Agentic workflows powered by LLMs are all that is new and exciting when it comes to AI.
But since they’re so new — and quite complex to build — there's no standardized way of building them today. Luckily, the field is evolving extremely fast, and we're beginning to see some design patterns emerge.
In this article, we’ll explore these emerging design patterns and frequent architectures, along with the challenges and lessons learned from companies building LLM agents in 2024.
Given how rapidly this field evolves, we’ll be publishing more insights and resources on this topic. Sign up for our newsletter to follow these updates.
We wrote this article based on the latest research and insights from AI consultants, founders and engineers. We especially appreciate the input from: Yohei Nakajima, Zac Haris, Eduardo Ordax, Armand Ruiz, Erik Wikander, Vasilie Markovic, and Anton Eremin — Thank you!
What is an agentic workflow
The official definition for the word agentic is the ability to take initiative, make decisions, and exert control over their actions and outcomes.
In that context, here's our current definition of an agentic workflow:
🦾 An agentic workflow is a system that uses AI to take initiatives, make decisions and exert control — at various stages in the process.
According to this definition, even basic AI workflows can be seen as having agentic behaviors. They make decisions and control the process at the model stage when generating output from given instructions.
Ultimately, however, these agents should act like us but have the capacity to accomplish much more. Each agent should be able to reason and decide which tasks to tackle by looking at our notes, environment, calendar, to-dos, or messages—around the clock.
The more we allow AI to make decisions on our behalf, the more agentic their behavior becomes.
With that in mind, we decided to focus on the different stages of agentic behavior in current AI architecture rather than trying to come up with the perfect definition.
We explore this in more detail in the section below.
Top agentic architectures
Agentic workflows can be understood in three levels of decision-making. At the simplest level, AI workflows make output decisions. Router workflows advance further by choosing tasks and tools. The most advanced stage—autonomous agents—goes even further by creating new tasks and tools on their own. The table below shows how these levels compare. We'll go into more details below.
Workflow Type Level 1 Level 2 Level 3 Output Decisions (Make decisions based on natural language) Task Decisions (Choose which tasks and tools to execute) Process Decisions (Create new tasks and tools to execute) AI Workflow ✅ ❌ ❌ Router Workflow ✅ ✅ ❌ Autonomous Agent ✅ ✅ ✅
Level 1: AI workflows, Output Decisions
At this level, the models in our AI Workflows make decisions based on natural language instructions. The agentic behavior happens at the model, rather than the architecture level. We can learn to prompt these models better, but we still rely on the model to decide what to generate .
Level 2: Router workflows, Task level decisions
This level outlines architectures where AI models can make decisions about their tools and control the execution path, all within a regulated environment. This is where most of the innovation happens today.
We can classify these systems as routers ; they control the execution flow, but are limited by a predefined environment of tools and tasks that they can choose to run.
For example, we’ve built an agentic router which replicates our internal SEO research and writing process. This workflow can decide which tasks/tools to execute, can reflect on its writing, but is limited to the tools that we make available upfront.
Can my agent decide to skip a specific task? Yes.
Does it have access to tools? Yes.
Can it modify the process itself? No.
Is the reflection grounded? No, we’re using an agentic prompting technique ( Reflexion ).
Zac Harris , founder @ Rankd, Ex: Copy.ai built a similar content machine at Copy AI that automates their content generation end to end. His workflow follows basic agentic capabilities, from planning to refinement, and creates novel, high-quality content which is not achievable with LLMs out of the box. At some stages human input is still needed, but he’s looking to automate the whole process. You can follow his process here .
Level 3: Autonomous Agents, Process level decisions
Creating autonomous agents is the ultimate goal of agentic workflow development. These agents have complete control over the app flow, can write their own code to achieve different objectives, and seek feedback when necessary.
However, we are quite a while off from using those tools in the real-world. We’ve seen cool demos like the AI engineer Devin , and the first autonomous agent BabyAGI by Yohei, or MetaGPT .. but none are quite ready for production yet.
Fortunately, all these experiments are pushing the industry forward and are slowly defining the fundamental components of these systems.
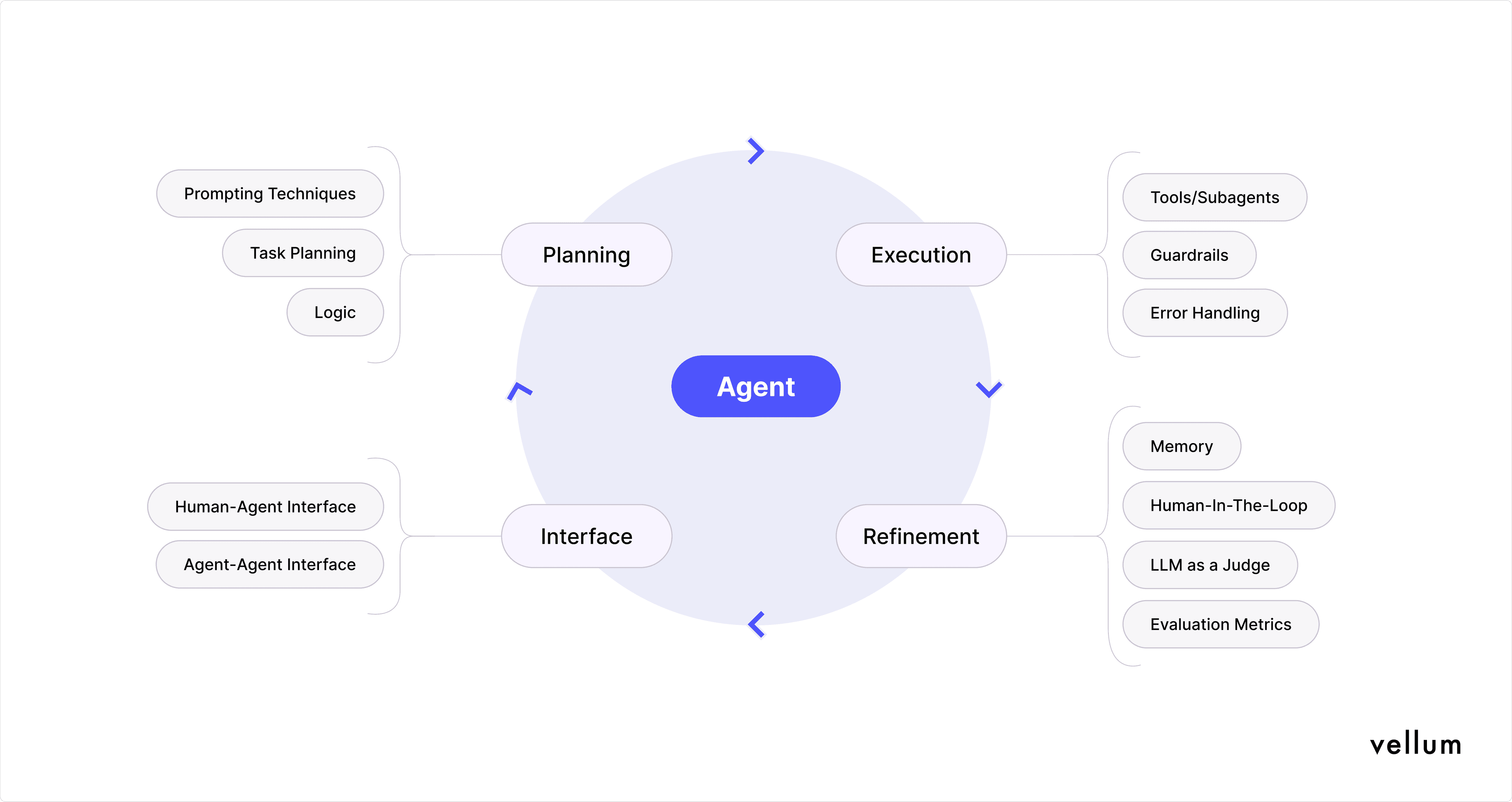
Core components to agents
Agentic workflows can be broken down into four key components. Each component has its own sub-elements that define how agents plan, act, refine, and interact. The table below shows the core components of an agentic workflow and the elements that power each stage.
Component Sub-elements Planning Prompting Techniques, Task Planning, Logic Execution Tools/Subagents, Guardrails, Error Handling Refinement Memory, Human-in-the-Loop, LLM as a Judge, Evaluation Metrics Interface Human-Agent Interface, Agent-Agent Interface
1) Planning
The planning stage outlines the logic of the workflow, and breaks down one big complex task into smaller tasks. The goal with this stage is to enable the best path for an agent to be able to reason better, and delegate tasks if needed.
Depending on the type of architecture (single, or multi-agent) there are various strategies to use here; like CoT, ReAct, Self-Refine, RAISE, Reflextion. We cover these strategies in the next section.
From Native RAG to Agentic RAG ” Most customers I work with are in demo space, but for real production enterprise solutions, there are several gaps and a lot of opportunities.” Armand Ruiz , VP of Product - AI Platform at IBM says that there are two types of agentic architectures he frequently sees working with his clients: - Document Agents : Each document has a dedicated agent for answering questions and summarizing within its scope. - Meta-Agent : This top-level agent manages the document agents, coordinating their interactions and combining their outputs for comprehensive responses.
2) Execution
The execution stage contains the set of helpers like modules, tools, and data that the agent needs to do the job right.
#### Access to tools/subagents
Your agentic workflow should have access to pre-built tools relevant to your use case which can be referenced at various stages, sequentially or in parallel. Examples include web search, vector stores, URL scrapers, database access, and traditional ML models.
Multi-agent systems should have access to subagents who specialize in specific tasks.
If no tool is available for a specific task, an autonomous agent should be able to write code and create its own tools. For example, this closed-loop approach like LATM (LLMs as Tool Makers) evaluates where tools are needed, and writes custom Python functions.
#### Guardrails and Error handling
Use guardrails to keep your agents safe with validation checks, constraints, and fallback strategies.
Implement error handlers to quickly detect, classify, and address issues, ensuring smooth operation. Here's a basic strategy for handling non-deterministic failure.
3) Refinement
At this step the agent examines the work and comes up with new ways to improve it. If fully autonomous, it can create new paths/tools to arrive to the objective if needed.
#### LLM-based eval
When possible provide a detailed scoring rubric and use LLMs to evaluate another's outputs.
#### Short-term memory
Long-context windows are making it easier for LLMs to handle short-term memory more effectively, but good prompting techniques should be implemented to achieve the best performance.
#### Long-term memory
When it comes to agents, long-term memory is the biggest unlock, but the biggest challenge as well.
For long-term memory between workflows, it's about saving information and then recalling it through tool calls or by injecting memories into prompts. When constructing this long-term memory, you can use several storage solutions (each comes with specific limitations/advantages):
Vector stores (like Pinecone and Weaviate), handle unstructured data but can be complex and costly; Key/value stores (like Redis and MongoDB), are fast and simple but lack query power; Knowledge Graphs (like Neo4J, Cognee and DGraph), excel at complex relationships but are resource-intensive and can slow down as they grow. We wrote more on the topic here .
A Graph is All you Need? Yohei Nakajima , Investor and the creator of BabyAGI says that a graph-based agent is really good at reading and understanding everything about itself, which a key part of self-improvement. He’s currently rebuilding BabyAGI with three internal layers of graphs that will handle the code and functions, logs and knowledge.
Knowledge Graphs are becoming the choice for agentic RAG, because they offer a structured method to navigate data, ensuring more ‘deterministic’ outcomes that can be easily traced.
Towards Deterministic LLM outputs with Graphs Vasilije Markovic , shares that we need to build better memory engines to handle long term memory for agents. He highlights the main challenges with vector databases like problems with interoperability, maintainability, and fault tolerance. He is currently building Cognee , a framework that blends graphs, LLMs and vector retrieval to create deterministic outputs and more reliability for production-grade systems.
Even, recent research, like the Microsoft's GraphRAG paper , highlights how knowledge graphs generated by LLMs greatly improve RAG based retrieval.
#### Human in the loop & Evaluations
It's interesting — as we give more control to these workflows, we often need to include a human in the loop to make sure they’re not going off the rails. If you’re building more advanced agentic workflows today, you must trace every response at each intermediate step to understand how your workflow operates under specific constraints.
This is crucial because we can't improve what we don't understand.
In many instances, human review happens in development and in production:
In Development: Track and replay tasks with new instructions to understand and improve agent behavior. Run test cases at scale to evaluate the outputs. In Production: Set checkpoints to wait for human approval before continuing. Run evaluations with new data, to optimize your workflows, and minimize regressions.
Debug observability traces and check what your LLM/model sees Anton Eremin , founding engineer at Athena , shared that their wide use-case pool introduces a lot of layers and complexity in their AI workflows. "Focus on prompt and context testing before changing code to ensure optimal outcomes and address limitations. Ask questions like these: - Can you complete the task with the provided info? What would you add or change? - Does it work on 10 real-world examples? Where does it struggle? Fix it or inform users of the limitations? - Will the toolset provider, industry best practices, or research solve this in a month?
4) Interface
In some sense, this step can be the last and the first step in the agentic workflow - you need to start the agent!
#### Human-Agent Interface
Many people believe that a great UI/UX can make agents much more effective, and we completely agree! Just as the chat UI transformed interactions with LLMs, new UI concepts could do the same for agents.
We think that users will trust an AI agent more if they can follow and interact with its work through a dedicated, interactive interface.
Another type could be a collaborative UI. Imagine "Google Docs" style setup where you leave comments, and the agent updates the content.
Finally, agents should be deeply integrated with our processes and tasks.
True Unlock at the Embedded Stage Erik Wikander , founder @ Zupyak says that we're just at the beginning of the true potential of AI agents. ”As LLMs mature, we will go from the current co-pilots to AI co-workers. The key to unlocking the true value will be in integrating them in to existing processes and systems, which will take time. For our own use case which is search optimized content marketing, we see value unlocking quickly the more deeply embedded in to existing workflows and processes.”
#### Agent-Computer Interface
Even though ACI is a new concept, it's clear that tweaking the agent-computer interface is essential for better agent performance. By constantly adjusting the syntax and structure of tool calls to fit the unique behaviors of different models, we can see big performance gains. It's just as important and complex as creating a great user experience.
AI agent design patterns
There are many design patterns that address how the agent decides which tasks to execute, how it handles task execution, and how it processes feedback or reflection. Eventually, you'll develop a pattern tailored to your use case by testing various implementations and flows. But, below we share some of the latest design patterns for inspiration.
1) Single Agent architectures
Single Agent architectures contain a dedicated stage for reasoning about the problem before any action is taken to advance the goal.
Here are some common architectures and their advantages/limits:
ReAct cuts down on hallucinations but can get stuck and needs human feedback. Self-Refine improves initial outputs by using iterative feedback and refinement. RAISE adds short-term and long-term memory to ReAct but still struggles with hallucinations. Reflexion improves success rates by using an LLM evaluator for feedback, but its memory is limited. LATS combines planning and Monte-Carlo tree search for better performance. PlaG uses directed graphs to run multiple tasks in parallel, boosting efficiency.
You'd want to use single agents when
2) Multi Agent architectures
Multi-agent architectures allow for smart division of tasks based on each agent's skills and provide valuable feedback from different agent perspectives.
These are ideal for tasks requiring feedback from multiple perspectives and parallelizing distinct workflows, such as document generation where one agent reviews and provides feedback on another's work.
Here are some emerging architectures like:
Lead Agents improve team efficiency with a designated leader. DyLAN enhances performance by dynamically re-evaluating agent contributions. Agentverse improves problem-solving through structured task phases. MetaGPT reduces unproductive chatter by requiring structured outputs. BabyAGI uses an execution, task creation and prioritization agent to organize daily tasks.
Research shows that a single-agent LLM with strong prompts can achieve almost the same performance as multi-agent system. So when you’re implementing your agent architecture you should decide based on the broader context of your use-case, and not based on the reasoning requirements.
The AI agent stack of 2026
Agentic workflows will require even more prototyping and evaluation before being deployed in production. Today, however, the focus is on understanding the behavior and determining the right architecture.
Understanding Behavior Comes First ” While there's a lot of potential in agentic workflows, many are still struggling to move into production. Today, when people evaluate Agents performance, they try to understand the flow/trace of the agents to identify the behavior." Eduardo Ordax , Principal Go to Market Generative AI at AWS
The more these systems become agentic the more there will be a need for agent platforms. These platforms should enable the following:
AI Agent Stack Capability (2025) Purpose / Value Tracing & Replay Understand and improve agent paths by replaying tasks with new instructions. LLM Calls with Fallbacks Ensure reliability by providing backup options when models fail. Human Approval in Production Add checkpoints for moderation and error handling. Tool Library & Execution Use pre-built tools or create/save new ones for different workflows. Executable Code Run arbitrary code at any stage for customization and flexibility. Metrics & Evaluation Apply built-in or custom metrics to evaluate agent performance at scale. User Feedback Integration Incorporate real user input into evaluation datasets for better training. Version Control for Prompts/Models Track changes without needing to update core code, ensuring safe iteration.
Here at Vellum , we’re building exactly this type of foundation. An orchestration layer that gives teams confidence their agents will behave reliably in production, while still giving them flexibility to adapt, experiment, and evolve.
Tips on building agents from top experts
Many are currently experimenting with LLMs and Agents, but only a few truly understand the space. We talked with some of these experts and cover their lessons learned, observations and current work that can hopefully aid your AI development process.
Understanding Behavior Comes First
Eduardo Ordax , Principal Go to Market Generative AI at AWS , shared with us that many of their customers at AWS initially began with simple function-calling LLMs and are now transitioning to more sophisticated agentic workflows.
He has seen three main use-cases:
RAG with multiple strategies under a master orchestrator; Agents with traditional ML (i,e fraud detection); Agents replacing repetitive RPA tasks.
Most common challenges he’s seen is identifying the right LLM for specific tasks. He says that long term memory is a huge challenge, especially for more complex tasks. Most initially start building with LangChain, but as the complexity grows, they transfer to managed services.
Eduardo highlights that while there's a lot of potential in agentic workflows, many are still struggling to move into production. Current evaluations focus more on understanding agent behavior rather than rushing them into production. We see that same across many of our customers here at Vellum. Most of the work is done by cross-functional teams, who are trying to validate new agentic workflows.
Indeed, agents can take many paths and iterations, each with different executions and will require different kind of evals to build confidence in their performance.
From native RAG to agent RAG
Armand Ruiz , VP of Product - AI Platform at IBM , says that most customers he works with are in the demo space and use frameworks (Langchain, CrewAI, LlamaIndex) for prototyping. For real production enterprise solutions, there are still many gaps and opportunities.
He’s currently helping a lot of companies to navigate from native RAG to Agentic RAG architectures because of the need for automating retrieval, and adapting to new data and changing contexts.
These are two types of architectures he frequently sees:
Document Agents : Each document has a dedicated agent for answering questions and summarizing within its scope. Meta-Agent : This top-level agent manages the document agents, coordinating their interactions and combining their outputs for comprehensive responses.
Embedded agents: The biggest unlock
Erik Wikander , founder @ Zupyak , says that content marketing today is a very fragmented process with lots of stakeholders and systems involved, often with a disconnect between disciplines like SEO and content. Their goal is to streamline this workflow and bridge this gap, which creates a perfect use case for AI agents.
Currently they’re in co-pilot mode, where the user needs to give their input during the full process. They’re using Vellum to build towards more autonomy, allowing the user to simply give the system a task which it then performs on behalf of the user. But every customer they talk to wants the AI agent, since they want to move their focus from execution to ideas.
Are graphs all you need?
While current RAG solutions significantly improve LLM performance, hallucinations remain an issue. Today, many are starting to experiment with knowledge graphs, and latest research shows that for specific use-cases LLM-generated knowledge graphs can outperform baseline RAG.
Even beyond that, using graphs in conjunction with long-context models can improve reasoning , and many are experimenting with graphs at every level in the agentic workflow.
We spoke with Yohei and Vasilije, who are actively working in this field.
Graph-based agents
Yohei Nakajima , Investor and the creator or BabyAGI , was probably the first to experiment with autonomous agents.
He iteratively built a task-driven agent to have various modules like: parallel task execution, skills library to generate code and new skills, self-improvement methods, and even experimented with a novel UI.
Today, his approach is changing. He’s rebuilding BabyAGI as graph-based agents, where he has three internal layers of graphs that will handle the code and functions, logs and knowledge. You can follow his building process here .
The path to deterministic LLM outputs
Vasilije Markovic , Founder @ Cognee emphasizes the need for better memory engines to handle long-term memory for agents, addressing challenges with vector databases such as interoperability, maintainability, and fault tolerance.
He is developing a framework that combines graphs, LLMs, and vector retrieval to create deterministic outputs and enhance reliability for production systems.
How to move fast with AI development
Anton Eremin , founding engineer at Athena , shared that working on a really wide use-case pool, introduces a lot of layers and complexity in their AI workflows. To be able to move fast in developing their agentic workflows, they follow a few best practices:
Research Before Implementation : Explore and test open-source implementations before starting new projects to understand abstractions and edge cases. Buy/Fork Before Building : Use high-quality projects as components to save time and resources. They partner with vendors like Langchain and Tavily. Change Code/Models Before Fine-Tuning : Modify code or models first due to evolving data and new model releases, rather than fine-tuning models. Prompt Engineering First : Focus on prompt and context testing before changing code to ensure optimal outcomes and address limitations. Debug observability traces and check what your LLM/model sees. Focus on prompt and context testing before changing code to ensure optimal outcomes and address limitations. Ask questions like these: Would you be able to complete the task with the information and instructions input? What would you add/change? Does it work on 10 other real-world examples? Where does it struggle and why? Should we solve for this, or just be clear about the current limitations with users and get signal from them before fixing this? Is there a good chance the toolset provider/industry best practices/frontier research will solve this problem for you in a month?
- Only after doing through everything above it makes sense to touch code and engineer improvements.
From co-pilots to Agentic Workflows
Zac Harris , founder @ Rankd , Ex: Copy.ai built a content machine at Copy AI that automates their content generation end to end. His process includes prioritizing topics, creating briefs and drafts, adding source data, and refinement until the content meets top content standards and guidelines.
His workflow mimics some of the basic agentic capabilities. This architecture creates novel, high-quality content which is not achievable with LLMs out of the box. Most of our customers here at Vellum, are moving from copilots to agentic workflows as well.
While human input is still needed, he’s looking to perfect this system and automate the whole process. You can learn more about his technique here .
Build agents with Vellum
Our core belief is that trust is crucial when building these systems, and achieving that trust becomes more challenging as we release more control to agentic workflows.
That's why we need advanced orchestration, observability and evaluation tools. At Vellum , we ensure this trust by helping you build and manage your whole AI development lifecycle - end to end. We've collaborated with hundreds of companies, including Redfin and Drata , and enabled their engineering and product teams to deploy reliable AI systems in production.
We're excited to continue innovating in this dynamic space and help more companies integrate AI into their products. If you're interested and you'd like to see a demo, book a call here.
FAQs
- What does “agentic workflow” mean in AI? An agentic workflow is an AI system that doesn’t just generate outputs but also makes decisions, chooses tasks, and controls parts of the process.
- How is an agent different from a regular LLM workflow? A regular LLM workflow generates responses to instructions. An agent goes further—it can pick which tools to use, decide on task order, and sometimes even create new tools or code.
- What are the main levels of agentic behavior? The article breaks it down into three:
AI workflows (output decisions) Router workflows (task decisions) Autonomous agents (process decisions)
- Why are agentic workflows hard to build today? They are new, complex, and there’s no single standard for building them. Most teams are still experimenting with different architectures and design patterns.
- What are the core components of an agentic workflow? Planning, execution, refinement, and interface. These stages define how agents reason, act, evaluate, and interact with humans.
- How do multi-agent systems work? Instead of one agent doing everything, multiple agents specialize in different tasks and collaborate. This often improves speed, quality, and reliability.
- What role do graphs play in agentic workflows? Knowledge graphs help agents reason in a more structured, traceable way. They improve retrieval, memory, and make outputs more reliable compared to using vector databases alone.
- How important is memory for AI agents? Critical. Short-term memory helps handle context within a task, while long-term memory lets agents recall information across workflows. Without memory, agents can’t improve or handle complex tasks.
- Are fully autonomous agents ready for production? Not yet. While there are exciting demos like BabyAGI and Devin, production-ready systems are still focused on controlled, semi-agentic workflows with human oversight.
- How can companies get started with agentic workflows? Most start with copilots and simple LLM workflows, then move to router workflows with tool use. Partnering with agent platforms (like Vellum) helps teams evaluate, debug, and run these workflows reliably in production.