If you're here, you probably know how tricky working with PDF data can be. Here are a few common issues:
It’s difficult to parse with code; Even when you use a good library, you’ll quickly find that you need a separate library to read table data (like tabula-py ) Even when you use a good library for reading table data, you may end up needing to work with tables that have pretty wonky formats (see what we mean with our examples below)
Even if you finesse all of the above, you’re still assuming that your PDFs will have consistent formats.
That’s a big assumption!
In this article, we’ll show you how easy it is to work with PDFs in Vellum by converting a few example PDFs into CSV files.
By the end of this article, we’ll have converted three PDFS: an invoice, restaurant menu and a product spec document.
Let’s dive in!
What data are we working with?
In this demo, we’ll show 3 common PDF use-cases:
A product spec A restaurant menu An invoice
For each of these pdf documents, we need to solve for different challenges. Let’s quickly go through each example.
Sample Restaurant Menu

When working on data extraction for a menu, things can get tricky, especially with the layout. Notice some complexities in this example:
Two columns: The extraction method needs to read items and prices across the columns, not down, to avoid mismatching them. Whitespace between items and prices : The large gap between the menu item and its price can cause traditional scraping methods to misinterpret the layout, reading items and prices out of order (e.g., "Chocolate Cake, Vanilla Ice Cream, <price1>, <price2>" instead of matching each item with its correct price). No need for the footer: A footer that we’d need to manually ignore if we were scraping this with code
Sample Product Specification
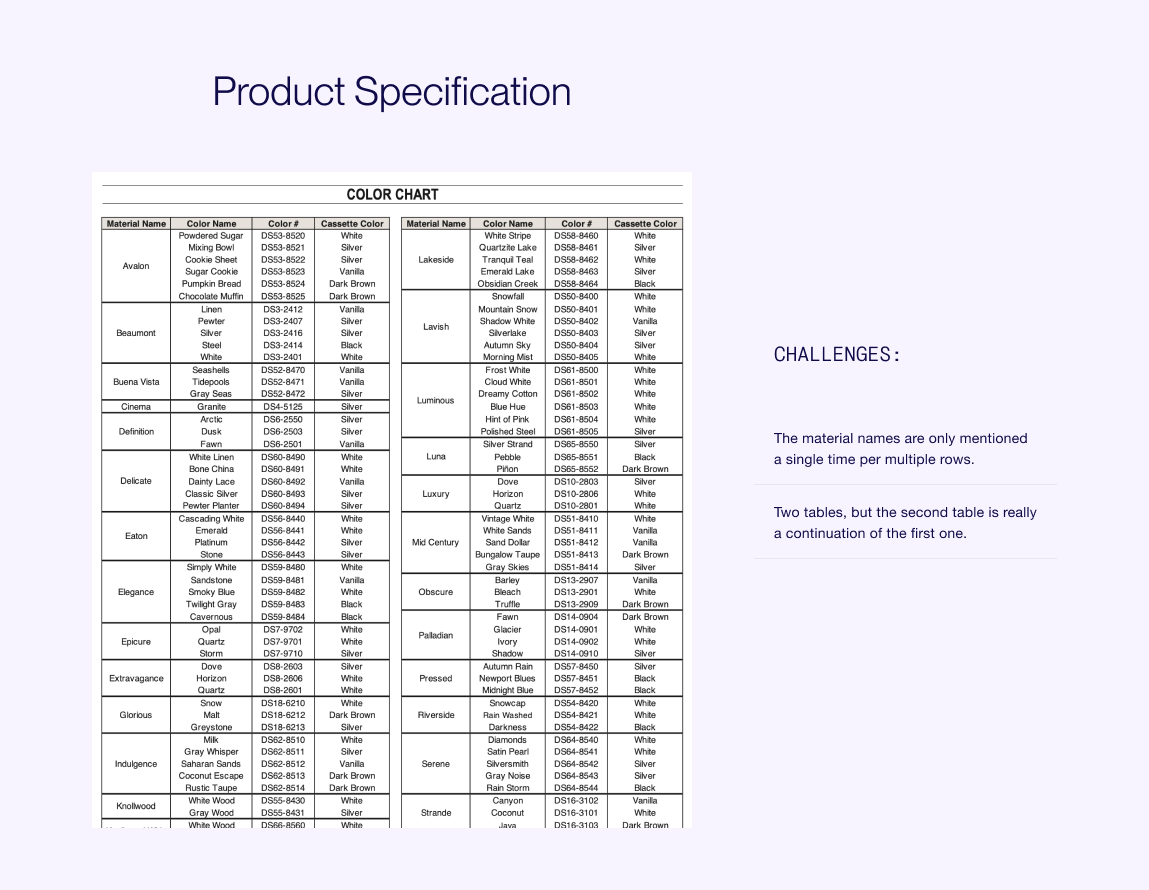
Here are some factors that can complicate the data extraction for this example:
Material Names: Each material name is listed once but applies to several rows, so extraction needs to recognize this connection. Two Tables: The second table is just a continuation of the first, so they need to be treated as one during extraction
Sample Invoice
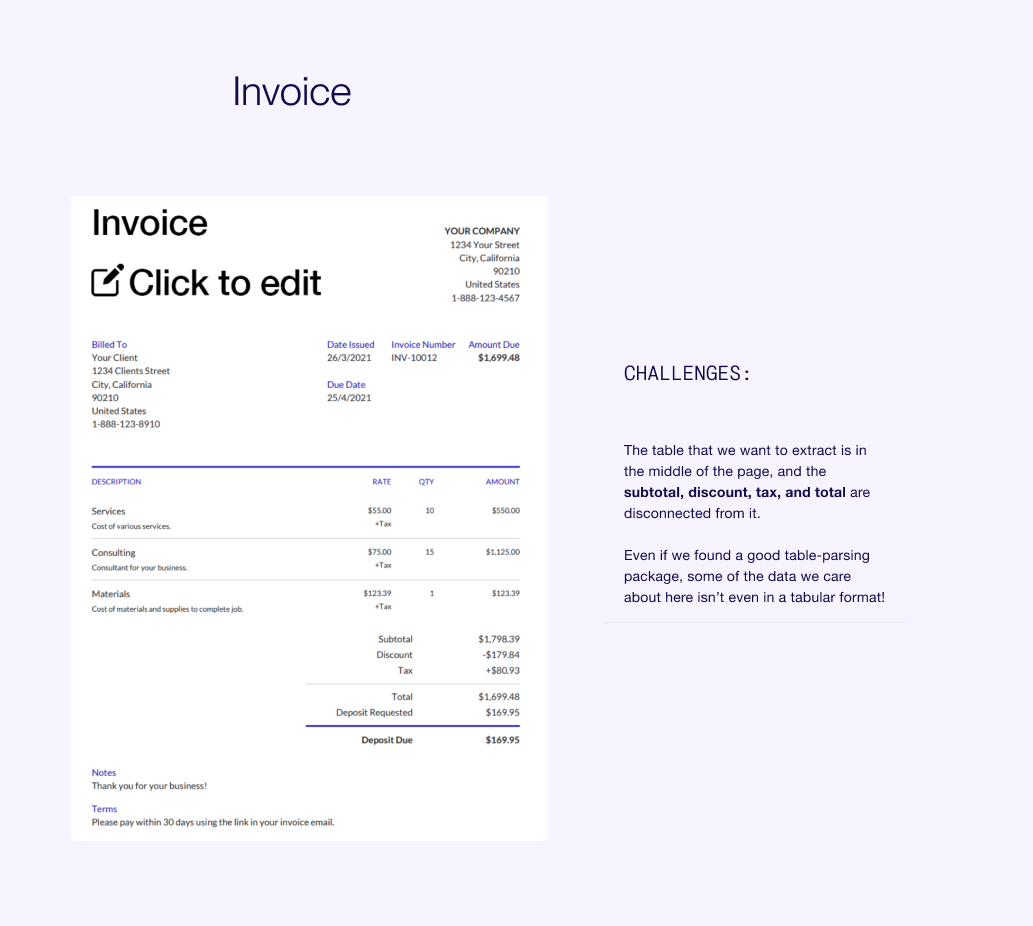
Notice some complexities in this example:
The table that we want to extract is in the middle of the page, and the important totals (like subtotal, discount, tax, and total) are disconnected from it. Even if we found a good table-parsing package, some of the data we care about here isn’t even in a tabular format!
Ingesting with Vellum Document Indexes
One great aspect of Vellum is that it’s built for rapid prototyping and large-scale production. Let’s see how it works.
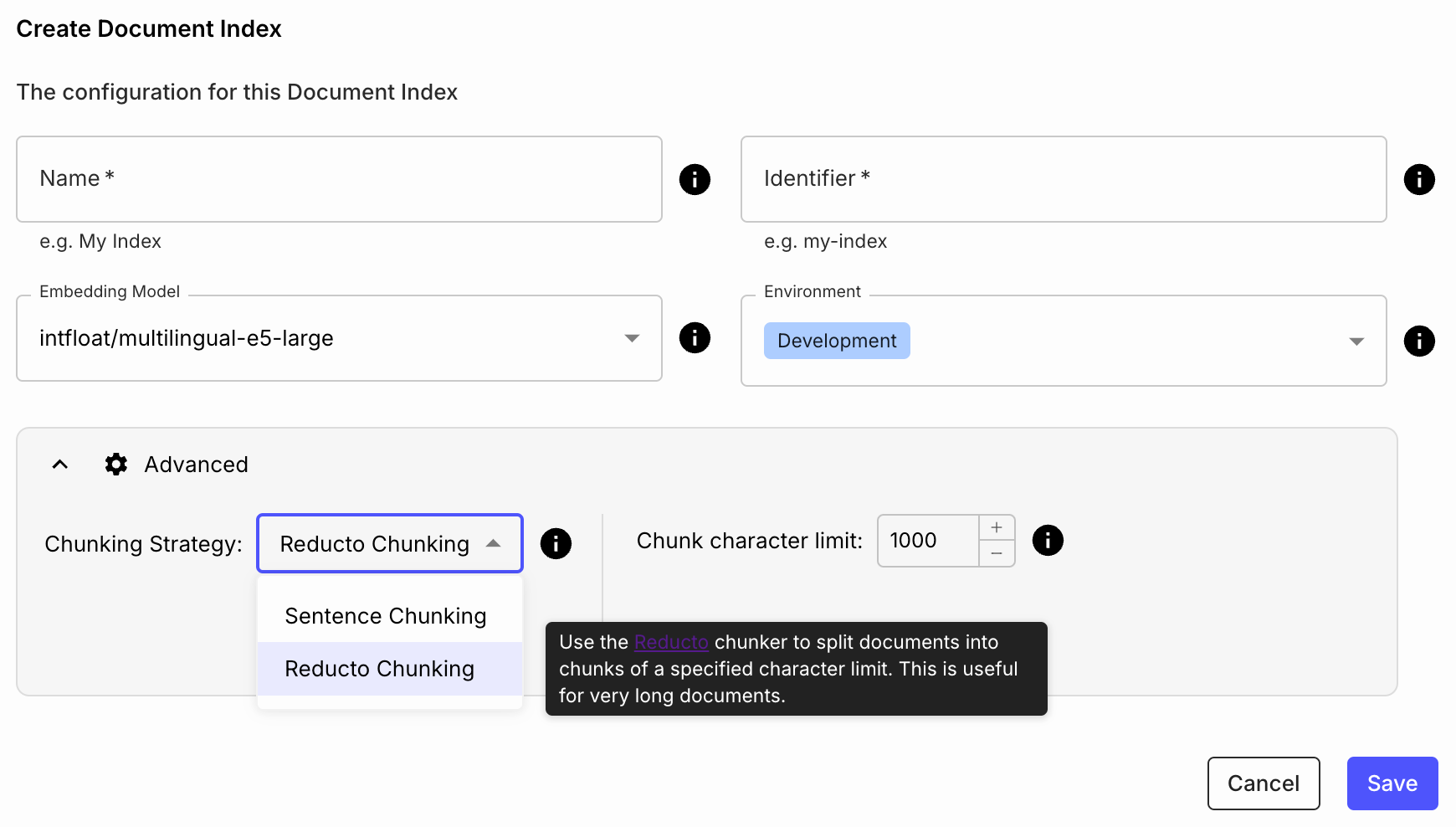
First we’ll create our Document Index using Reducto Chunking. This will be where we store and process our PDFs.
What is Reducto Chunking, you might wonder? Reducto is a great product that specializes in processing complex document data, like PDFs and spreadsheets. Using it in Vellum is as simple as choosing it from this dropdown or specifying it in an API call. We’ll see how powerful it is in the next section.
Rapid Prototyping
Here, we drag and drop our 3 files so we can let AI work its magic and then experiment a little with the results ✨
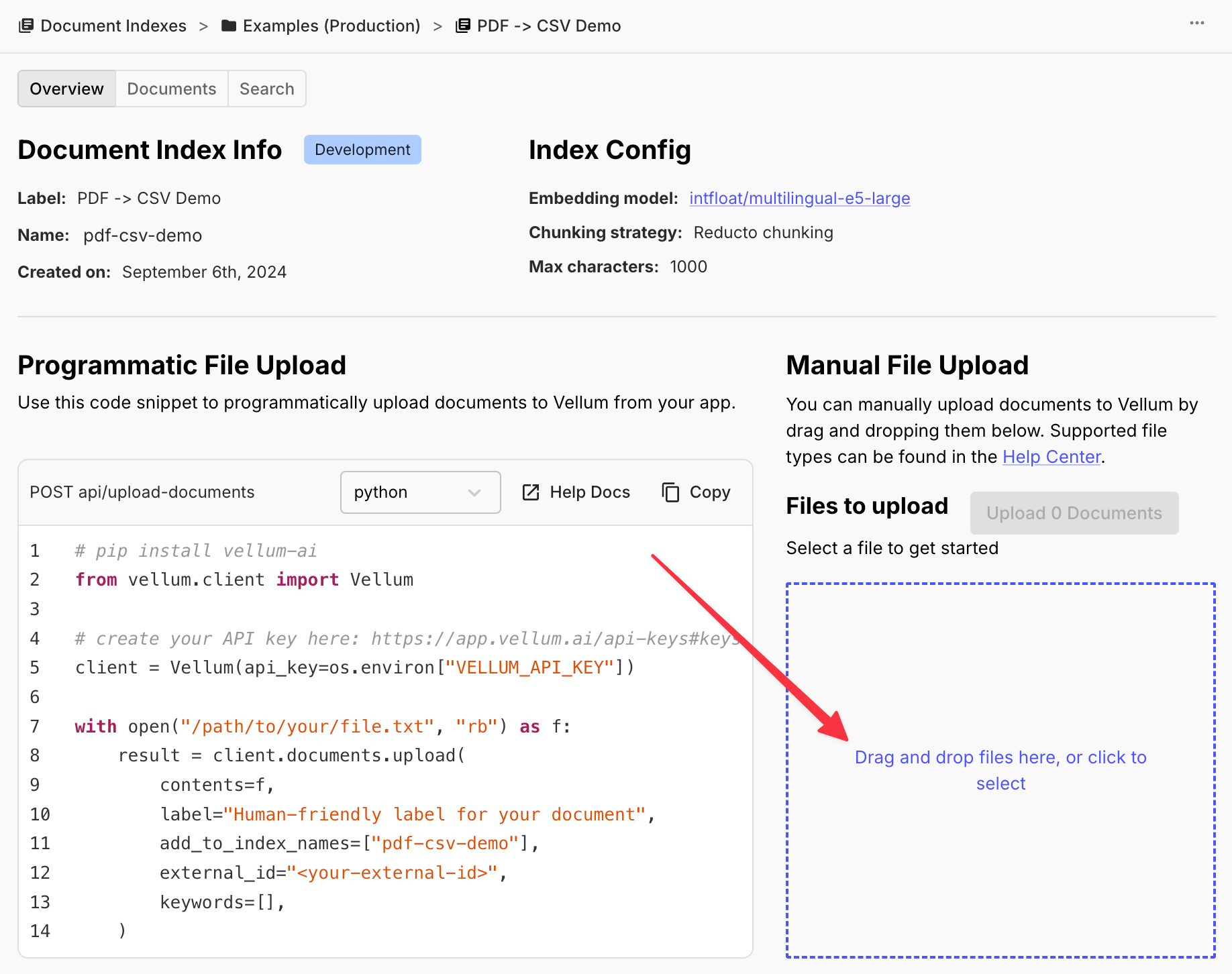
Next we’ll head over to the “Search” tab. Let’s search for some keywords in our product spec PDF to see how Reducto processed it.
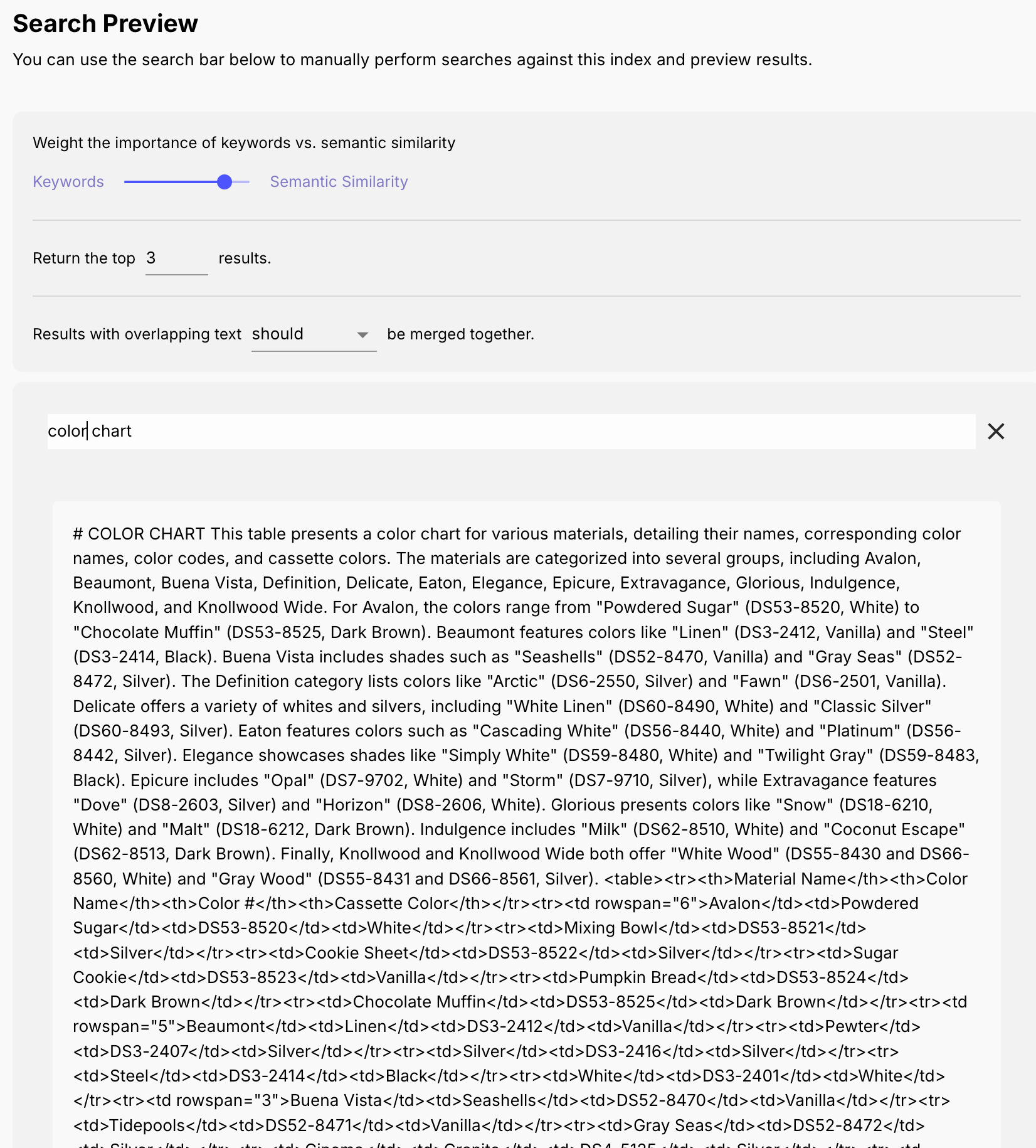
Notice two special things that Reducto did:
Created structure and formatting. The # COLOR CHART is a markdown heading, and all of the <table><tr><td> is structured formatting around the table data. LLMs love this! Created a summary of the table: "This table presents a color chart for various materials..." . Again, super helpful for LLMs to make sense of everything on this page!
Production
Obviously the drag-n-drop interface would be infeasible at production-scale. Fortunately, we have an API for this (with Python, Go, and TypeScript SDKs).
See our Document Index API Reference for more info.
Using Workflows and Prompt Nodes
Now that we have a way to make sense of our data, let’s start working with it in a Workflow.
You can explore a live preview of our Workflow below:
Click to Interact
×
^ If you want to interact with this workflow on a bigger scree, try this link.
But now, let's go step by step of what we did in our Workflow.
The Workflow: Explained
First we set an Input Variable in our Scenario to test with. This value will hold the names of the files we want to parse.
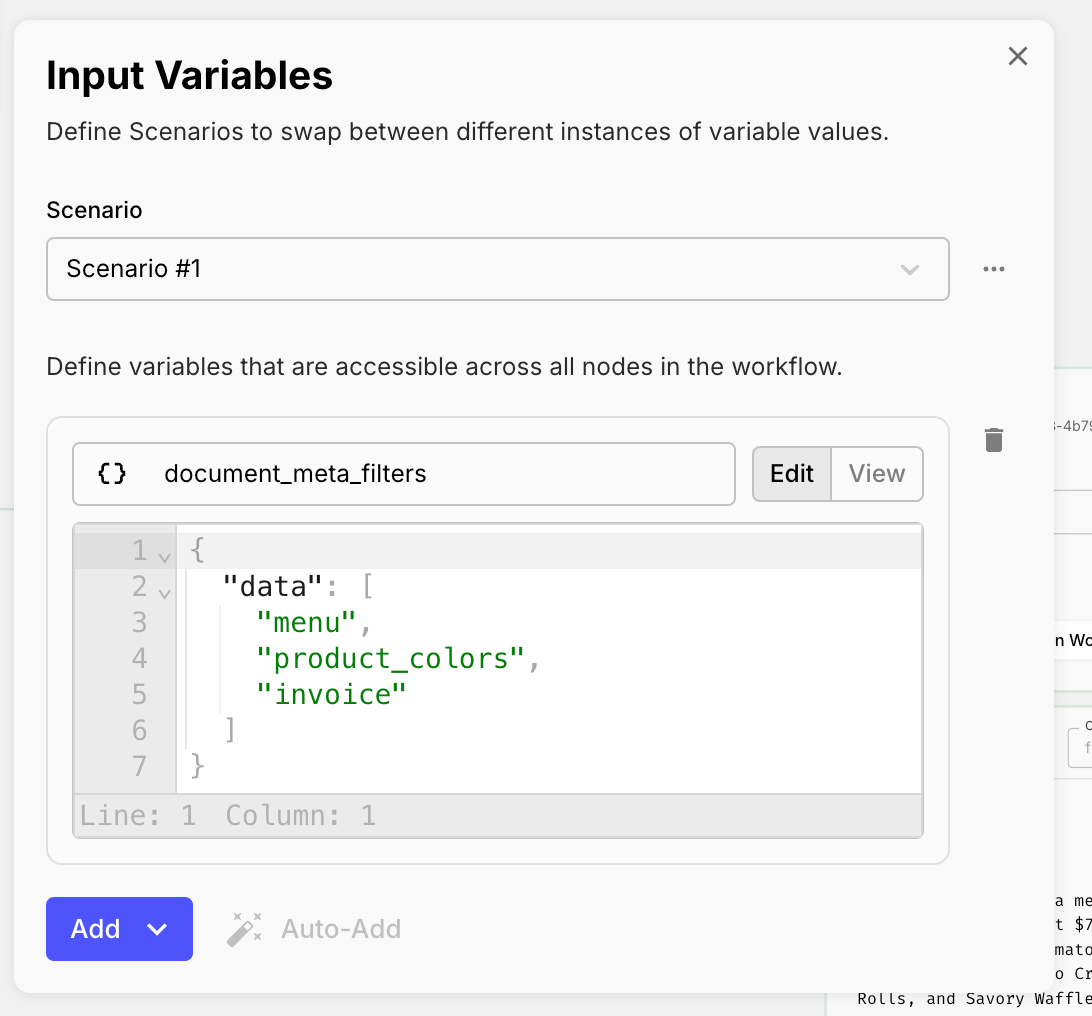
Next, we set up a Map Node to process each file in the list in parallel through a Subworkflow.
At the time of writing, we could run up to 96 Subworkflows in parallel!
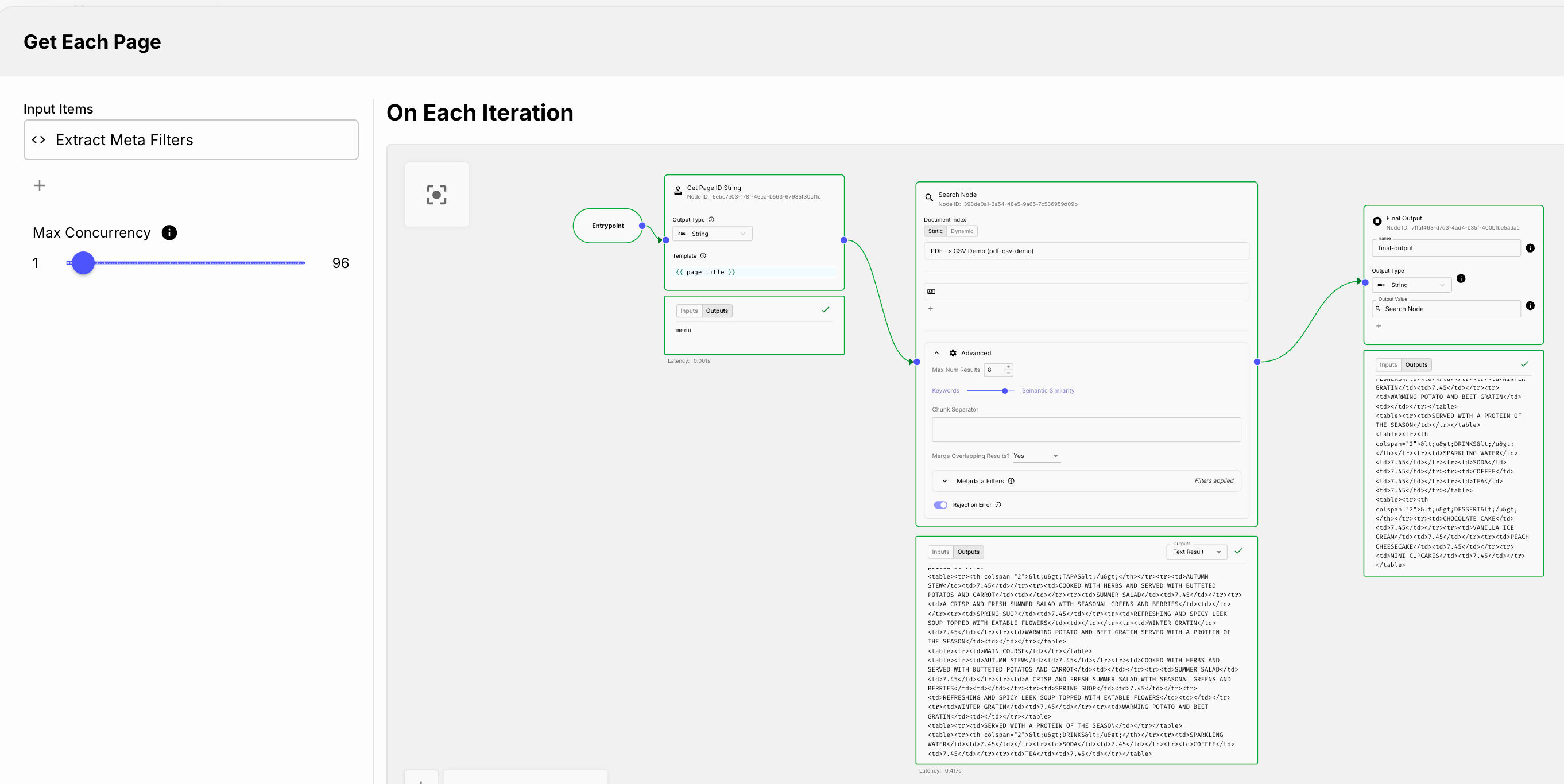
We add a Search Node and use Metadata Filtering to pull the files we’re looking for.
For quick debugging & demonstration purposes, we’ll split this into 2 Subworkflows so we can easily look at the results of each step.
We then use a Code Execution node to translate the outputs of the Map Node into a format that the next Map Node will accept.
Then we pass the data to the next Map Node, titled “Convert Each Page to CSV.”
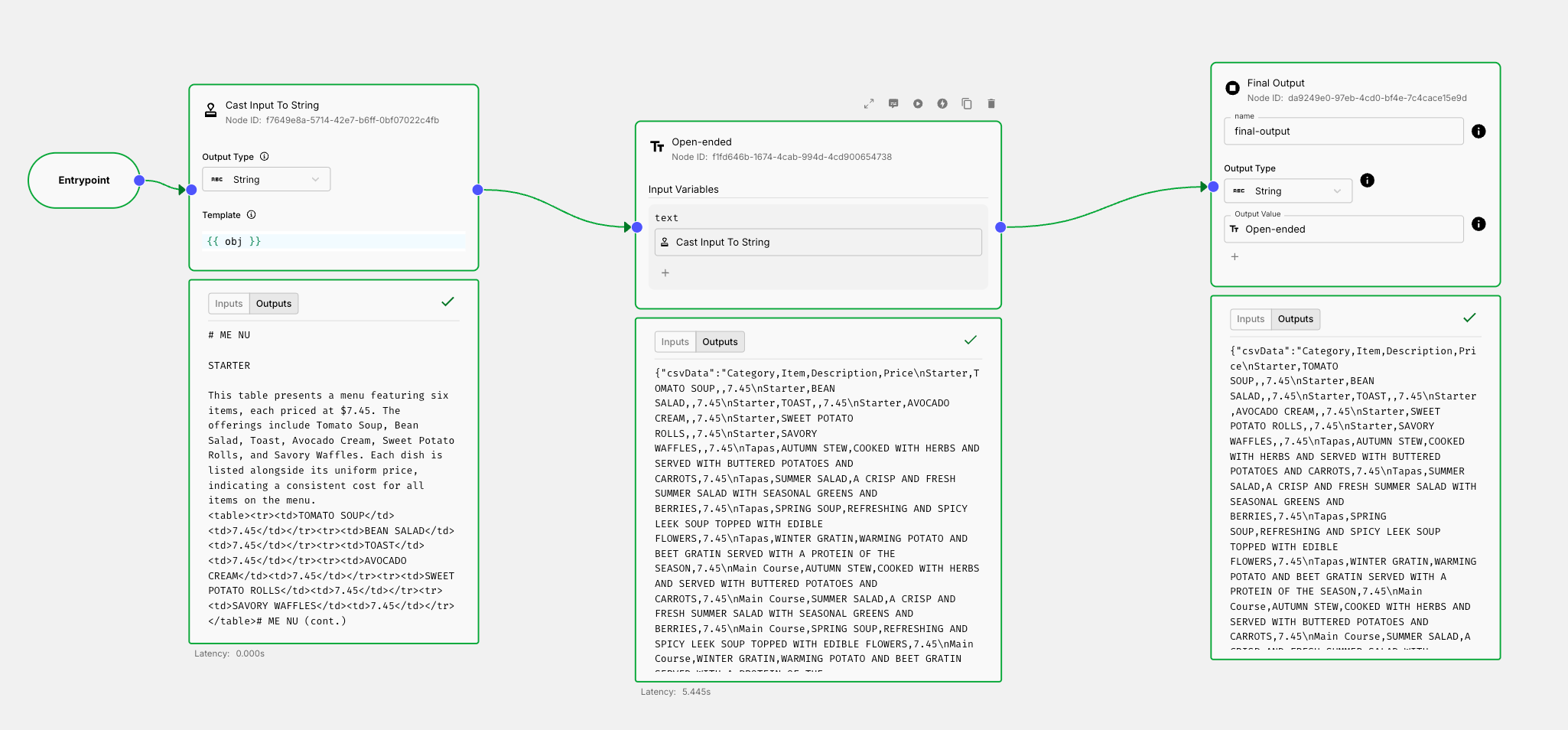
In this Map Node, we primarily have a single, very generic Prompt Node that works well for all 3 of the PDF types that we’re going to pass. The prompt is as follows:
Process the following unstructured text data and convert it into a CSV with sensible columns based on the data you see in the sheet.
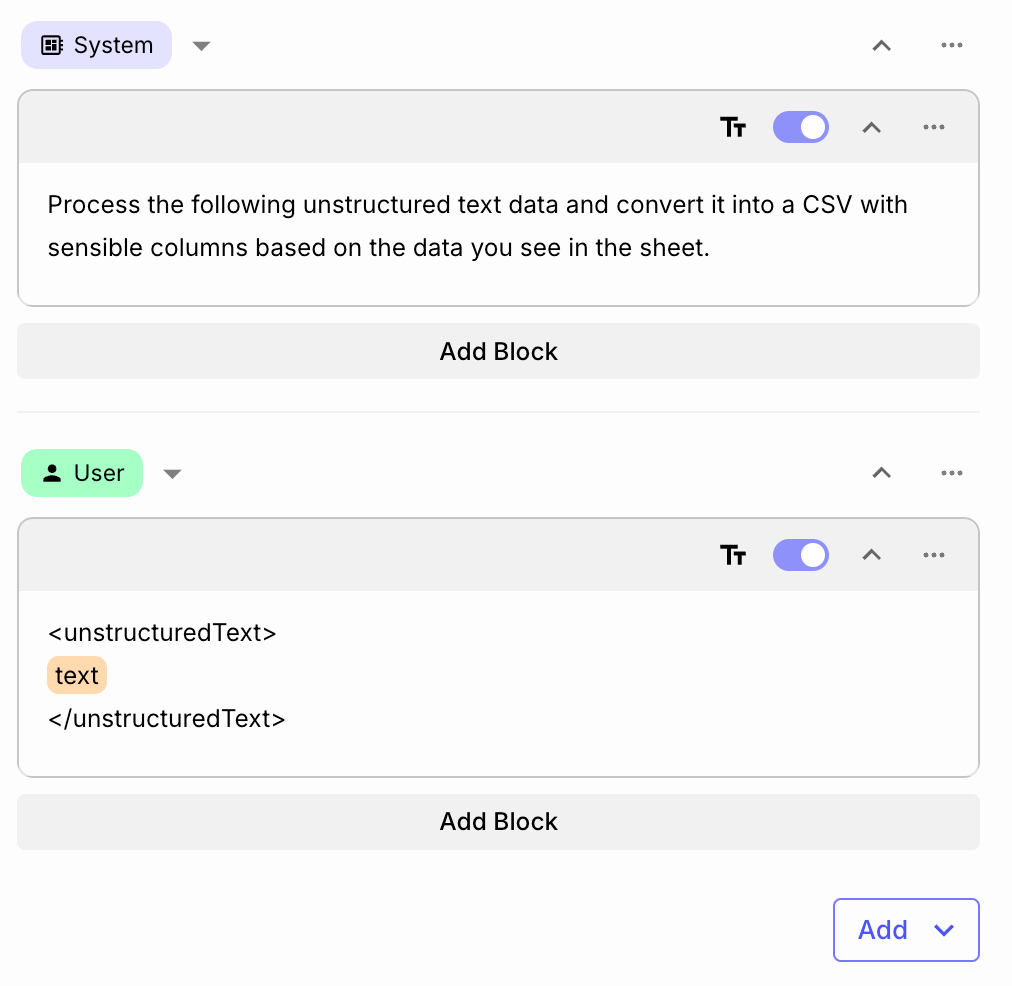
But, we have one more trick up our sleeve. We also leveraged Structured JSON Schemas currently available on GPT-4o models.
Take a look below:
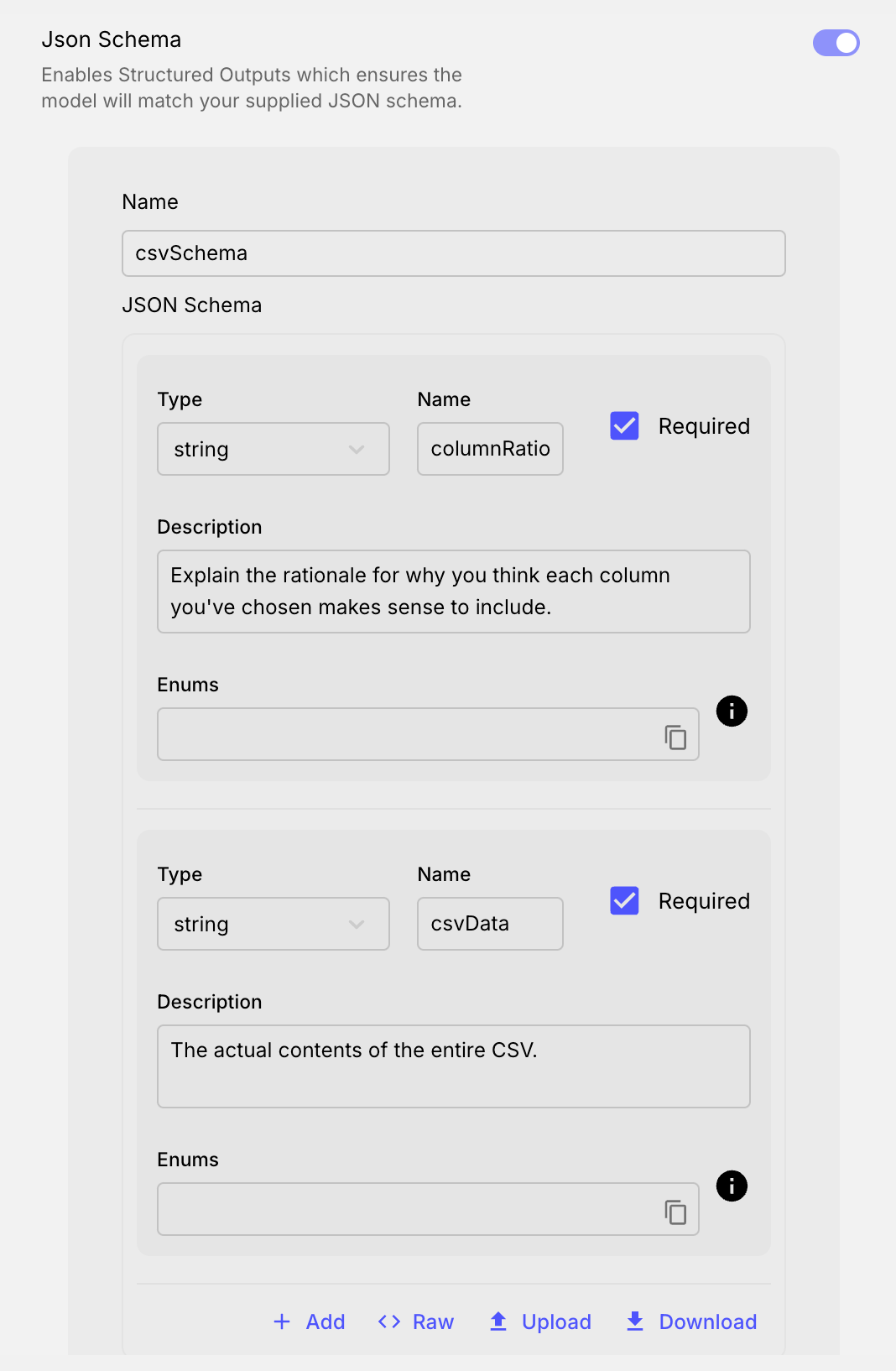
In this schema, we use a concept called Chain of Thought Prompting to help further improve the quality of our results.
We did this by introducing a field called columnRationale where we ask the LLM to explain which columns it thinks should be included before creating the CSV. This is more useful for our Invoice Example which has inconsistent columns depending on the portion of the PDF you’re looking at. In a real-world example where you might only be looking at PDFs, we could be more specific with our schema specification for that use-case.
That’s it! The rest of the magic comes from the context that we get from our Search Node. And the remainder of the Workflow simply extracts each of the examples generated in the Map Node so they’re easier to see and copy/paste via Final Output Nodes.
Conclusion
In this article, we used a single Document Index with Reducto Chunking, alongside a few Map Nodes and Prompt Nodes to process each sample document in parallel, and output reliable CSV-formatted content that we could use as we please. We also covered a few features that make both prototyping and production usage in Vellum a piece of cake.
Have a use-case you want to explore with us? Reach out here !






