
No matter what you do, the LLM is not following specific parts of your instruction?
It might be time to chain your prompts.
This approach is a highly recommended prompting technique by the entire LLM community and the model providers themselves.
You can achieve very high LLM performance, but what is it really, and how do you do it properly?
Let's dive in.
What is Prompt Chaining?
Prompt chaining involves dividing a complex task into more manageable subtasks. Each subtask is handled by a specific prompt. The output from one prompt serves as the input for the next, creating a sequence of prompts that lead to the final result.
The goal is to break down big tasks into smaller, linked steps and improve the LLM performance.
There are other valuable benefits from prompt chaining like:
Controllability: It’s easier to debug and test each step of the “chain”. Reliability: If something crashes, it’s easier to locate the error and remedy the issue.
You’re in a way trading cost/latency for high quality output, higher control and reliability. However, have in mind that for each of these simpler prompts in the chain you can use cheaper and faster models like Claude 3 Haiku or GPT 3.5 turbo, so the tradeoff might not be as significant.
Use Cases for Prompt Chaining?
Prompt chaining can be used for different use-cases where you’re trying to solve a complex tasks, for example:
Q&A over documents: Where first prompt summarizes the data from context, and the second rephrases it; Validators: Where a subsequent LLM call acts as an evaluator for the previous prompt output; Customer chatbot: Where prompt 1 analyzes ticket, prompt 2 provides a “step by step” thinking, then prompt 3 drafts the response.
Now let’s look at a specific example.
Prompt Chaining Example
Let’s build a simple prompt optimizer tool for Claude 3 prompts.
We'll store our best prompt engineering guides for Claude in a vector database, and use it as context to improve the prompt. Then, we'll add three steps in our workflow: first, we'll search our vector db to retrieve the best advice for a specific prompt; next, we'll use this advice to make a better version of the prompt; and finally, we'll publish an explanation on how we made the prompt better.
Infra
To do this you can use some open-source frameworks , but we’ll use Vellum’s Workflow product to create a multi-step AI app, that will include:
Input fields that collects a user’s prompt and model selection; Vector database that retrieves prompting tips from our guides for a given model; And a chain of prompts, where: Prompt 1 extracts three tips/examples from context that are most useful for given prompt ; Prompt 2 uses the output from Prompt 1 and the original prompt , to generate a better prompt version; Prompt 3 that uses the output from Prompt 1 and generates the explanation on how the prompt was improved.
Building this chain of prompts is very easy to do in Vellum. You just upload your documents into a fully-managed vector store, then define two prompts that will do specific subtasks. Below you can see the implementation in Vellum for this example:
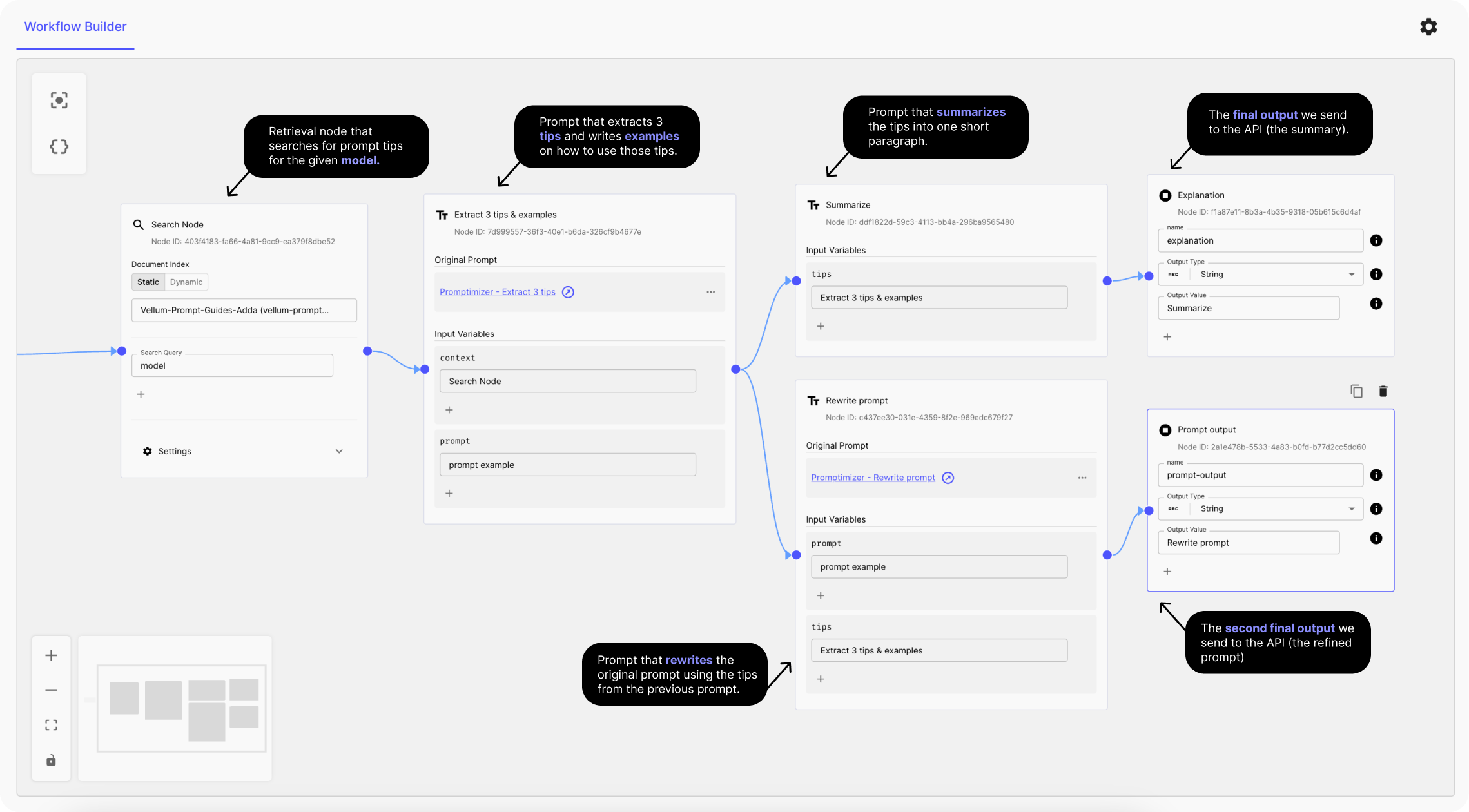
Below is a simple demonstration of how this tool can work for the user. Users can choose a model, paste their prompt then receive a better prompt version, using industry-best practices.
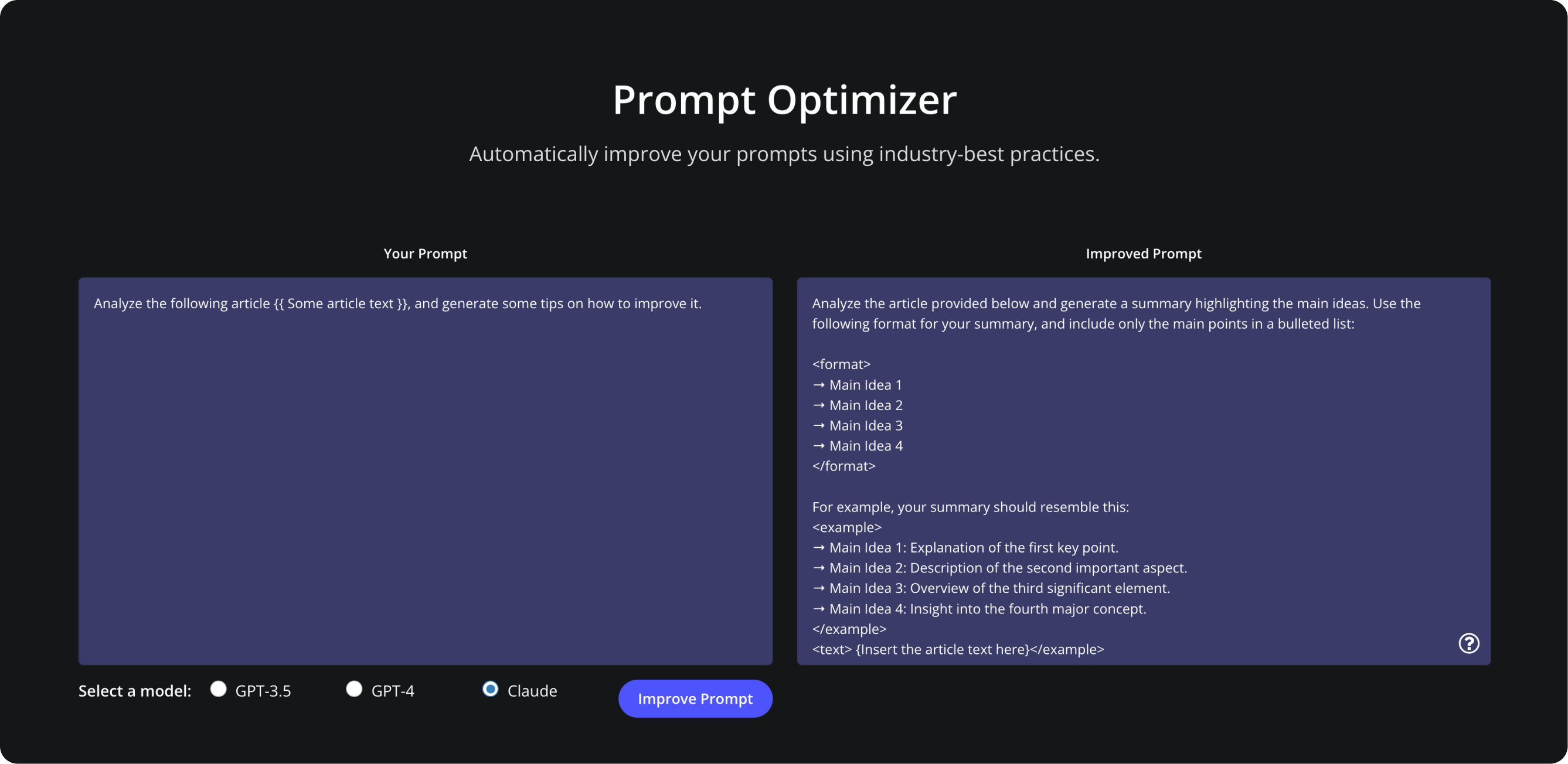
So we basically started with this prompt:
Analyze the following article {{ Some article text }}, and generate some tips on how to improve it.
And the tool generated a refined prompt that utilized one of the most prominent prompt tips for Claude like: use of XML tags, providing format and example (all mentioned in our guide here ):
Please analyze the article text provided below and generate a summary highlighting the main ideas. Use the following format for your summary, and include only the main points in a bulleted list: <format> → Main Idea 1 → Main Idea 2 → Main Idea 3 → Main Idea 4 </format> For example, your summary should resemble this: <example> → Main Idea 1: Explanation of the first key point. → Main Idea 2: Description of the second important aspect. → Main Idea 3: Overview of the third significant element. → Main Idea 4: Insight into the fourth major concept. </example> <text> {Insert the article text here}</example>
When to use Prompt Chaining?
Use prompt chaining when dealing with complex problems that can be divided into simpler steps. This method is great when a large, vague issue can be split into more manageable parts, making it easier for the model to handle, enhancing accuracy, and reducing errors. It's also useful when you want to double-check a model's response for correctness, especially if there's a concern about the model providing incorrect information.
However, avoid prompt chaining if there's no clear way to break down prompts into steps, if the model is hallucinating due to a lack of context on the topic, or if you need to maintain fast response times, as prompt chaining can introduce delays.
Prompt Chaining with Vellum
At Vellum, we’ve worked with more than 150 customers who have created complex multi-step AI apps, and scaled them to handle more than 3M monthly requests.
If you want to improve the LLM performance of your app, and think prompt chaining is a good fit after reading this post — let us know!
Book a demo call on this link , or reach us out at support@vellum.ai
Here are some other interesting resources:
How to setup OpenAI function calling? How to get GPT-3.5 to work as GPT-4 with prompting? How to prompt Claude 3 models?






