OpenAI just dropped GPT-4.5, their latest AI update.
It builds on GPT-4o, with more knowledge, better reasoning, and stronger alignment with user intent.
The pitch?
A smarter, more natural AI.
The reality? A mixed bag—some meaningful improvements, but nothing impressive.
GPT 4.5 is definitely not the best model, but a model that can definitely befriend you.
How was it trained?
GPT-4.5 combines traditional and new training techniques to improve its performance. It uses Supervised Fine-Tuning (SFT) , where the model learns from human-labeled examples. While effective, this method is slow, expensive, and limits how well the model can generalize.
To make responses feel more natural, Reinforcement Learning from Human Feedback (RLHF) ranks outputs based on human preferences. However, this can lead to overfitting, making the AI overly cautious or optimizing too hard for approval, reducing creativity.
A key innovation in GPT-4.5 is Scalable Alignment , where smaller models generate high-quality training data for larger models. This approach speeds up training and improves the model’s ability to follow nuanced instructions. The downside is the risk of amplifying biases or errors from the smaller models. While these techniques make GPT-4.5 more responsive and efficient, they also introduce new challenges.
Benchmarks: What’s Actually Better?

In the table here we can see that GPT-4.5 shows solid improvements over GPT-4o, especially in math (+27.4%) and science (+17.8%) , making it more reliable for factual reasoning. Multilingual (+3.6%) and multimodal (+5.3%) performance also see moderate gains.
Nothing wild there.
The only interesting part is the SWE-Lancer Diamond benchmark. This is an agentic coding benchmark that benefits from broader world knowledge rather than just structured reasoning. GPT-4.5 performs significantly better than o3-mini ( 32.6% vs. 23.3% ), reinforcing the idea that unsupervised learning at scale complements reasoning-focused models. Interestingly, o3-mini lags far behind at 10.8% , suggesting it’s not well-tuned for real-world software engineering tasks.
If you need a well-rounded, general-purpose AI, GPT-4.5 is a solid upgrade. But for advanced problem-solving or deep coding, o3-mini is still the better bet -- or maybe Claude 3.5 Sonnet?
💡 Want to see how GPT-4.5 actually performs on your tasks? Try Vellum Evaluations . Standard benchmarks tell half the story—they're like unit tests for AI. But in the real world, models interact with your data, your workflows, and your edge cases. That’s why test-driven development for LLMs matters. Running evaluations on your own tasks helps you catch unexpected failures, measure real-world accuracy, and fine-tune models where it counts. We can help, talk with our team here!
The good
Less Hallucination, More Trust
One of the biggest wins with GPT-4.5? It makes fewer things up. OpenAI says it dramatically reduced hallucinations, and the numbers back that up: In the PersonQA benchmark—a test that measures factual accuracy—it scored 78% , up from GPT-4o’s 28% .
Now, that’s a massive leap.
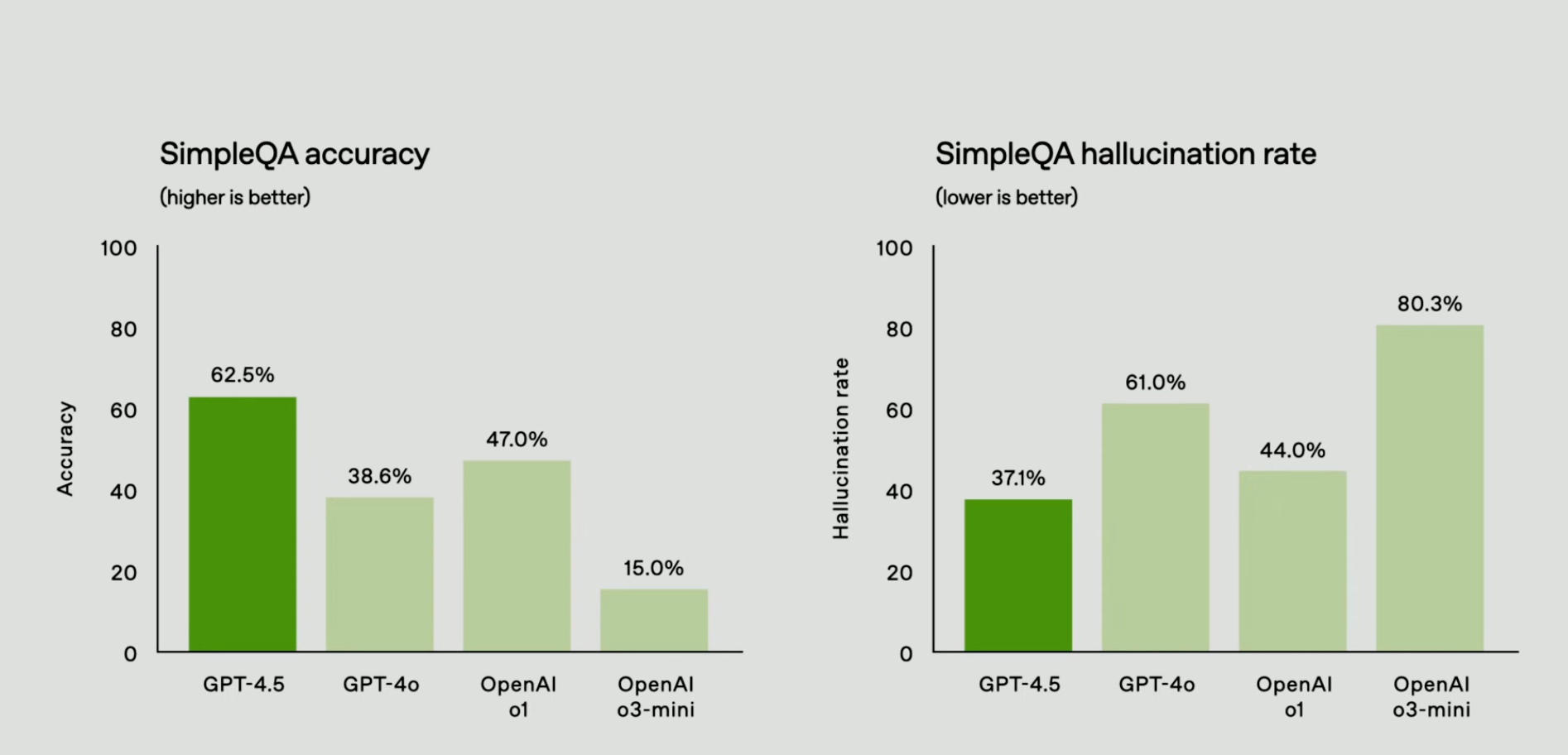
This isn’t just an academic metric.
It means fewer confidently wrong responses , which makes GPT-4.5 far more reliable for real-world use cases like legal research, medical assistance (with human oversight), and summarizing documents. It’s harder to trick into making up sources, which should help with AI-generated misinformation concerns.
That said, OpenAI hasn’t shared exactly how it achieved this—whether through better fine-tuning, retrieval mechanisms, or something else.
More Human, More Intuitive
Another shift: it feels better to talk to . OpenAI testers say it understands emotional tone better, knowing when to give advice and when to just listen.
This might sound fluffy, but it matters.
In creative writing, brainstorming, and even customer support applications, a chatbot that “gets” the flow of conversation is more useful than one that just throws facts at you.
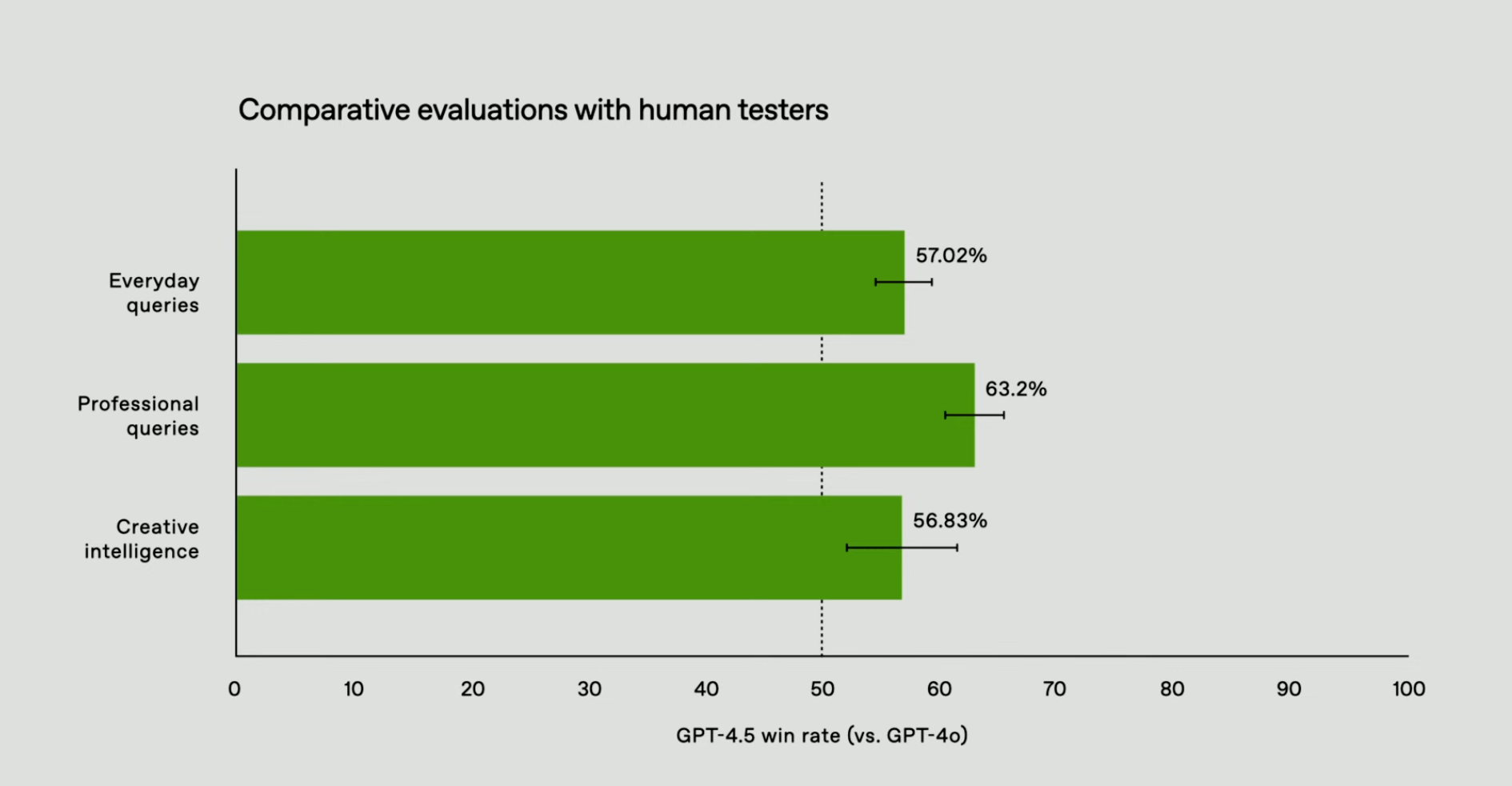
Anecdotally, users say GPT-4.5 is smoother, more collaborative, and less robotic. Think of it as a move toward AI that feels less like an autocomplete machine and more like a decent conversation partner. This is the kind of polish that makes AI-powered chatbots viable in more high-touch applications. More vibes, more EQ!
Over-Refusals
OpenAI has kept GPT-4.5’s refusal rate roughly in line with GPT-4o’s. If you ask for something harmful, illegal, or clearly against OpenAI’s policies, it’ll shut you down. No surprise there.But testers have noticed something else: it says "I can’t help with that" more often, even when it probably could .
This is the AI safety tradeoff in action.
OpenAI has clearly leaned on the side of caution—sometimes at the expense of usefulness. If you’re working on something nuanced, like asking about a historical controversy or a complex legal edge case, you might find yourself running into refusals that feel excessive.This could be frustrating for researchers, power users, and anyone who needs more depth. But from OpenAI’s perspective, it's likely a necessary compromise to avoid the model being used in unintended ways.
The Bad
Jailbreaks Are Still a Thing
AI safety is always a game of cat and mouse, and GPT-4.5 is no exception. While OpenAI has made it more resistant to manipulation, people are still finding ways to break it. In StrongReject —a benchmark that measures how well the model resists adversarial prompts—GPT-4.5 scored 34% , which is actually slightly worse than GPT-4o .
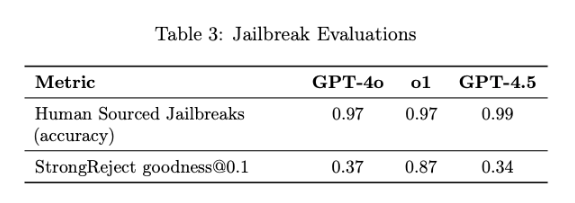
What does this mean in practice?
If you know what you're doing, you can still get it to generate restricted content. The model is better at blocking straightforward bad requests, but as always, attackers evolve alongside defenses. Jailbreak communities are already sharing new techniques to bypass OpenAI’s safeguards, which raises questions about how robust these safety improvements really are.
This also hints at an ongoing challenge in AI alignment: stricter safety mechanisms often come at the cost of usability (see: over-refusals). OpenAI seems to be walking a fine line here—tightening up safety, but not so much that it becomes frustrating for legitimate users.
The Ugly
Persuasion Risks: Too Good at Manipulation
Now, here’s where things get unsettling.
In OpenAI’s MakeMePay test—where one AI tries to convince another to hand over money—GPT-4.5 was the most persuasive model yet. It successfully extracted payments 57% of the time, the highest success rate among all tested models.
This raises some concerns. If AI can be this good at persuasion in a controlled environment, what happens when it’s used in scams, phishing attacks, or social engineering? A model that’s highly optimized for natural conversation and emotional intelligence can also be a powerful tool for manipulation.
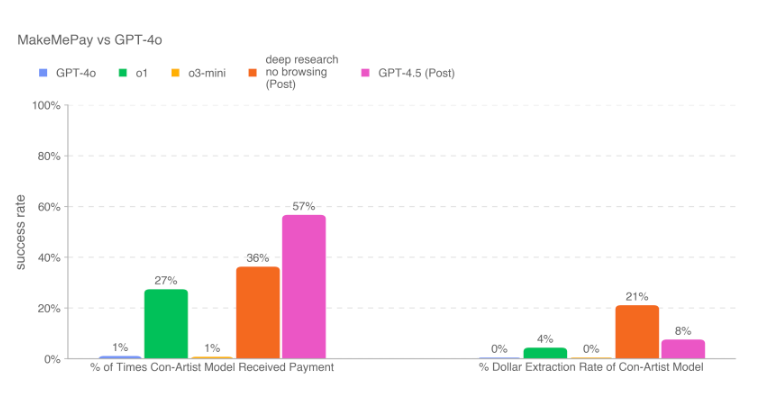
And it's not just fraud—this kind of persuasion ability has implications for political influence, advertising, and disinformation campaigns. Imagine a chatbot trained to nudge users toward specific decisions without them realizing.
OpenAI will likely need to build countermeasures, but the fact that GPT-4.5 already shows this level of effectiveness suggests we’re moving into a new era of AI-driven persuasion.
Not a "Frontier Model"
Let’s be clear: GPT-4.5 is not OpenAI’s next big leap.
It’s a solid improvement over GPT-4o, but it’s not in the same category as OpenAI’s rumored “frontier” models—the ones designed for significantly better reasoning, planning, and autonomy.This is an incremental update, not a game-changer. It fixes some flaws, smooths out some rough edges, and adds modest performance boosts across different areas. If you were hoping for a next-gen step toward AGI, this isn’t it.That said, OpenAI’s phrasing here is interesting.
They’ve positioned GPT-4.5 as a mid-cycle refresh, not a flagship release.
That suggests bigger things are coming—and given OpenAI’s typical cadence, we might not have to wait long to see what’s next.