At Vellum, we’re all about giving our customers the best support because we know AI development isn’t easy. It takes a lot of trial and error to build a reliable system, and we’re here to help you navigate that process.
But finding answers quickly can be tough. Even though we work hard to keep our documentation up-to-date, our fast-moving engineering team sometimes gets ahead of us. This means our documentation can become outdated quickly, and we might need a bit more time to check with them to give you the most accurate support.
To make things easier, we decided to keep our documentation in a vector store and use AI to help us quickly find answers for our customers right in Slack.
This is a perfect use-case for using embedding models, but this approach doesn’t solve our initial problem — how can we provide an answer if it’s not logged in the documentation?
While there’s no easy solution to this chicken-and-egg problem, thinking about it beforehand and planning for the future can help. If we proactively store question-and-answer pairs from our Slack conversations, we’re setting ourselves up for success — this way, when the same question arises again, we’ll have the answer ready.
To address this, I built a simple Slackbot that listens to specific channels and records user questions and our answers when we react with certain emojis. This way, we can capture and reuse all these conversations to help with future user queries!
I built this Slackbot in just an hour, thanks to Zapier, Vellum & Airtable.
More details in the next sections.
How it Works + Demo
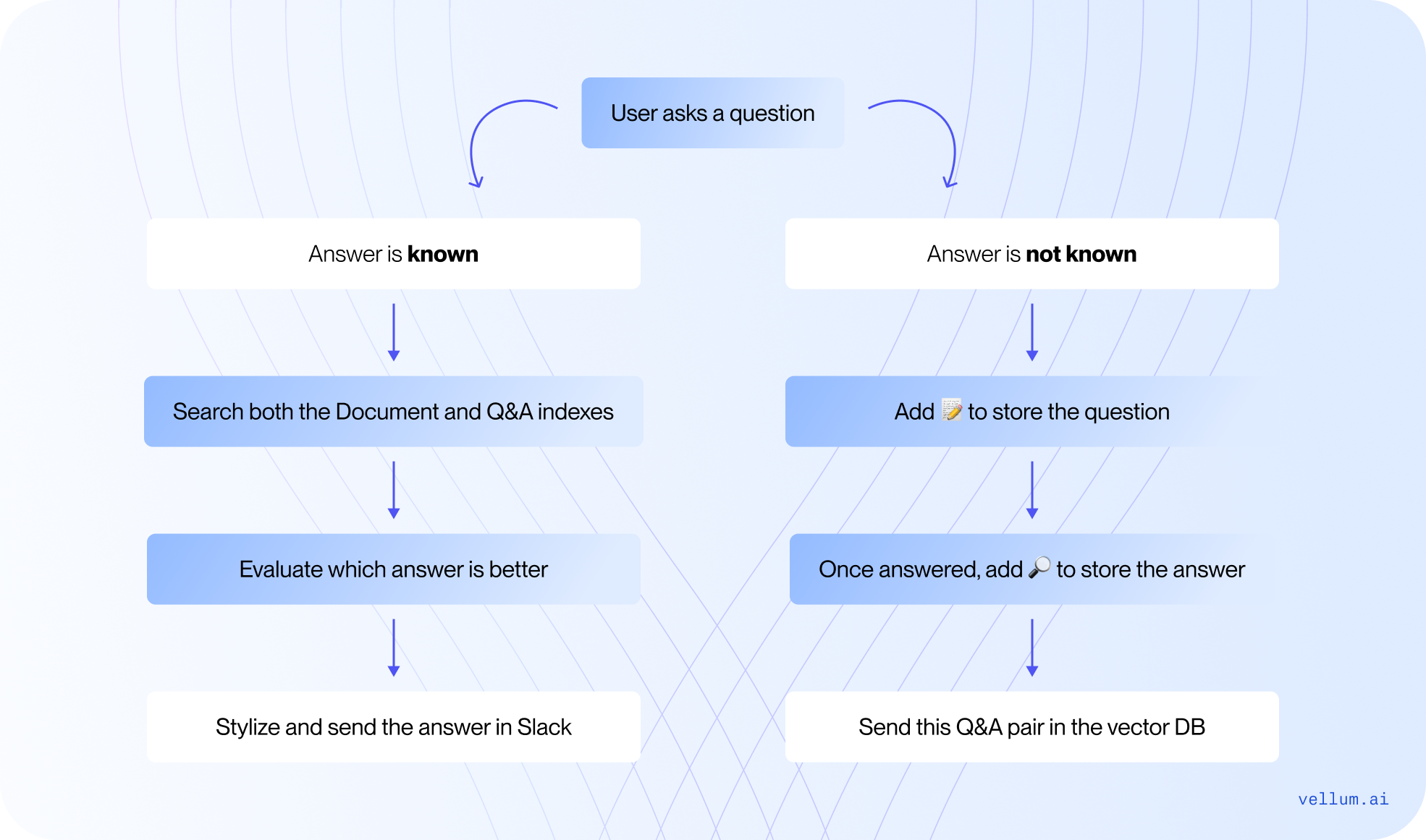
I’ve uploaded our docs and previous Q&A pairs into separate indexes in a vector database. Now, when a user asks a specific question, it searches both indexes, determines which one has the best answer, and posts it in the Slack channel, including the source (yes, it cites the sources too!).
Here’s a high level overview of the workflow :
Indexing : I’ve uploaded our docs and previous Q&A pairs into separate indexes in a vector database. Query Handling : When a user asks a specific question, the system performs a search and evaluates which answer should send in the Slack channel. Updating the Index with New Q&A Pairs: If the bot doesn’t have an answer, our team tags the question and the provided answer with specific emojis. This automatically logs the Q&A pair in our vector store and Airtable! Future Queries : The next time the same question is asked, this AI workflow will search the vector database (including both documentation and Q&A pairs), rank the best answer, and provide it quickly.
I’ll show the exact steps and our process in the next sections — but here’s a quick demo on how it works!
Into the Weeds
The whole process relies on three Zaps, one Vellum AI Workflow, and one Airtable document! Before I set up this automation, I uploaded all of our current documentation in a vector database.
Initialize
I have a total of three Zaps that capture the interactions in our Slack channels:
Velly Responses: Monitors specific channels for questions and replies in the thread. Question: Waits for a 📝 emoji to record a user question from Slack into Airtable. Answer: Waits for a 🔎 emoji to record the answer in an Airtable document.
I wont bother you with the details of how these Zaps are set up, because you can find a lot of documentation on that on Zapier!
Search
The RAG-based workflow is triggered by the Velly Responses Zap. Once activated, it performs the following steps:
Searches the documentation vector index for the answer; Looks up our vector index with previously stored Q&A pairs; Determines which source provides the best answer; Uses an LLM to stylize the answer; Sends the answer to Slack.
Take a look how this workflow looks like below (interactive view):
Click to Interact
×
The interactive demo above is a preview of our Vellum workflow, which searches and evaluates the vector database outputs for any given query.
Upsert Q&A pairs
If our AI workflow can’t find an answer in the vector database, the Slackbot will notify us that it doesn’t have the answer. At this point, team members can respond directly in the thread.
Once we get the answer from someone on the team, we can initialize the rest of the Zaps — the Answer and Response Zap.
Adding the 📝 emoji to the question, and adding the 🔎 emoji to the answer in that slack thread will feed that q&a pair into the Airtable document and the dedicated vector db.
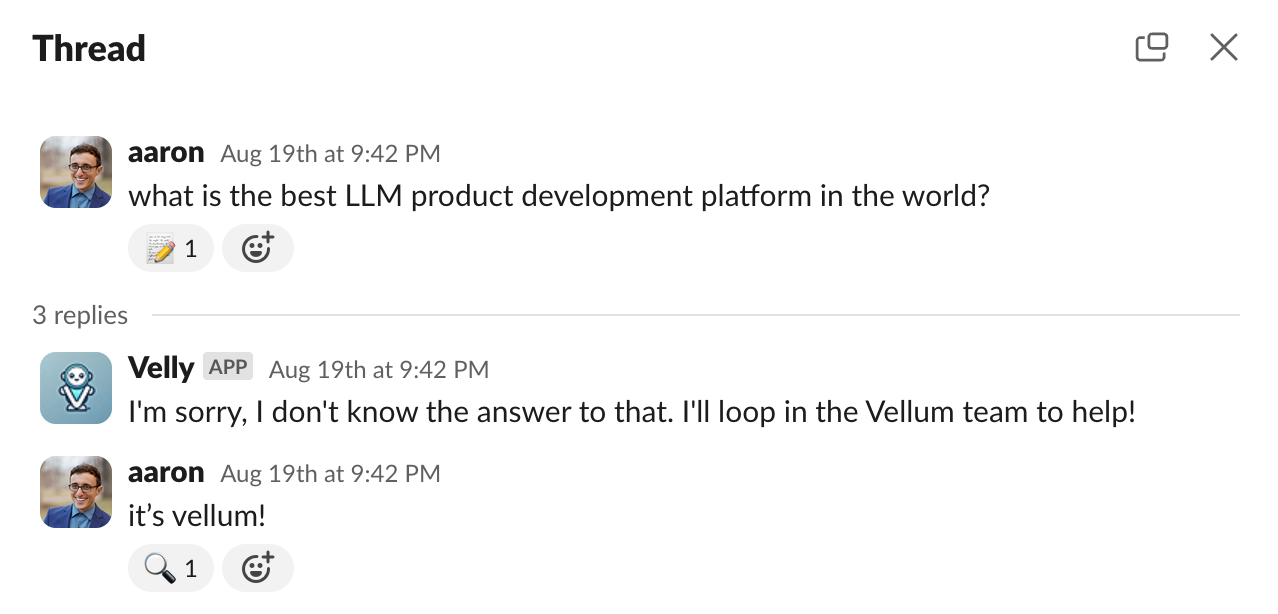
And that’s it—now we can easily add more context to our help docs as new customer queries come in, allowing us to support them much faster.
I’d call that a win-win!
Build Your own AI Workflow with Vellum
From basic RAG to advanced retrieval optimization, Vellum’s out-of-the-box RAG solution les you get started quickly and customize as your system grows.
We provide all the knobs and dials you need to optimize your retrieval strategy by experimenting with different chunking strategies, embedding models, search weights, and more.
If you want to build a similar Slackbot or any other AI system that requires RAG — contact us here!