Just two weeks after its launch, Claude 3 Opus overtook GPT-4 to claim the top spot on the Chatbot arena leaderboard , which relies on unbiased ratings of chatbot response quality.
As a result, many companies began evaluating Claude models for their use cases, attracted by factors such as the expanded context window size (200k) and lower costs.
hIn this article, we analyze the current state of Claude 3 Opus GPT-4 for various tasks, using the latest data, and independently-run evaluations.
Comparing the Models: Our Approach
The main focus on this analysis is to compare two models: GPT-4 ( gpt-4-0613 ) and Claude 3 Opus . However, we also present some data for two additional models: The latest GPT-4 Turbo model ( gpt-4-turbo-2024-04-09 ) and Claude 3 Sonnet to explore whether more affordable models can serve as alternatives.
We look at standard benchmarks, community-run experiments, and conduct a set of our own small-scale experiments.
In the next two sections we cover:
Basic comparison (example: Cost vs Context Window) Standard benchmarks comparison (example: what is the reported performance for math tasks with Claude 3 Opus vs GPT-4?)
Then, we compare the models on the following tasks:
Handling large contexts Math riddles Document summarization Data extraction Heat map graph interpretation Coding
You can skip to the section that interests you most using the "Table of Contents" panel on the left or scroll down to explore the full comparison between GPT-4 and Claude 3 Opus.
💡 Side Note: Claude 3 Opus is trained using unique methods and techniques, and requires different prompting. We built a prompt converter that automatically converts GPT-4 to Claude 3 Opus prompts. You can try it here .
Basic Comparison
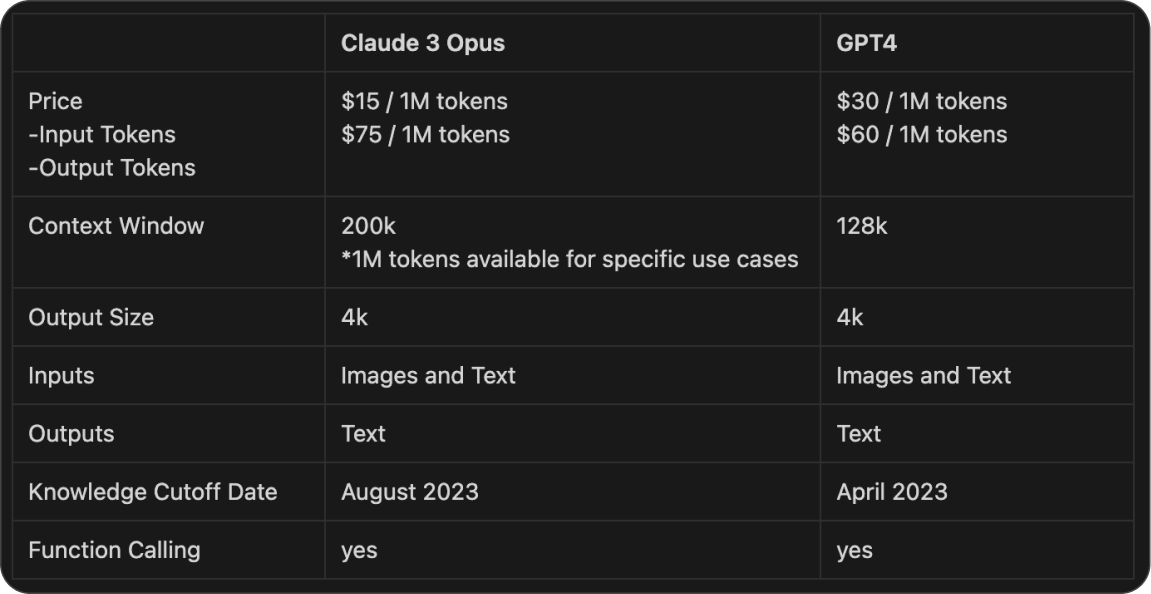
The cost analysis of Opus versus GPT-4 shows that GPT-4 is twice as expensive, charging $30 per 1 million input tokens, in contrast to Opus's $15 per 1 million tokens.
In addition to that, Claude Opus supports a larger context window of 200k, compared to GPT-4.
Both models support multimodal input & function calling, offering flexibility for complex applications. Based on the data in the table below, the choice between Opus and GPT-4 hinges on the need for cost-efficiency versus specific functional capabilities, as Opus offers a more affordable rate and larger context window, while GPT-4 may excel in certain specialized tasks.
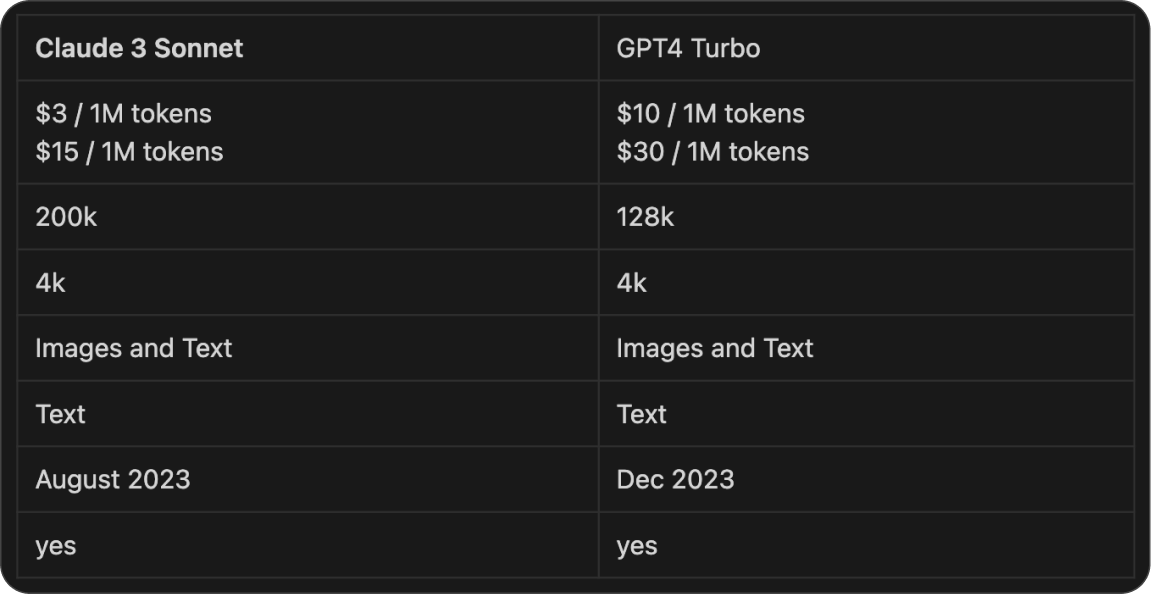
As an additional reference, below is a comparison table of GPT-4-Turbo versus Sonnet . These models prioritize speed and cost over performance and can serve as excellent alternatives for certain tasks in your projects.
*Despite OpenAI's claim that GPT-4 Turbo is more powerful than GPT4, many have observed that its latest version has lackluster performance, leading some to compare it with Sonnet. However, one advantage of GPT-4 Turbo is its more recent knowledge cutoff date (December 2023) compared to GPT-4 (April 2023).
Standard Benchmark Comparison
The first place to start learning about these models is the benchmark data reported in their technical reports. The Anthropic announcement suggests that all Claude 3 models have set a new standard in performance. The image below compares the performance of all Claude 3 models against GPT-3.5 and GPT-4.
If you would like to gain a better understanding of these benchmarks here is our previous post on the Subject - LLM Benchmarks: Overview, Limits and Model Comparison . We encourage you to bookmark our our leaderboard as a tool for ongoing comparisons.
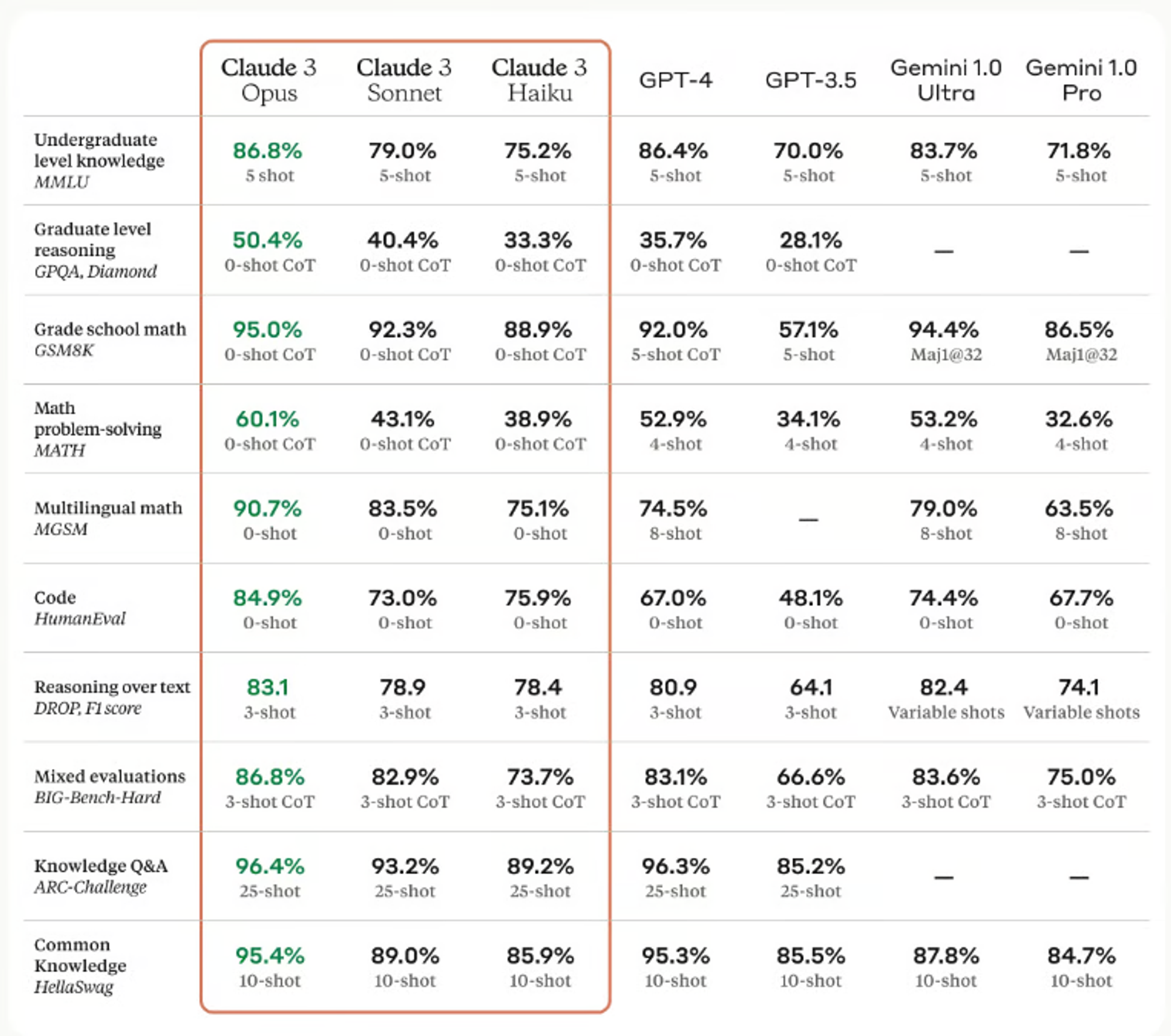
These test results strongly indicate that Claude 3 Opus and Sonnet have become significant challengers to GPT-4 and GPT-4 Turbo.
But, are these standard benchmarks reliable?
If you dig around you will find quite a bit of chatter about others who have delivered similar or even better benchmark results with a newer version of ChatGPT-4 or via different benchmarking techniques. To Anthropics' credit, there is a footnote on their announcement calling out that “engineers have worked to optimize prompts and few-shot samples for evaluations and reported higher scores for a newer GPT-4 model” along with a link to a set Microsoft Open source projects on GitHub where researchers have published results (image below) of GPT-4 matching or exceeding Claude 3 performance.
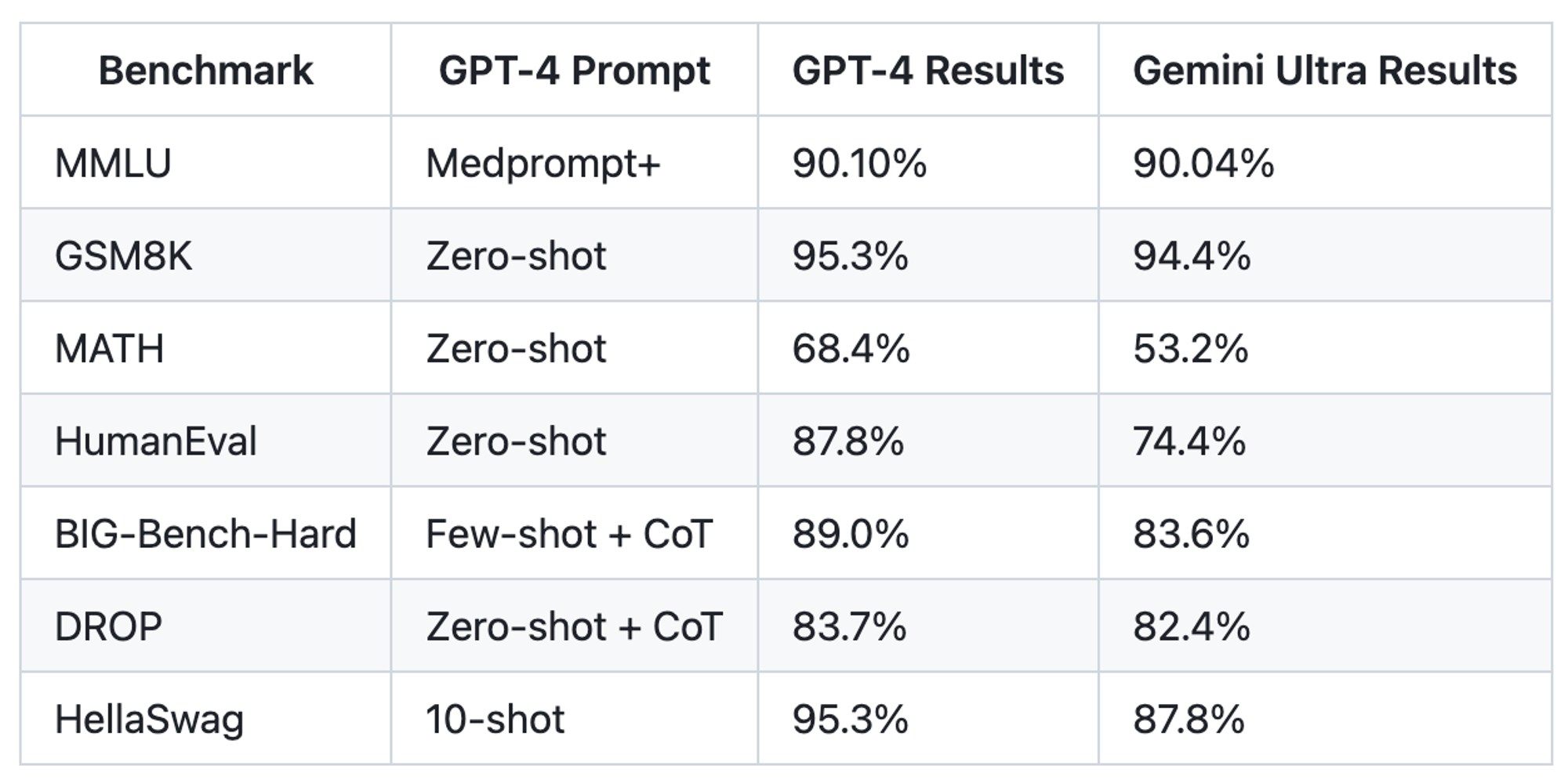
We have to keep benchmarks in perspective.
This article points out that the devil is in the details when seeking to understand the results of LLM benchmarks. For those of us experienced with different models we know the benchmarks don’t tell the full story, and we need to run internal benchmarks customized for the task at hand.
But, one thing is certain: Claude 3 models are powerful and they have emerged as a rival to GPT-4.
Task 1: Handling Long Contexts
Claude’s Opus large context capability and reported proficiency is definitely the headliner these days. But given how these models can easily get confused with complex prompt, we wonder how effective are LLMs at accurately processing large context windows anyway?
The " Needle In a Haystack " (NIAH) is a commonly used evaluation which aims to measure how well Large Language Models (LLMs) perform when dealing with various context sizes. This evaluation method involves embedding a particular piece of information (referred to as the "needle") within a broader, more intricate text (known as the "haystack").
The objective is to determine the capability of an LLM to pinpoint and apply this distinct information within a vast dataset.
###### No specific experiments were conducted for this task; instead, we emphasize the most recent community and provider-run experiments.
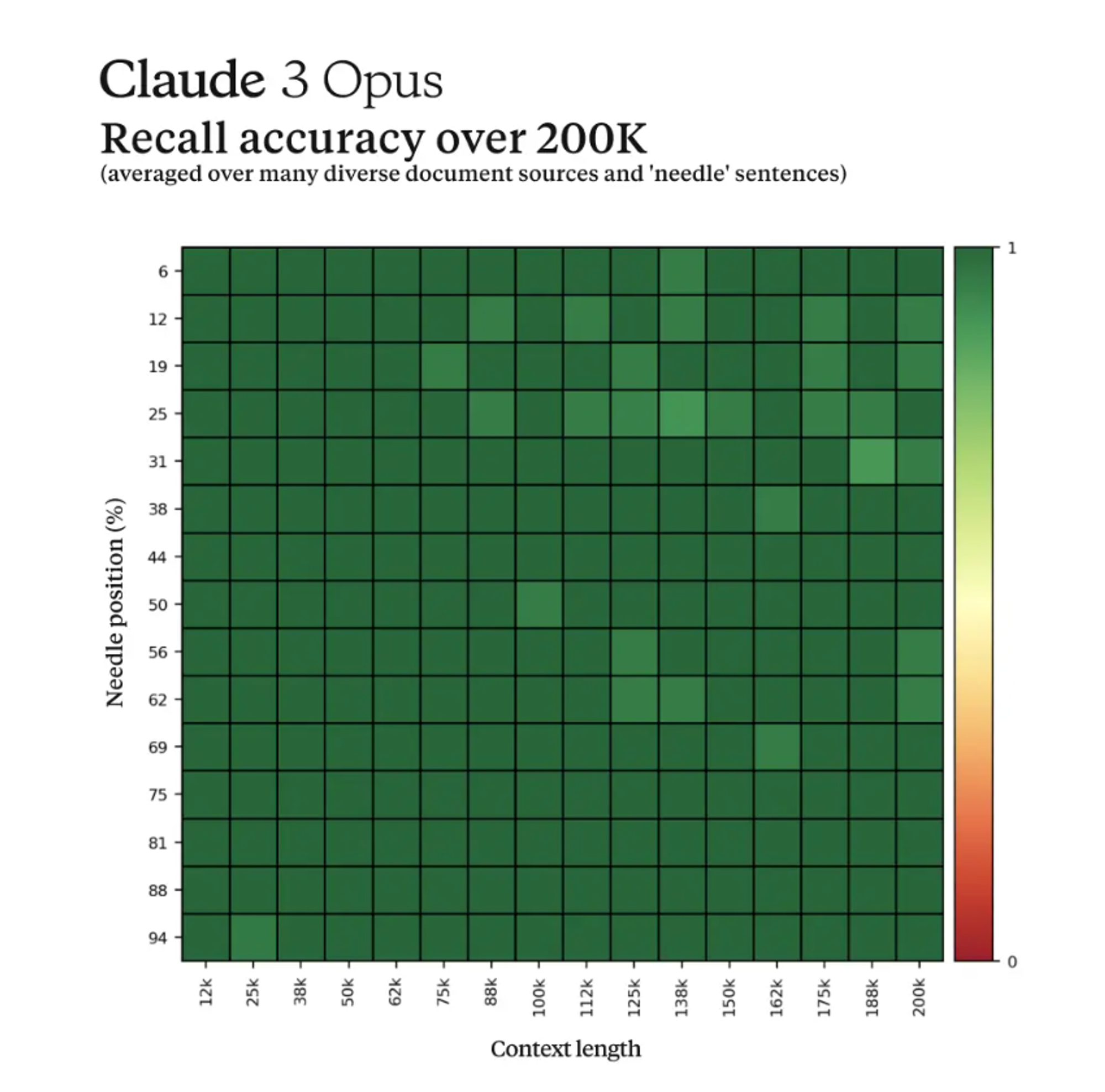
Claude Opus Performance with Large Contexts
Anthropic put out its own Needle In a Haystack research and the results are impressive. According to Anthropic, Opus not only achieved near-perfect recall, surpassing 99% accuracy, but in some cases, it even identified the limitations of the evaluation itself by recognizing that the "needle" sentence appeared to be artificially inserted into the original text by a human.
GPT-4 Performance with Long Context
There is a compelling 3rd party GPT-4 Needle In A Haystack research published by an independent 3rd party Greg Kamradt . Third-party validations tend to inspire more confidence, so let’s look at the results.
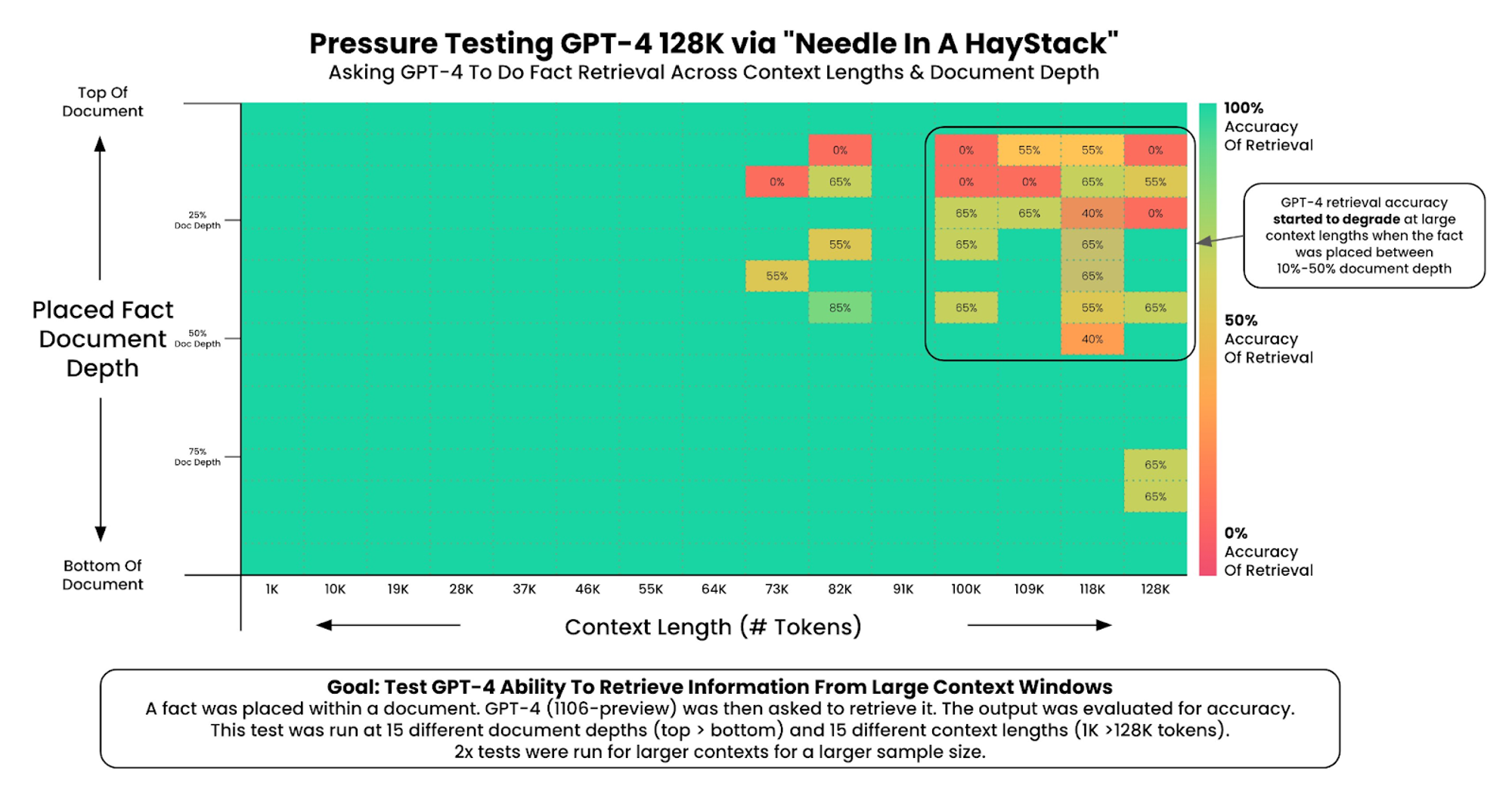
Here are Greg's key observations:
GPT-4’s recall performance started to degrade above 73K tokens. Low recall performance was correlated when the fact to be recalled was placed between at 7%-50% document depth. If the fact was at the beginning of the document, it was recalled regardless of context length.
These tests suggest that Opus is the clear winner.
We would like to see an independent HIAH test on the Claude models and are considering running one ourselves (sign up for our newsletter if you want to be notified about this).
💡 Lost in the Middle It's important to note that better results can be achieved by strategically placing the most important documents at the beginning or end of the long-context prompt. Recent research has analyzed the performance of LLMs handling longer context prompts and found that performance significantly deteriorates when models need to access relevant information in the middle of long contexts.
Task 2: Math Riddles
Now it's time to take these models for a test drive ourselves.
Given all of the hype about Claude’s math chops we wanted to run a small-scale test using Vellum’s Prompt Comparison product, and set up a few math tests. We picked a set of seven math riddles designed for students not yet in middle school and seven more at the middle school level as the cornerstone of the test.
Here are a couple of example riddles and their source :
🧮 For the younger minds If you have four apples and you take away three, how many do you have?" The intuitive answer is three, as those are the apples you took. 🧮 For the older middle school students A cellphone and a phone case cost $110 in total. The cell phone costs $100 more than the phone case. How much was the cellphone?" **The correct answer, a bit more complex, is 105 (not 110!)
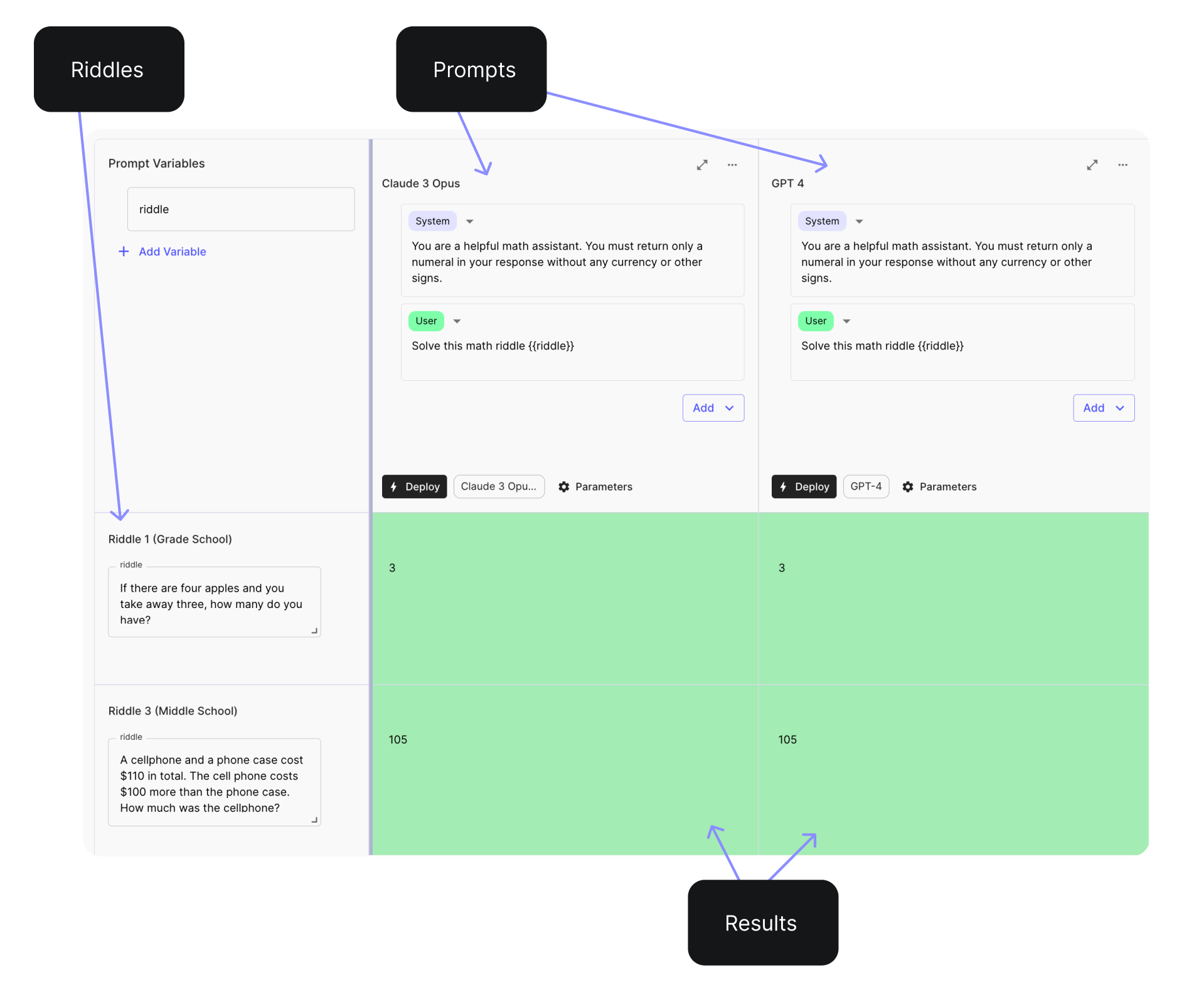
The prompt was the same for both models, given that it’s a simple ask.
System message: You are a helpful math assistant. You must return only a numeral in your response without any currency or other signs. User message: Solve this math riddle {{riddle}}
Before we summarize our results, it is interesting to take a look at the most relevant benchmarks.
Given these benchmarks, how do you think our test results will play out?!

The image below is a screenshot of the Vellum Prompt Sandbox , where we initially experimented with our prompts and two basic examples.
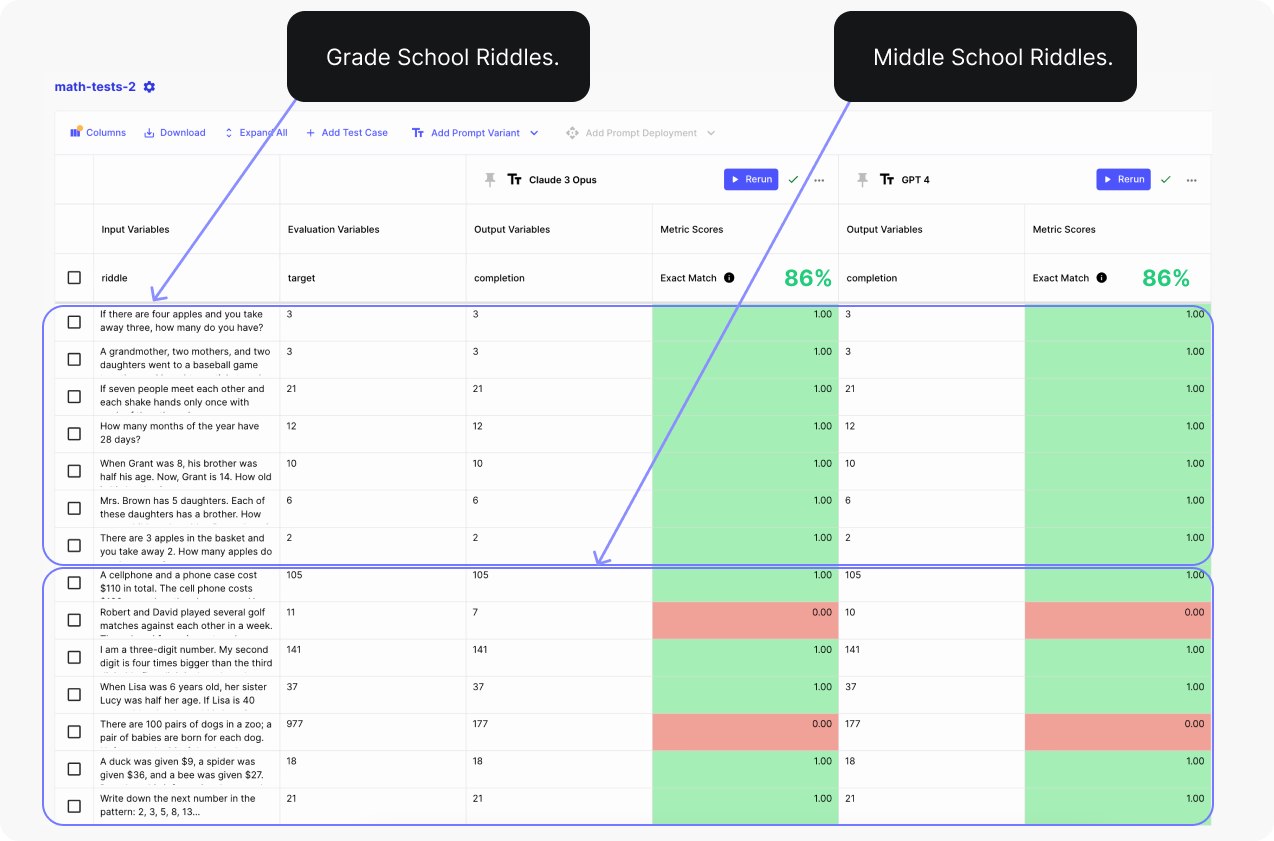
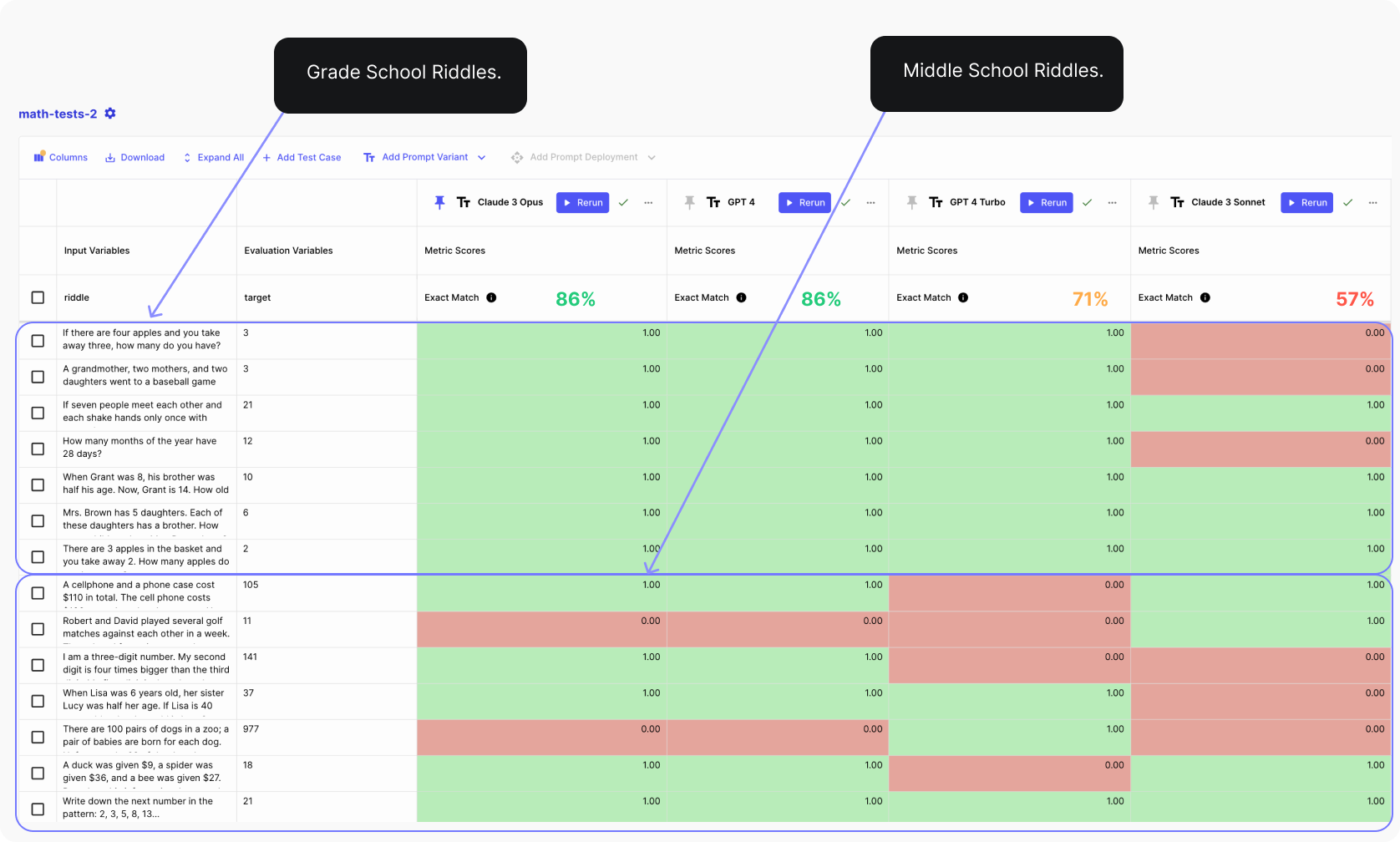
In the next image, we have the two models each attempting to answer a total of 14 math riddles, 7 grade school level, and 7 middle school level riddles.
We use Vellum Evaluations to compare the average performance across all test cases. And as you can see below, both Opus and GPT-4 missed the exactly same answers and got 86% of the answers right. For grade level riddles, they had perfect score.
For good measure, we also wanted to test the difference in performance between GPT-4 Turbo & Sonnet, as a cost/speed alternative.
The image below shows that GPT-4 Turbo and Sonnet both have lower performance than Opus and GPT-4 for this task. However, Sonnet performed poorly in both grade and middle school riddles, while GPT-4 Turbo achieved a perfect score in grade school riddles.
Key Takeaways:
If math is your main challenge both Opus and GTP4 should be considered. If you want to optimize for cost/speed for grade-school riddles, you can use GPT-4 Turbo. Middle school riddles are still hard for both Sonnet / GPT-4 Turbo.
Other insights:
In a recent paper , researchers noted that GPT-4 performs like a B/B+ student in math and STEM fields. With plugins like Code Interpreter or WolframAlpha, it can solve challenging word problems about one-third of the time, showcasing significant progress from earlier AI capabilities. The newest GPT-4 Turbo model launched on April 2024, ( gpt-4-turbo-2024-04-09 ), got a big jump in math/reasoning in the LiveCodeBench.
Task 3: Document Summarization
We asked both Opus and GPT-4 to summarize one of our older technical report where we analyzed which model is best for classification tasks.
We gave the models one simple instruction:
💬 Prompt Please summarize the following document {{ document }}
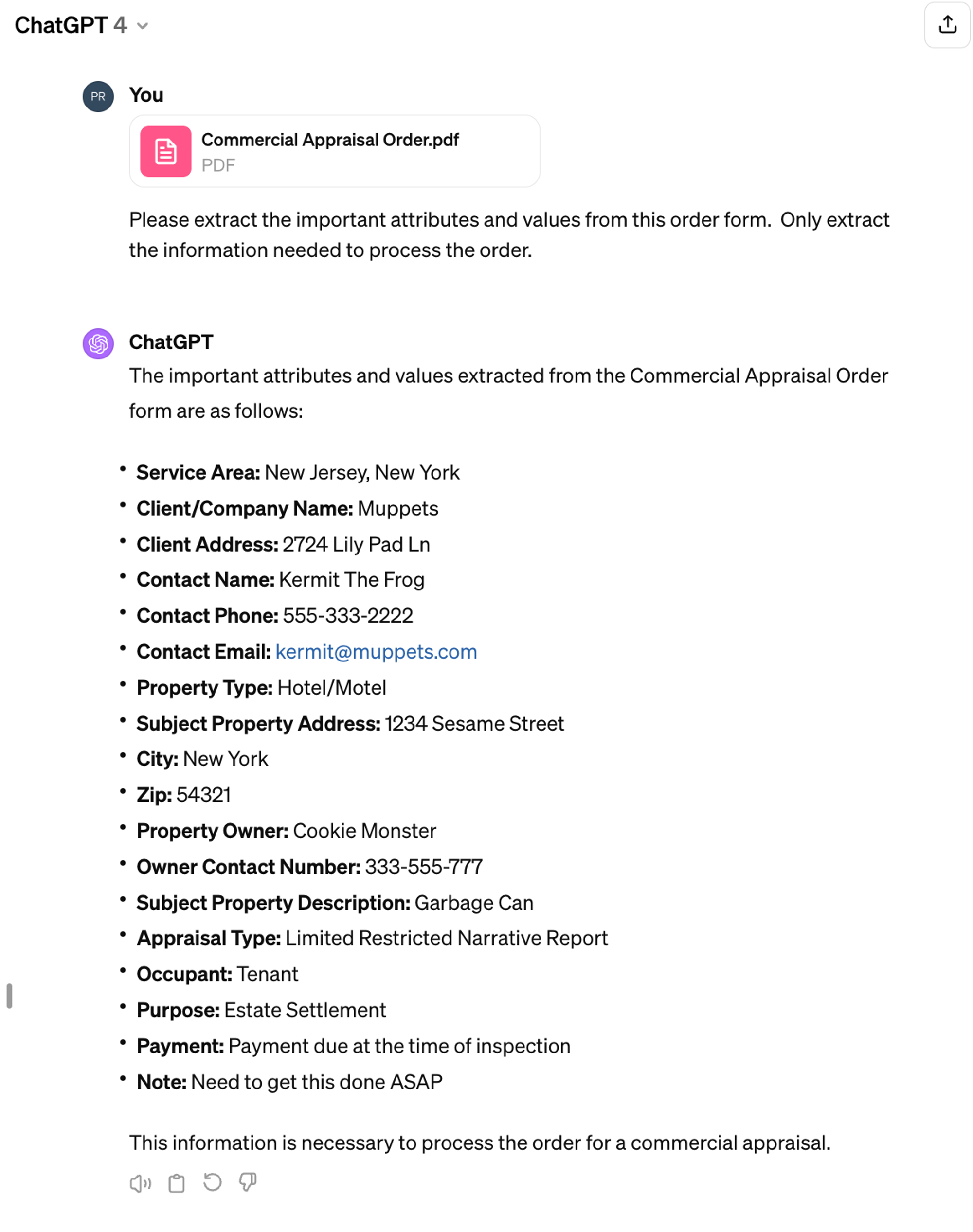
Here is the summary provided by Claude Opus. Notice that the report results were not mentioned, and the summary is high-level:
💬 This document compares the performance of four language models - GPT-3.5 Turbo, GPT-4 Turbo, Claude 2.1, and Gemini Pro - in classifying whether a customer support ticket is resolved or not. The experiment, inspired by the company Pylon, aims to find the best model for this classification task. The document discusses the challenges in classifying customer conversations, such as variability in language, nuanced context, and edge cases. The models were evaluated based on accuracy, recall, and precision across 200 test cases. Gemini Pro outperformed all other models with the highest overall performance across all metrics. The document concludes that Gemini Pro is the best choice for this classification task, with Claude 2.1 being a good alternative, and GPT-4 being suitable for tasks where precision is crucial.
GPT-4, however, made sure to include the results with a bit longer summary:
💬 In an experiment conducted to determine the best model for classifying whether a customer support ticket has been resolved, Gemini Pro emerged as the top performer among the models tested, which included GPT-3.5 Turbo, GPT-4 Turbo, and Claude 2.1. The evaluation focused on accuracy, recall, and precision across 200 test cases. Gemini Pro achieved the highest overall performance with an accuracy of 74% and an F1 score of 76.69%, indicating its balanced capability in identifying true positives and avoiding false positives. Claude 2.1 was noted for its high recall but lower precision, making it a good alternative for classification tasks. GPT-4 Turbo exhibited the highest precision, suggesting its suitability for tasks where precision is critical. The experiment highlighted the importance of selecting the right model based on the specific requirements of the task, such as the complexity of the ticketing system and the desired balance between precision and recall. The findings aim to assist users of Large Language Models (LLMs) in enhancing their customer support operations through informed model and prompting technique selection.
The brief nature of Opus's responses may align with those seeking quick insights, whereas others may prefer a more elaborated analysis that digs deeper into the nuances of the article. The choice between brevity and detail often comes down to personal or professional necessity.
💡 Summarization tasks are generally considered easy for most models nowadays, so Sonnet or GPT4 Turbo would be a great substitutes for this use case.
Task 4: Data Extraction
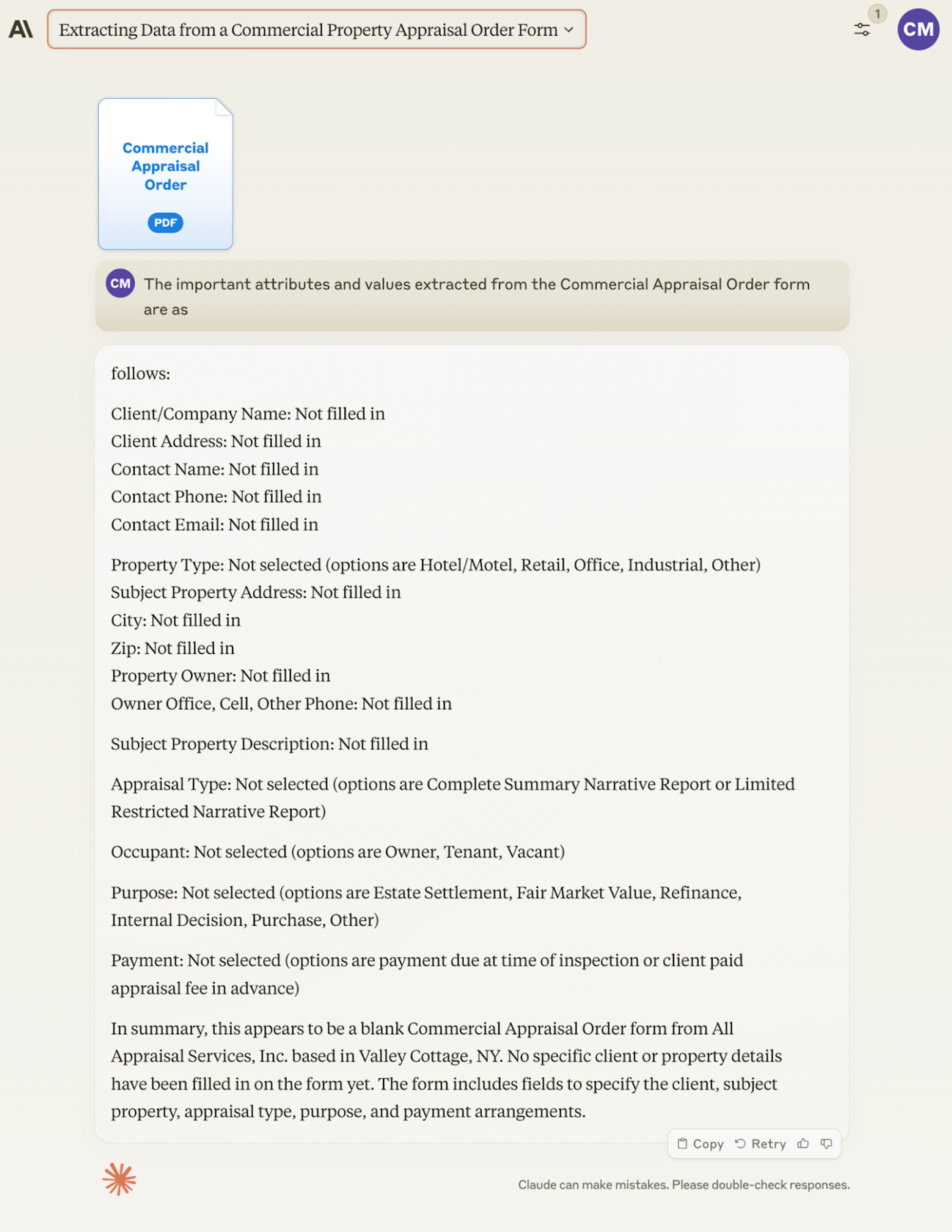
We asked Opus and GPT4 to extract order data from a PDF order form. Opus was surprisingly unable to extract any of the values from the initial PDF we provided. We tried updating and saving the PDF in a couple of different editors thinking there could be an issue with the file. No luck. We took a screenshot of the PDF and Opus was then able to successfully extract the data.
GPT4 did an excellent job extracting data from the PDF on all test runs.
This use case needs more investigation; however given the immediate success with GPT4 one might conclude to continue with GPT4 for this use case.
Here is a screen shot of the source PDF:

Here are the outputs:
Task 5: Heat Map Graph Interpretation
We decided to test the vision capabilities of Opus and GPT4-Vision by asking them to generate insights from a heat map graph . Here we found that both models struggled. Both models seem to be challenged by something we casually coined as the “mirror effect” where the observation might be accurate had it happened on the other end of the data range, as if the models are seeing something backward in a mirror reflection. Opus hallucinated while GPT did not, giving the nod to GPT4 on this test.
Mirror effect - Most of GPT4’s errors seem to be related to the mirror effect. It might say the model retrieval is strong at the top of the document when it is actually strong at the bottom. Sweet Spot - Both models tried to identify a sweet spot in the data. Neither model was successful, yet GPT4 got closer to the correct answer. Hallucination - Opus offered a couple of insights that were completely incorrect, for example finding “For the placed fact document depth, accuracy increases from 40% at 1K tokens to 95% at 118K tokens.”.
Here are the outputs from each model with erroneous info highlighted:


Task 6: Coding
We read through a number of highly-ranked articles and videos. Based on these sources (outlined below), it appears that Opus outperforms GPT4 in certain aspects of programming and coding tasks and that the overall enthusiasm is for Opus over GPT4:
Key Findings:
Opus scored the highest ever on Aider's code editing benchmark , completing 68.4% of the tasks with two tries. This was better than the latest GPT4 model, which scored 54.1% on the single-try performance. Users report that Opus is "much more 'to the point' and seems more 'willing' as opposed to simply backtracking and proposing a completely new solution" compared to GPT4. Opus is better at providing focused, actionable responses for tasks like sorting through documents and generating analysis, compared to GPT-4 which had more irrelevant ideas. Opus has a larger context window which may be an advantage when working with larger codebases.
However, here are some reported limitations of Claude 3 Opus:
It is unable to perform certain coding tasks and will return errors, unlike GPT4. For complex logical reasoning and math problems, GPT4 may still be slightly ahead of Opus.
In summary, the results suggest that Opus outperforms GPT4 in many coding and programming tasks, especially in terms of providing focused, actionable responses.
However, GPT4 may still have an edge in certain areas like logical reasoning tasks.
The choice between the two models may depend on the specific needs and requirements of the programming task at hand and price.
📣 We’ll be performing our own coding evaluation soon. Sign up for our newsletter to get the results as soon as we publish them.
Summary of our Tests and Research
Creating our comparison tests was a rabbit hole for sure. We wanted to learn some things that might be new that we could share with the AI community yet we didn’t want to make this a four-week science project. Even though our tests were lightweight there is something about seeing something in action that brings a lot of meaning even if the test was not “statistically significant” or robust in its design.
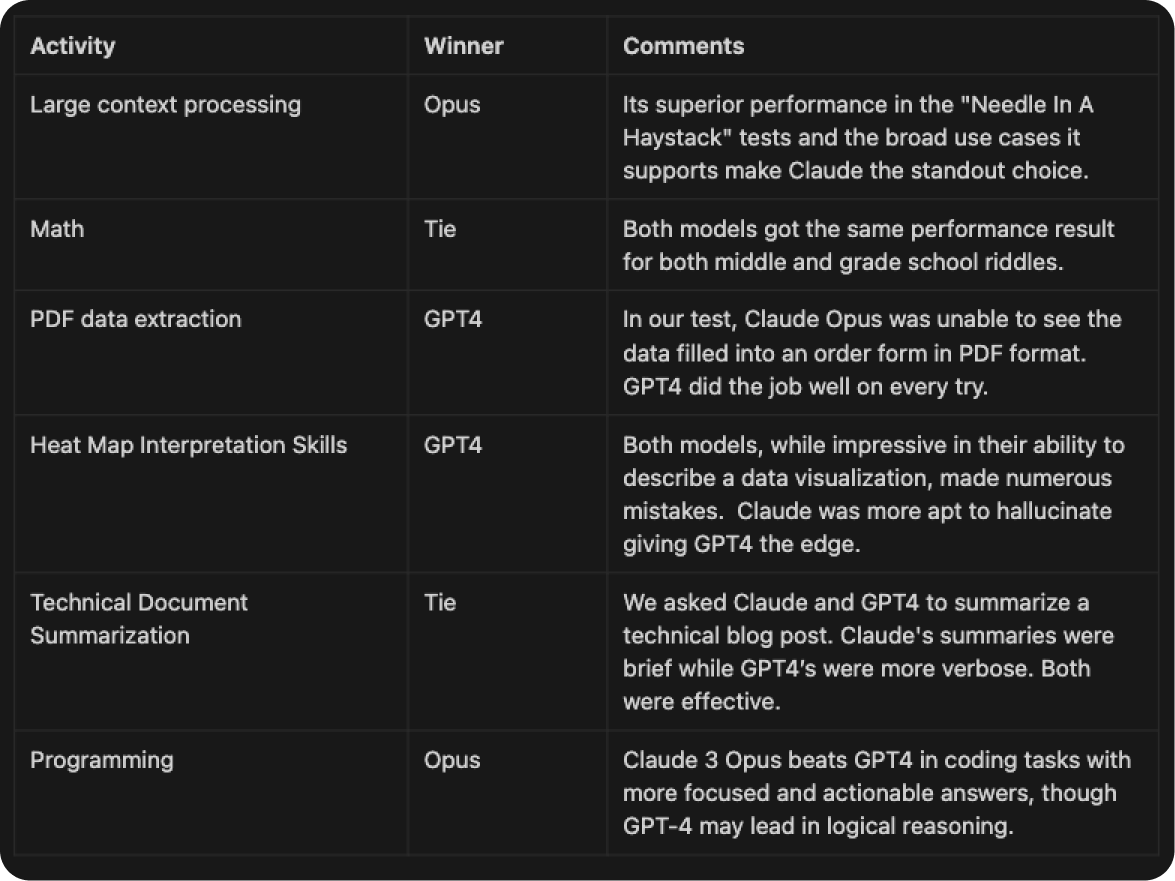
Here is a summary of the tests we ran and our findings:
Prompting Tools and Resources
We encourage you to take the Anthropic models for a drive yourself. Because everyone is so used to the OpenAI way of prompting it's not uncommon to get lesser results due to differences in prompt interpretation across models. The team at Anthropic understands this and has put a lot of effort into their documentation and tooling to migrate your prompts, create new prompts, and learn about prompting in general.
Here are a few highlights to jump start your learning:
Prompt creation tool - Experimental helper "meta"-prompt that can guide Claude to generate high-quality prompts tailored to your specific tasks, specifically for Claud 3 Opus. This comes in the form of a meta prompt Google Colab notebook. You will need your API key. Prompt migration - Guidance on using their console for prompt migration. If you are a Vellum use the Vellum Prompt Playground is a fantastic way to compare your current prompts with Claud or any other model. Prompt Library - Here you can explore optimized prompts for a breadth of business and personal tasks.
Here are some other good resources from the Vellum Blog on prompting best practices:
Prompt engineering guide for Claude Models How can I get GPT-3.5 Turbo to follow instructions like GPT-4? Getting Started with Prompt Chaining GPT-4 to Claude 3 Opus converter
Overall Conclusion
Each model has its strengths and weaknesses.
If you are looking for us to declare a hands-down winner, unfortunately, that is not going to happen!
In the end you are going to have to test these models yourselves on your use cases to see what works best for you. You should define custom benchmarks for your use-cases and evaluate continuously to maintain high results as models can degrade over time.
If you need help to set up your internal benchmarks and tooling to evaluate them across all of your test cases, we can help. Book a demo here , or contact as at support@vellum.ai .