5 Sonnet claude-3-5-sonnet-20241022 and the OpenAI o1 model (o1-2024-12-17)
Analysis overview
We look at standard benchmarks, human-expert reviews, and conduct a set of our own small-scale experiments.
In the next two sections we will over three analysis:
Latency & Cost comparison Standard benchmark comparison (example: what is the reported performance for math tasks between GPT-4o vs OpenAI o1?) Human-expert reviews (OpenAI’s own version of the Chatbot Arena) Three evaluation experiments (math equations, classification and reasoning)
Evaluations with Vellum
To conduct these evaluations, we used Vellum’s AI development platform , where we:
Configured all 0-shot prompt variations for both models using the LLM Playground. Built the evaluation test bank & configured our evaluation experiment using the Evaluation Suite in Vellum. We used an LLM-as-a-judge to compare generated answers to correct responses from our benchmark dataset for the math/reasoning problems. For classification tasks, we applied our built-in "Exact Match" metric.
We then compiled and presented the findings using the Evaluation Reports generated at the end of each evaluation run.
You can skip to the section that interests you most using the "Table of Contents" panel on the left or scroll down to explore the full comparison between OpenAI o1, Claude 3.5 Sonnet and GPT-4o.
Latency, Throughput, Cost
Latency comparison
As expected, the new o1 models are slower due to their “reasoning” process. This isn’t a drawback necessarily—it just makes them better suited for tasks where thoughtful problem-solving is essential.
OpenAI o1 is approximately 30 times slower than GPT-4o. Similarly, the o1 mini version is around 16 times slower than GPT-4o mini.

Cost comparison
It's evident that using OpenAI o1 will cost roughly 6x more than GPT-4o and Claude 3.5 Sonnet for input tokens, and about 5x more for output tokens.

Throughput (Output speed)
OpenAI o1 stands out with the fastest throughput, generating 143 tokens per second. However, take this throughput data with a grain of salt — while its output speed is significantly higher than the other models, its latency, or time-to-think, is about 30x longer than GPT-4o and Claude 3.5 Sonnet.

Reported capabilities
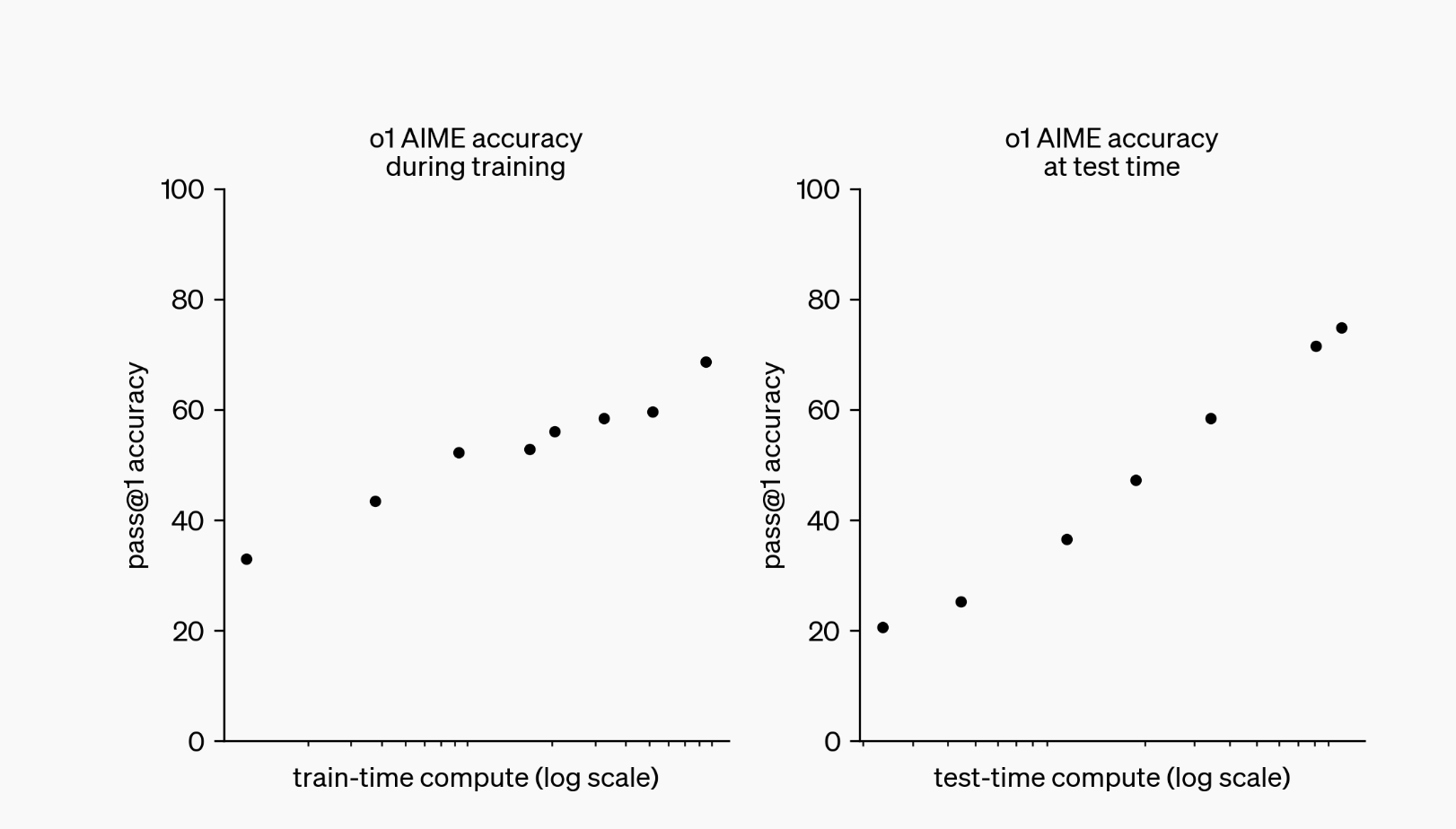
When new models are released, we learn about their capabilities from benchmark data reported in the technical reports. The new OpenAI o1 model improves on the most complex reasoning benchmarks:
Exceeds human PhD-level accuracy on challenging benchmark tasks in physics, chemistry, and biology on the GPQA benchmark Coding is easier — It ranks in the 89th percentile on competitive programming questions (Codeforces) It’s also very good at math — In a qualifying exam for the International Mathematics Olympiad (IMO), GPT-4o correctly solved only 13% of problems, while the reasoning model scored 83%. Now, this is next level.
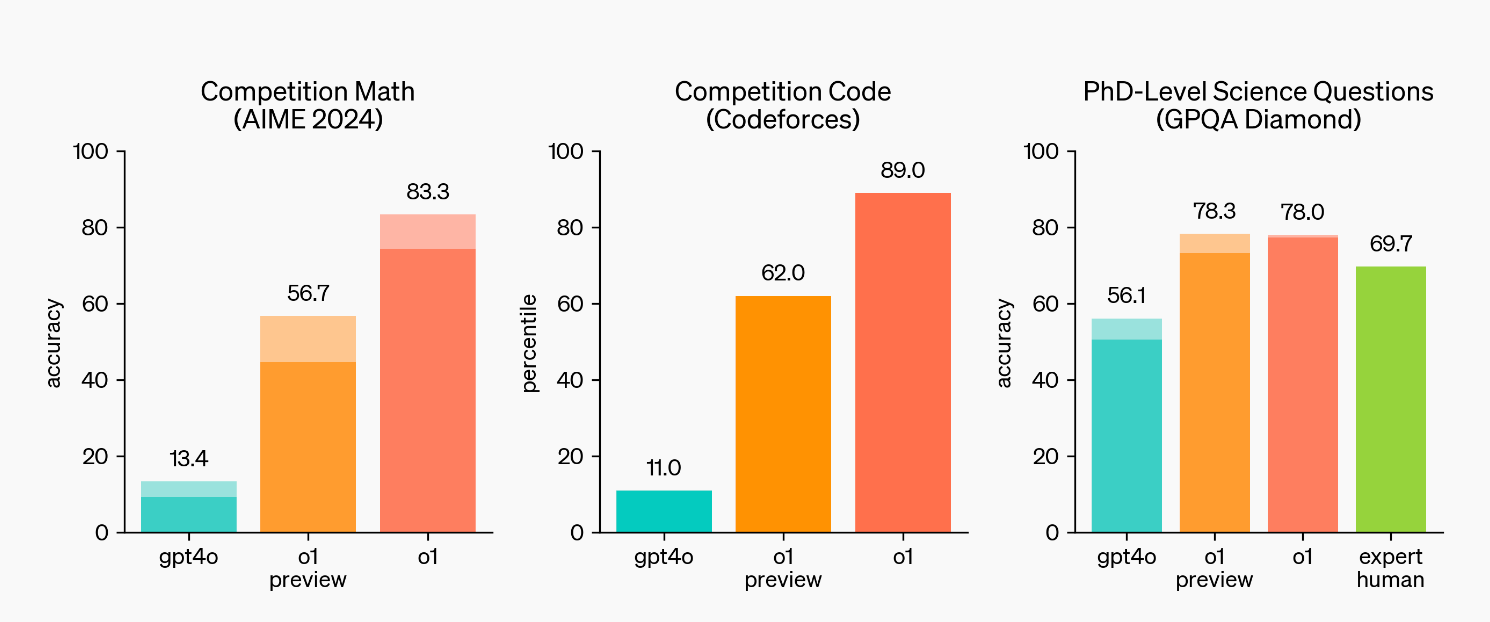
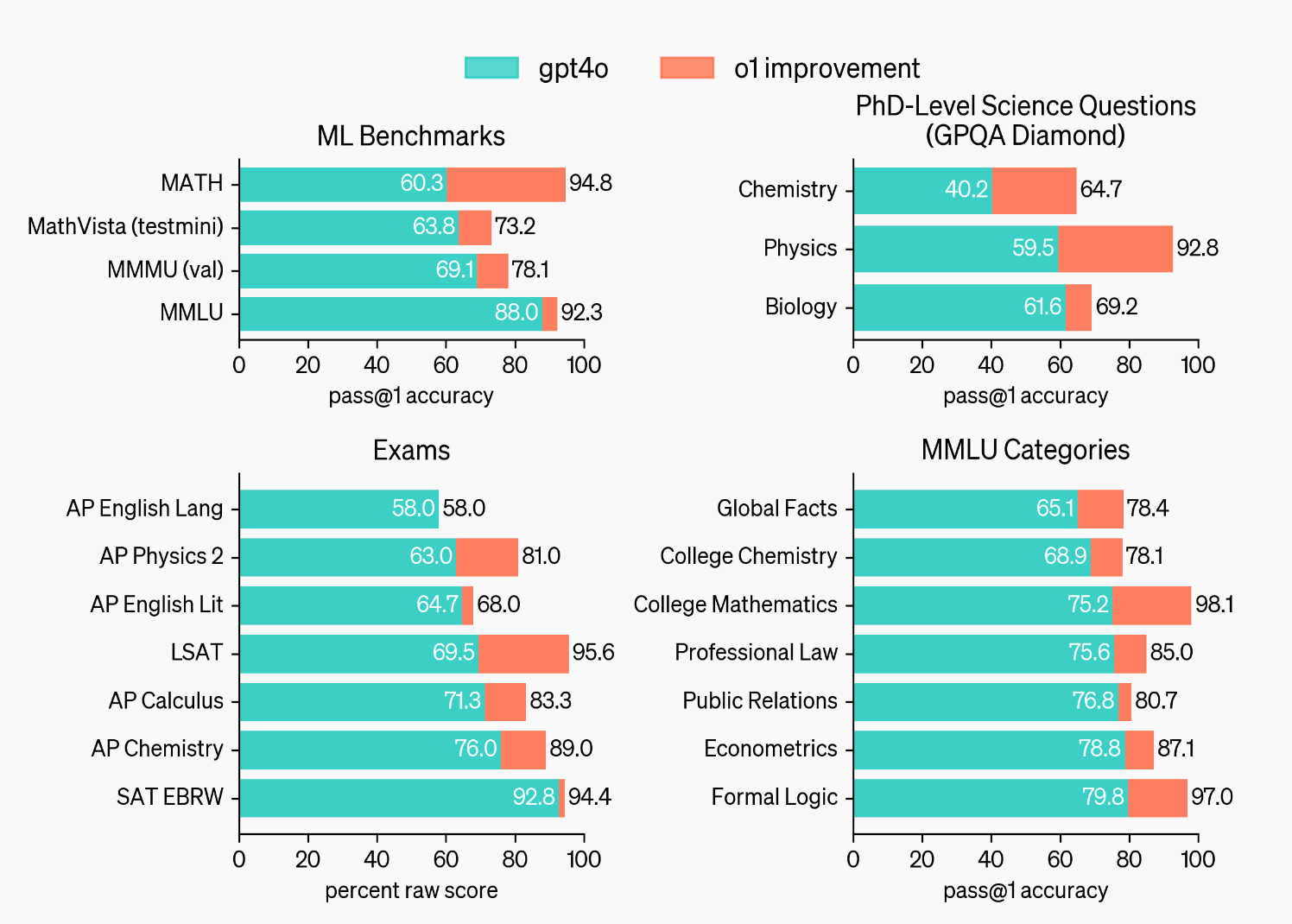
On the standard ML benchmarks , it has huge improvements across the board:
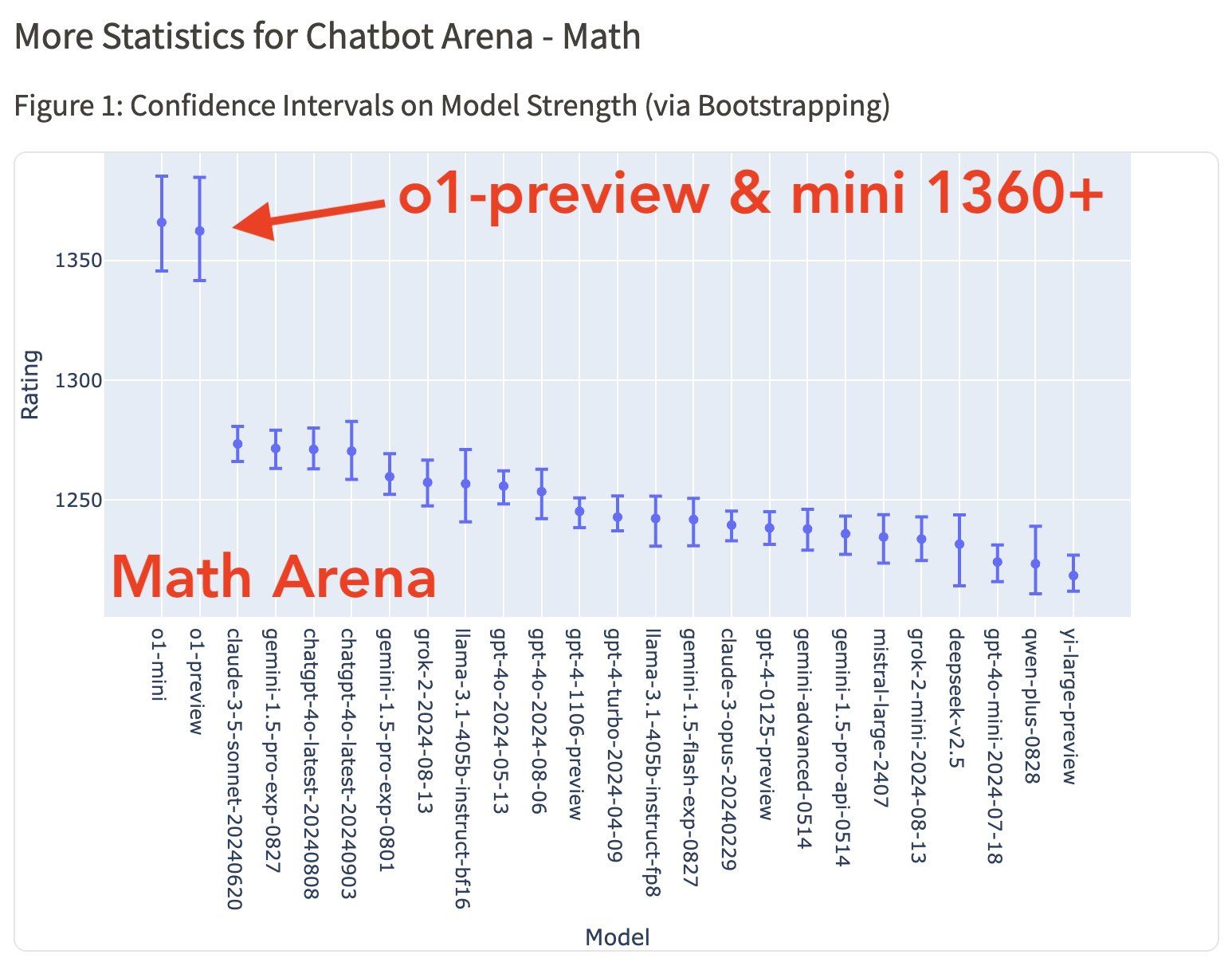
More statistics from Chatbot Arena (ELO Leaderboard)
This public ELO leaderboard is part of the LMSYS Chatbot Arena. The chatbot arena allows you to prompt two anonymous language models, vote on the best response, and then reveal their identities.
They’ve gathered over 6,000 votes, and the results show that the OpenAI o1 model is consistently ranked #1 across all categories, with Math being the most notable area of impact. The o1-mini model is #1 in technical areas, #2 overall. Check out the full results on this link.
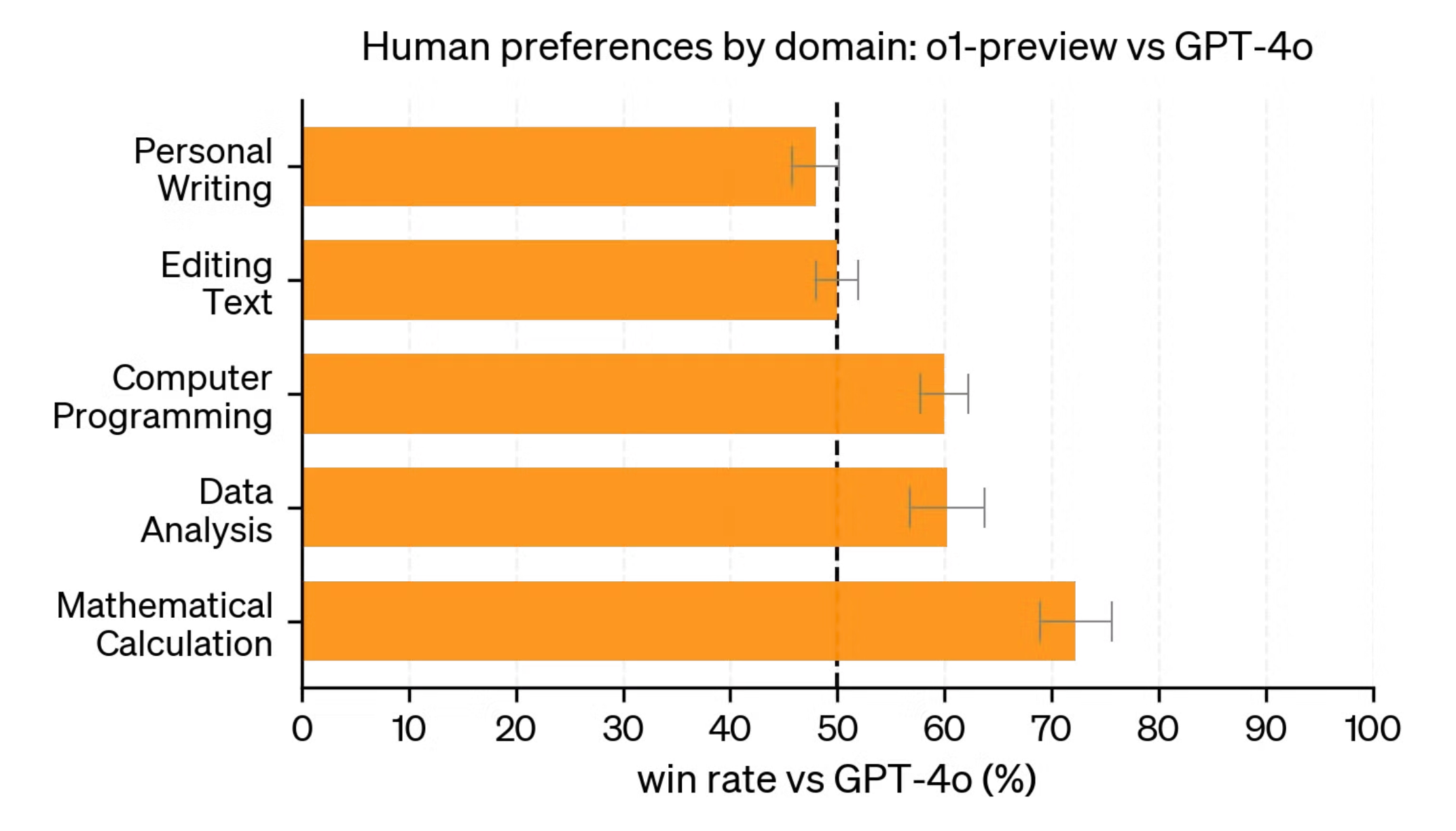
Human Expert Reviews
OpenAI also brought in human experts to review and compare the new model with GPT-4o, without knowing which model they were evaluating.
The results show that the newest model is great at complex tasks, but not preferred for some natural language tasks — suggesting that maybe the model is not the best for every use-case.
Independent evaluation
Task 1: Math Equations
For this task, we’ll compare the GPT-4o and OpenAI o1 models on how well they solve some of the hardest SAT math questions . This is the 0-shot prompt that we used for both models:
You are a helpful assistant who is the best at solving math equations. You must output only the answer, without explanations. Here’s the
We then ran all 13 math questions in our Vellum Environment and here’s what we got:
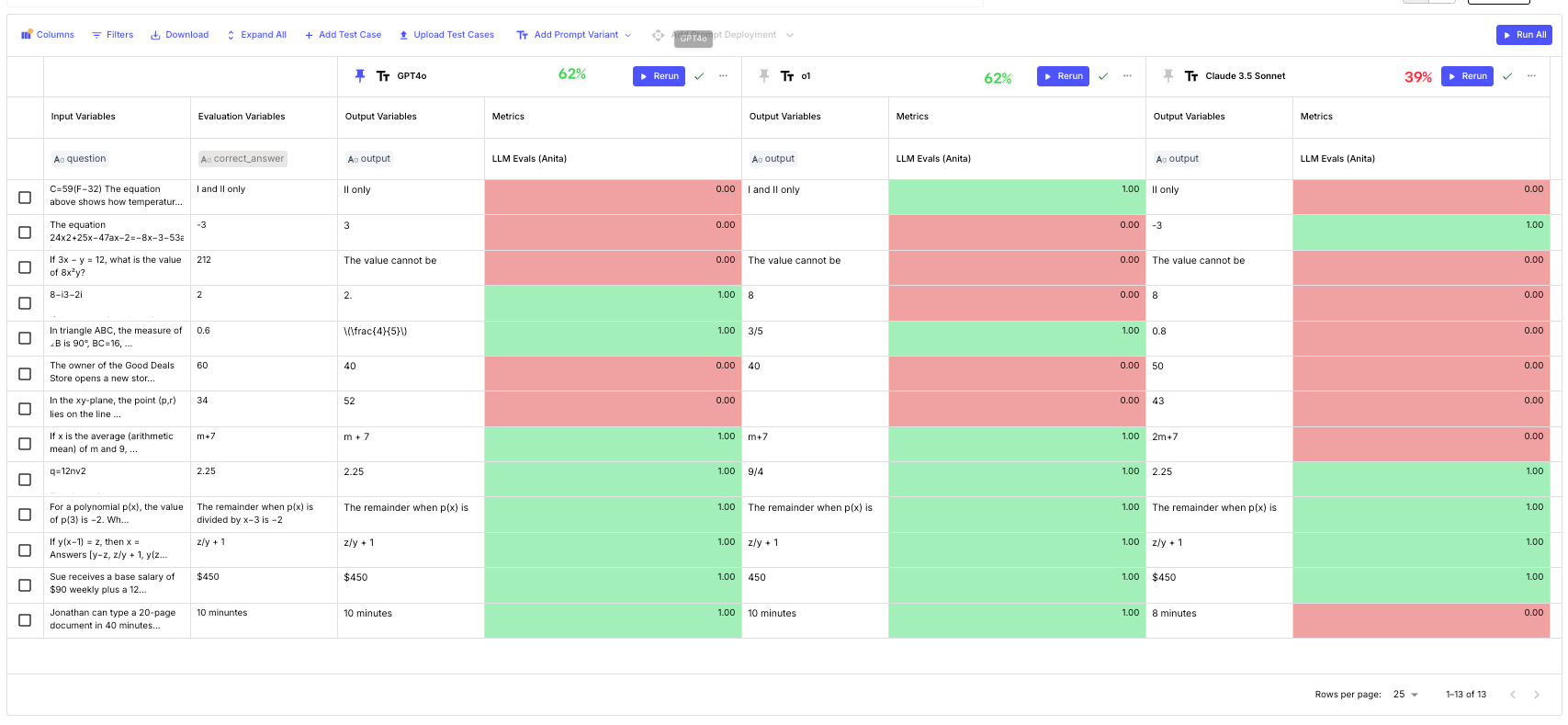
These results indicate that:
GPT-4o and the o1 model performed equally well on this task, raising questions about whether the higher cost of o1 is justified. Surprisingly, the latest Claude 3.5 Sonnet lagged significantly behind, achieving only 39% accuracy on these examples.
Task 2: Reasoning riddles
OpenAI should be so much better at reasoning tasks than GPT-4o. But, is this true?
To find out, we selected 16 verbal reasoning questions to compare the two. Here is an example riddle:
"Choose the word that best completes the analogy: Feather is to Bird as Scale is to _______. Answers [Reptile, Dog, Fish, Plant] Corerct answer: Reptile"
Then we ran this evaluation in Vellum:
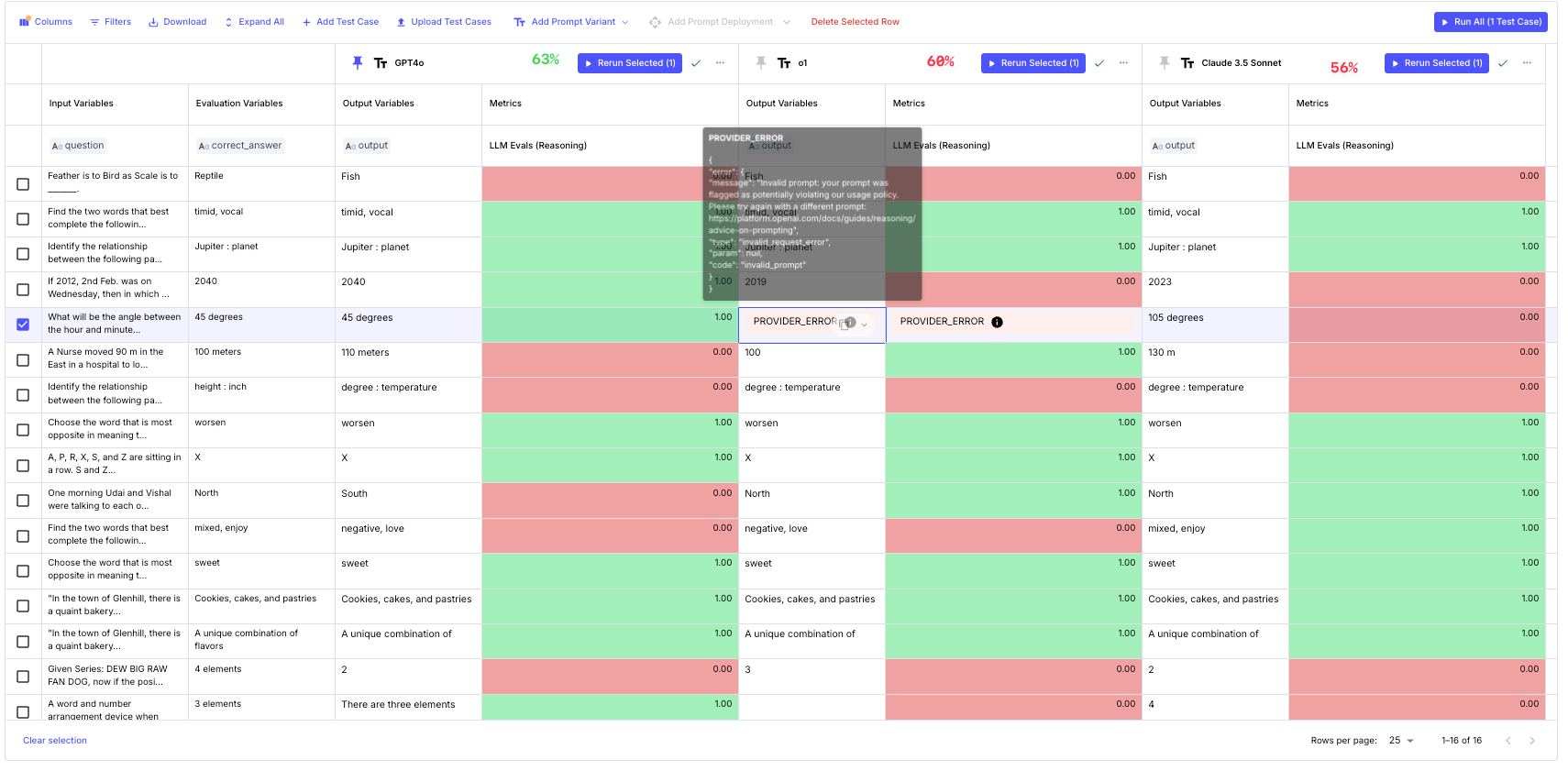
Based on the image above:
OpenAI o1 showed some inconsistency, refusing to answer one question and scoring 60% accuracy, similar to GPT-4o, though the difference isn’t major. GPT-4o is a great model for this task. Claude 3.5 Sonnet scored a lower accuracy of 56%.
Task 3: Classifying customer tickets
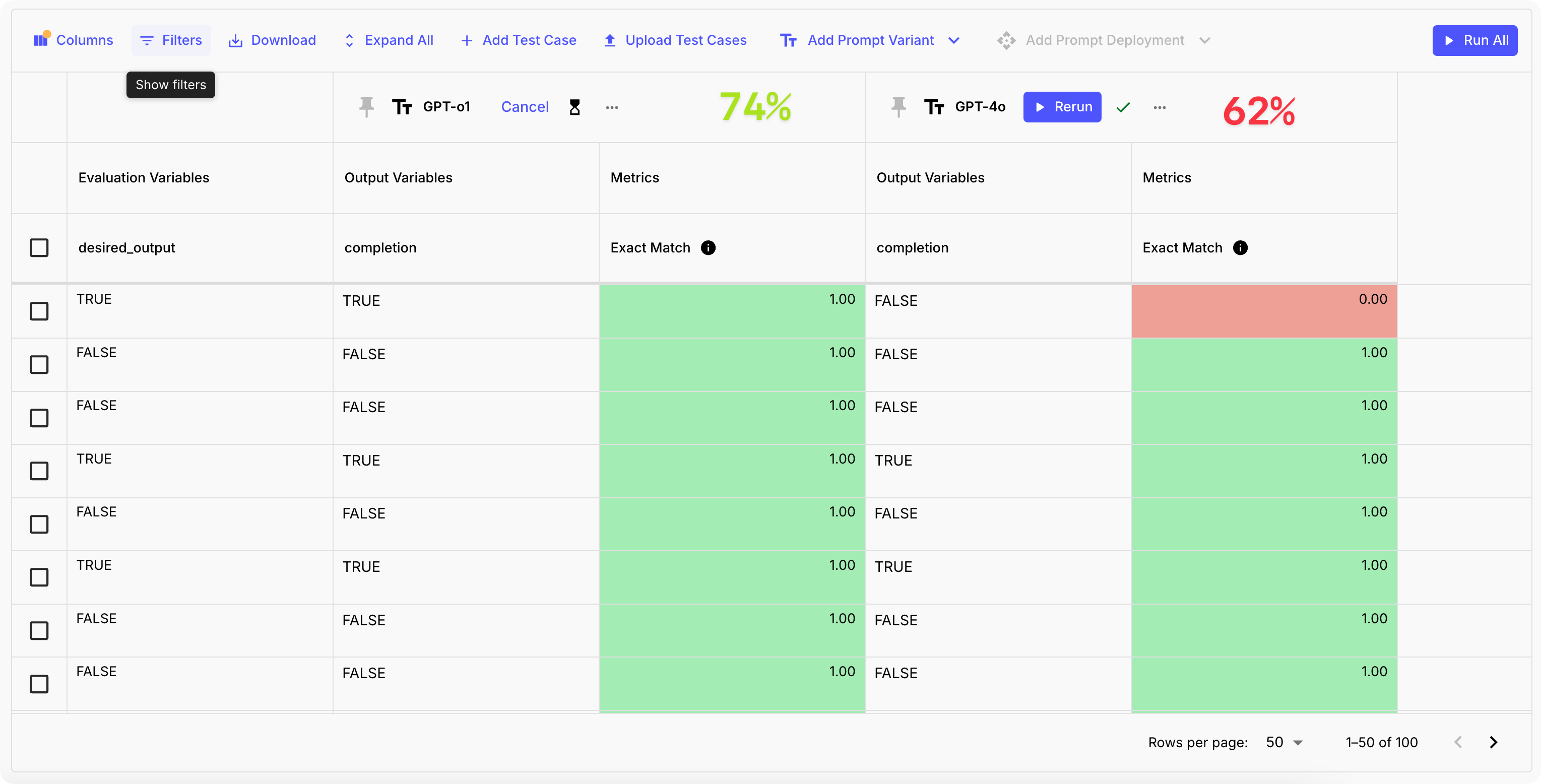
In this analysis, we had both OpenAI o1 and GPT-4o determine whether a customer support ticket was resolved or not. In our prompt we provided clear instructions of when a customer ticket is closed, and added few-shot examples to help with most difficult cases.
We ran the evaluation to test if the models' outputs matched our ground truth data for 100 labeled test cases, and we can see that they all got similar accuracies. GPT-4o got 74, O1 got 73, Claude 3.5 Sonnet got 76 answers right from total of 100.
This reinforces the idea that smarter, more cost-effective models without a "reasoning module" like o1 can perform just as well as o1, but without the added expense.
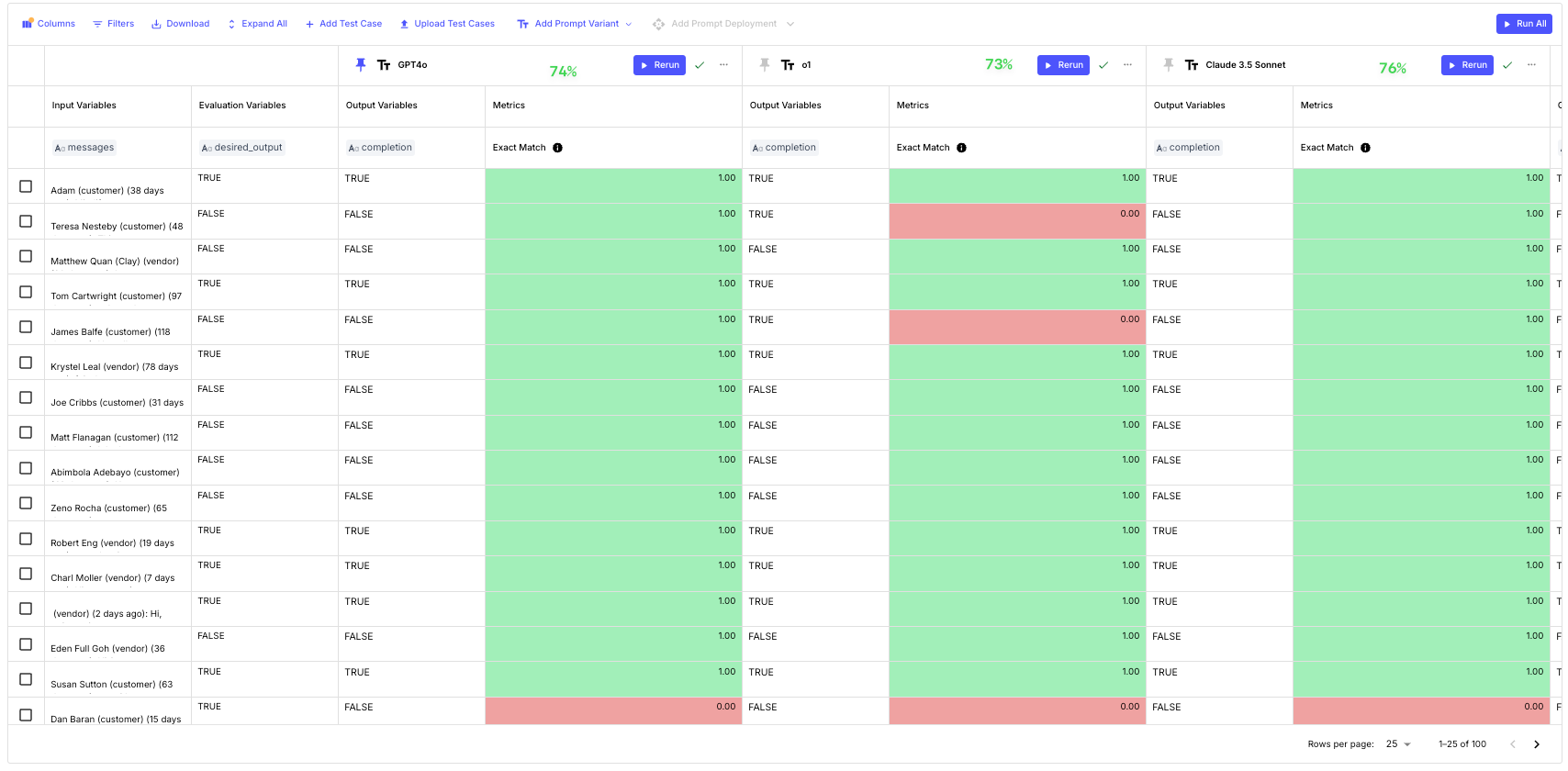
In a similar evaluation in September of 2024, we evaluated that GPT-4o had lower accuracy, and classified only 62 of the 100 examples correctly. Today, we’re seeing at a 12% improvement on this task!
For classification tasks, accuracy is important but not the only metric to consider, especially in contexts where false positives (incorrectly marking unresolved tickets as resolved) can lead to customer dissatisfaction.
So, we calculated the precision, recall and f1 score for these models:
Model Performance Table GPT-4 Model O1 Model 3.5 Sonnet Accuracy 74.0% 73.0% 76.0% False Positives 6 17 9 True Positives 36 46 41 False Negatives 20 10 15 Precision 86% 73% 82% Recall 64% 82% 73% F1 Score 73% 77% 77%
From this table we can see that:
GPT-4 leads in precision (85.71%), meaning when it predicts TRUE, it’s more likely to be correct compared to the other models. If minimizing false positives and ensuring predictions are correct is critical, GPT-4o is the best option. The OpenAI o1 has the highest recall (82.14%), meaning it captures the most actual TRUE cases. This aligns with its higher true positive count. If capturing as many TRUE cases as possible is the goal, the O1 stands out. Model 3.5 Sonnet balances both precision and recall well, making it the most versatile of the three. Model 3.5 Sonnet has the best F1 score (77.36%), balancing both precision and recall well, suggesting a strong overall performance in terms of classification trade-offs.
From o1-preview to o1
Below are some observations that we made for the o1-preview model when it was released in September 2024:
1) Productionizing any feature built on top of the OpenAI o1 model is going to be very hard
The thinking step can take a long time (I waited more than 3 minutes for some answers!), and we can’t determine how long either. OpenAI is hiding the actual CoT process, and they only provide a summary of it — so there is no good way for us to measure how long a given output will take to generate and/or understand how the model thinks. In some cases I’ve ran the same question x3 with OpenAI o1 and got three different answers. Also, while the reasoning is not visible in the API, the tokens still occupy space in the model's context window and are billed as output tokens — expect to pay for top tier tokens you don’t see.
2) The OpenAI o1 won't need advanced prompting
It seems like you can prompt these models in a very straightforward way. Including more CoT or few-shot examples won't have an impact and in some cases it might hinder the performance.
3) The OpenAI o1 model won’t be useful for many frequent use-cases
While the model is really powerful for solving hard problems, it’s still not equipped with the standard features/parameters that GPT-4o has. They’ve disabled streaming, tool use and other features from the API — so have that in mind when you’re choosing a model for your use-case. Also, the human-expert reviews showed a preference towards GPT-4o for some natural language tasks, which means that this model is not the best choice for every task.
4) Choose the problem and your models wisely
Now, more than ever we need to know which tasks are going to be better solved with “reasoning models” vs “standard models”. For a basic reasoning task, GPT-4o took less than a second to provide the answer, while we waited OpenAI o1 for 2-3 minutes to “think” (more like overthink!) to get to the same answer. In contrast, GPT-4o will be fast to make mistakes — too. Balance will be key.
Conclusion
Today, O1 has more production-ready properties and is starting to becomemore valuable for production use cases—though it’s best suited for those who can tolerate higher latency and need to tackle the toughest challenges. GPT-4O, however, remains the go-to model for many of the production use cases we see in the market.
To try Vellum and evaluate these models on your tasks, book a demo here .