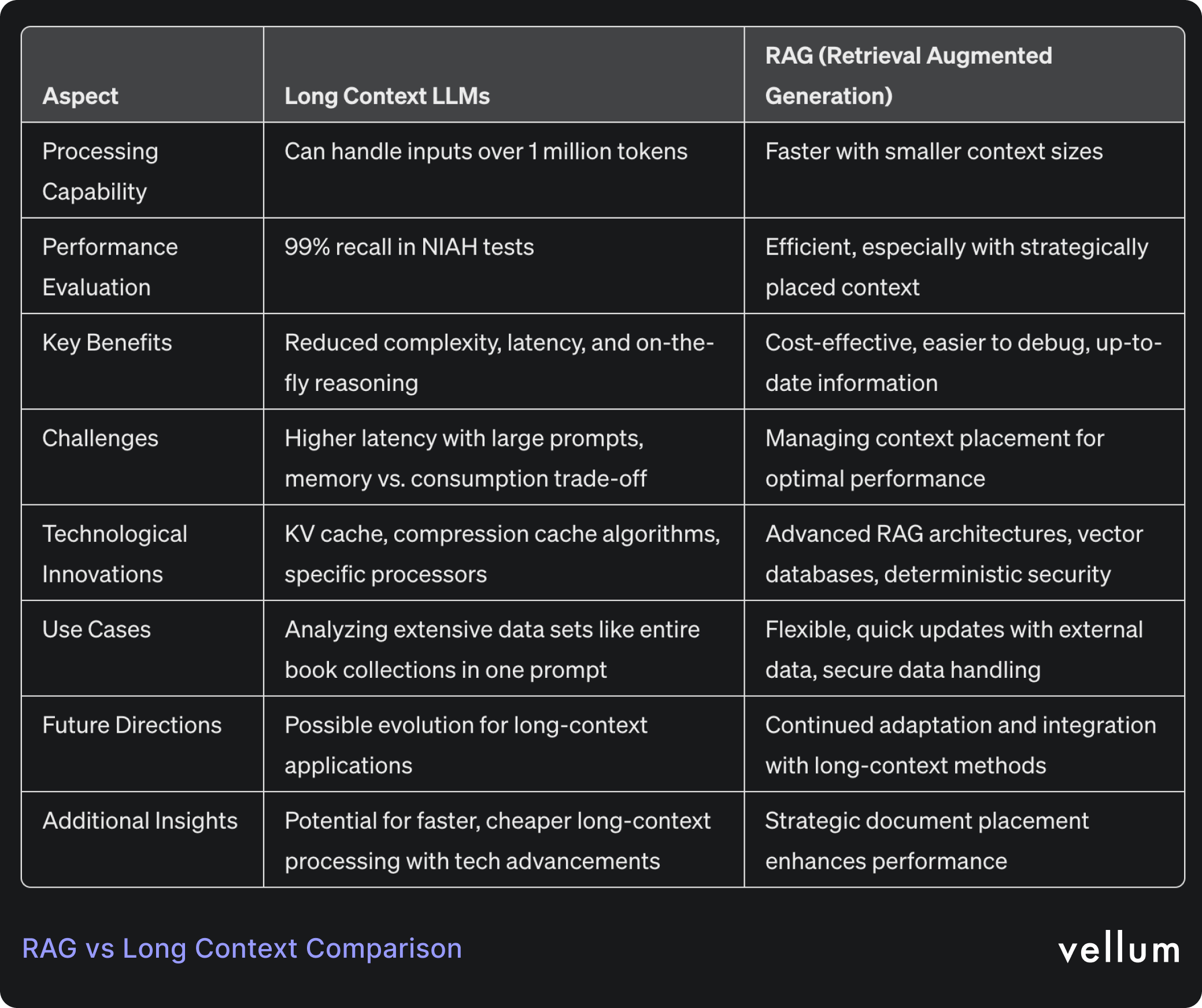
Google and Anthropic released models ( Gemini 1.5 Pro , Claude 3 ) that are capable of accepting inputs that exceed 1 million tokens*. Both models maintained high level of performance as their context window increased, having impressive 99% recall in the Needle In A Haystack (NIAH) evaluation.
To put things into perspective, a context window of 1 million tokens could analyze the entire Harry Potter collection in a single prompt.
This stirred a lot of discussions on AI Twitter, and we wanted to write a summary of the debate plus provide our insiders take. We believe that RAG is absolutely here to stay, but the architecture will evolve to accommodate long-context use-cases when needed.
We hope that this blog post will help you understand the landscape and easily evaluate which approach fits your current use-case.
The Case for Long Context LLMs
There are some challenges that long-context LLMs can solve today:
On-the-fly retrieval and reasoning
Long context enables ongoing retrieval and reasoning at every stage of the decoding process, in contrast to RAG, which conducts retrieval only initially and then applies it to subsequent tasks.
By putting all the data into a long context, the LLM can more easily understand the subtle relationships between pieces of information.
Reduced Complexity
One big benefit from long-context is that developers won’t pull their hair out over what combination of chunking strategy, embedding model, and retrieval method they’ll need to use.
Developers can consolidate much more or even all of their data into a single, lengthy prompt and rely on the (reported!) nearly perfect recall capabilities of LLMs to obtain accurate answers.
Reduced Latency
Simplifying AI workflows leads to fewer prompt chains and less delay. But it's unclear how much this will help right now, because long context prompts can still cause a big spike in latency.
We anticipate that new methods will make longer context prompts faster and cheaper, leading us to the next section.
Long context can be faster, cheaper with better caching
Large language models use KV (Key-Value) cache as its memory system to store and quickly access important information during inference. This means that you can read the input once, then all subsequent queries will reuse the stored KV cache.
With KV cache we trade memory against consumption, which imposes another challenge that can be very costly.
However, researchers are starting to test new compression cache algorithms to serve models such as LLaMa 7B with 10 milion tokens, on an 8-GPU serving system. We'll see a lot more innovation in this area, which will make long context queries much faster and more cost-effective. Another area is building new processors designed specifically for LLM applications such as the LPU Inference Engine by Groq.
The Case for RAG (Retreival Augmented Generation)
Developers are continuously building advanced RAG architectures, and this approach continues to be the number one choice for many of them because:
RAG is Faster and Cheaper
Attempting to process a 1 million token window today, will result in slow end-to-end processing times and a high cost.
In contrast, RAG is the fastest and cheapest option to augment LLM models with more context. Beyond naive RAG , developers and researchers have built many complex RAG architectures that optimize every step of their systems making it a very reliable architecture for their use-cases.
Easier to debug and evaluate
If too much context is provided, it's challenging to debug and evaluate whether a hallucination happened based on context or unsupported content.
Using less context per prompt offers a benefit in terms of explainability, because developers can understand what the LLM relied on to formulate its response.
Even with the maximum input size today (200K) model providers recommend splitting prompts and chaining them together for handling complex reasoning tasks, and we don’t see this changing in the near future.
Up-to-date information
When developers use RAG, it’s pretty easy to serve the model with up-to-date information from wherever they store company data. Leveraging tools like vector databases or external calls allows the LLM to generate informed outputs, making it essential for numerous current use cases.
Can solve for Lost in the Middle (LIM)
Recent research indicates that performance peaks when key information is at the start or end of the input context, but drops if relevant details are mid-context. So to achieve best performance, developers should strategically place the most relevant documents at the start and end of the prompt, a task that can be very manual/complex if done with the long context approach.
RAG can simplify this process; they can select any retriever, fetch the top N similar documents, then employ a custom reranking function to reorder the results, positioning the least relevant documents in the middle.
Deterministic security/access privilege
Apart from building the best architecture, developers are thinking of building safe and reliable AI apps. By employing deterministic mechanisms in the chain, RAG allows for precise control over who can access what information, ensuring confidentiality and integrity of sensitive data.
This is one of the most important reason why RAG will continue to be the first choice for many production-grade applications.
Beyond RAG and Long Context
Retrieving data from a vector store and parsing that through an LLM call is just the beginning. RAG is here to stay and it will adapt to many new use-cases, and we might see a future where developers will be using a mix of long-context + RAG in their implementations.
Our goal at Vellum is to enable developers to easily start, build and deploy production-ready AI apps, and our mission goes beyond just RAG or long context.
Building a reliable AI system requires so much more, and we wrote about it here.
There is a growing demand for robust evaluation, monitoring, continuous improvement, and tracing capabilities to inform decision-making, and we are committed to developing all the necessary tools to meet these needs.
If you’re on the lookout for the best framework to develop and evaluate production-ready AI apps — we can help!
If you’d like to learn more on how to build your LLM workflow with Vellum, book a call here , or reach out to us at support@vellum.ai . - *Claude 3 and Gemini 1.5 Pro models are currently limited to 200K characters, and only selected developer accounts can use the 1 Million token ability.