It’s December, and that means everyone’s shipping. OpenAI kicked off their 12-day launch event, Google just dropped their new Gemini 2.0 Flash model, AWS rolled out new models, and it’s only a matter of time before Anthropic joins the ship-mass celebration.
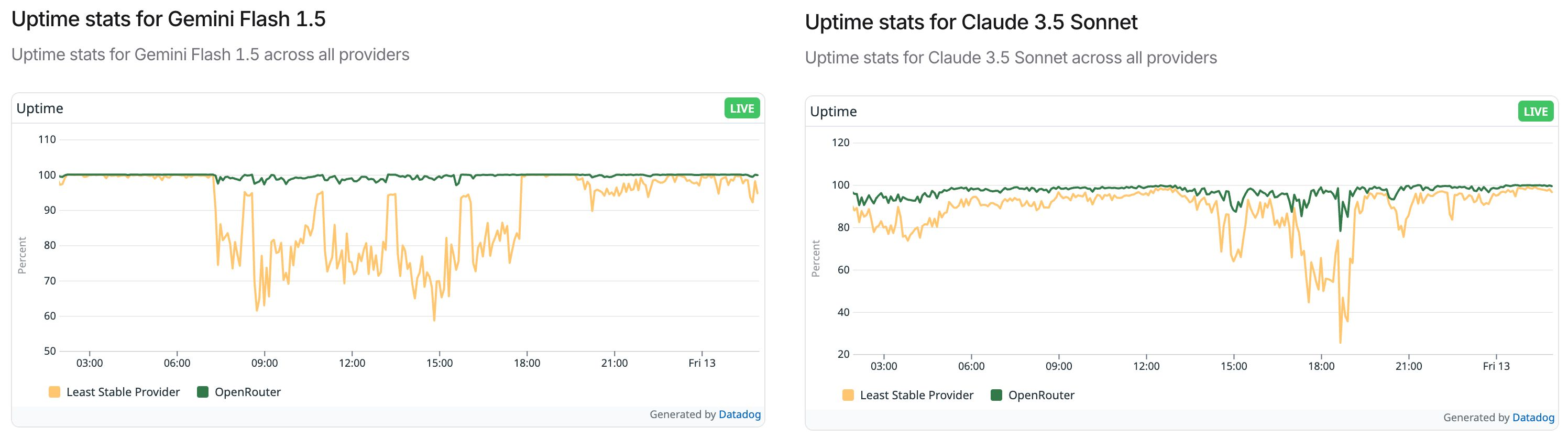
With all this activity, API uptime across providers has taken a major hit.
OpenAI was down for four hours in a single day, while Claude 3.5 Sonnet and Gemini Flash 1.5 were highly unreliable on Thursday (12/12/2024).
Just check out the reports from OpenRouter:
Building an AI application for production means planning for reliability, even when things go wrong.
Downtime isn’t the only risk—rate limits, incorrect requests, and bad responses can all impact performance and user satisfaction.
In this article, we’ll share practical tips and fallback strategies to help ensure your app stays resilient and handles these issues smoothly.
When do you need an LLM gateway/router?
Error Handling
LLM provider errors are common, and no system is immune to them. You should be ready to handle them in production. While error handling is a familiar concept in software engineering, working with LLM models introduces extra complexity.
A quick look at OpenAI’s error code list shows many potential issues you’ll need to manage carefully in your code.
Here are a few that can be mitigated with a proper fallback strategy:
RateLimitError: You’ve hit your assigned rate limit. In this case the remedy is to wait ~1 min or send shorter requests. For apps in production, you should think about switching to another model. InternalServerError: This indicates the provider had trouble processing your request. While you can check their status page, if this happens frequently in production, it’s crucial to have proper fallbacks in place, such as a provider router, to maintain system reliability. APITimeoutError: This means that your request took too long to complete, and that the provider server closed the connection. This could be a network issue, or a heavy load on the provider’s services — in this case you can retry the same request a couple of times, until it gets resolved. If it doesn’t, then you should have a proper fallback, like routing to another provider instead. 400 BadRequest: T his typically indicates a problem with your API request. For example, you might be sending more tokens than the model’s input context window allows. To prevent this in production, consider counting tokens programmatically before making the request using the Tiktoken library. Read more about that technique here .
Apart from handling costs, model routing is quite useful when you want to optimize your app — in terms of performance, cost, & speed!
Optimizing for cost, speed and capabilities
You probably don’t want to use the most expensive and powerful model for basic questions when a cheaper, faster model can do the job just fine. In such cases, it’s smart to set up a routing system that directs queries to the most suitable model, balancing cost, speed, and capability.
You can also make your system even more efficient by using your RAG setup and caching past responses to avoid extra API calls.
Different task specialization
Different models excel at specific tasks.
Check out the OpenRouter model collection for models suited for programming tasks. You’ll find at least one smaller, cheaper, and faster model specialized in programming that can serve as a great substitute for certain tasks.
Managing fallbacks in production
Considering all the possible errors or issues that could arise, managing them in production can be challenging. We recommend defining your own fallback logic to handle different types of failures specific to your system’s needs.
Relying on a black-box router or platform introduces an additional layer of abstraction, making it harder to build confidence that your system behaves as expected. Ultimately, you’re responsible for your application’s performance in production, and defining the retry logic is key to ensuring system reliability.
Enough theory— let’s see how to implement these strategies.
Fallback Strategies
Rule-based Model Routing
Rule-based model routing allows selecting the best model for each task based on specific needs, while also enabling fallback models if the primary one fails.
Consider this routing when you need to handle provider errors, match tasks with the right models, balancing cost, speed, and specialized capabilities like summarization or code generation. Implementing this type of routing can be very simple or more complex, depending on your setup’s complexity, the type of AI app you’re building (e.g., chat vs. data extraction), and how sophisticated you want your system to be.
For example, you can set a primary model (e.g. GPT-4o) and fallbacks to similar performance models (e.g. Claude 3.5 Sonnet) if the primary model fails to execute a given task. This workflow should include a rule-based handler that detects errors and triggers another model when needed.
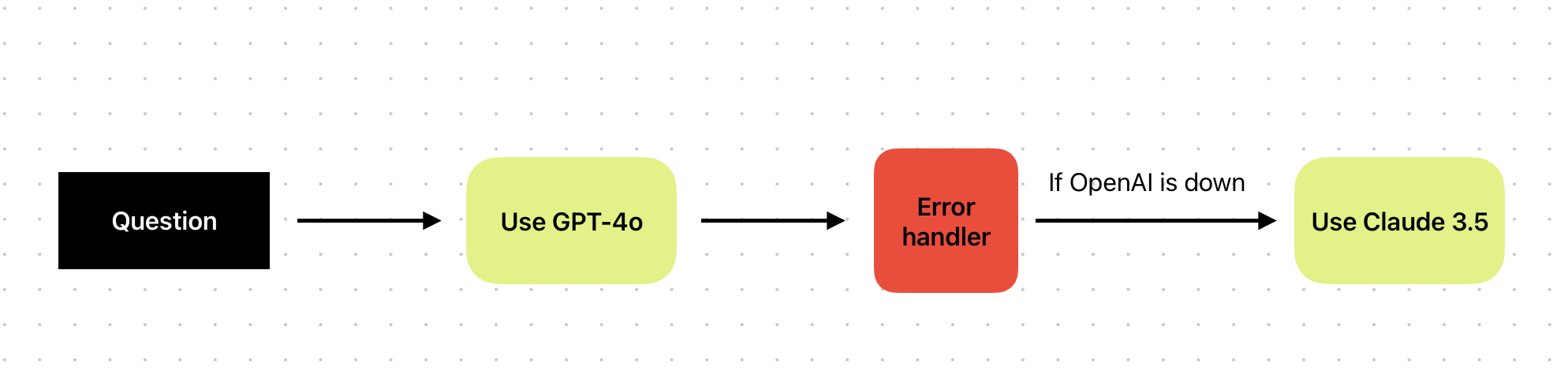
In Vellum you can easily setup your model and provider routing, by connecting a few different “Prompt Nodes” as you can see in the embed below. You can also have a flow that will raise and capture the error so that you can store it in your logs:
Click to Interact
×
When you use this strategy, you’ll need to create another set of evaluation data to test both the primary and fallback models. This makes sure they give similar answers when running in production — learn more about LLM evals here .
Retry with exponential backoff for rate limit errors
A common way to avoid rate limit errors is to add automatic retries with random exponential backoff . This method involves waiting for a short, random period (aka a “backoff”) after encountering a rate limit error before retrying the request. If the request fails again, the wait time is increased exponentially, and the process is repeated until the request either succeeds or a maximum number of retries is reached.
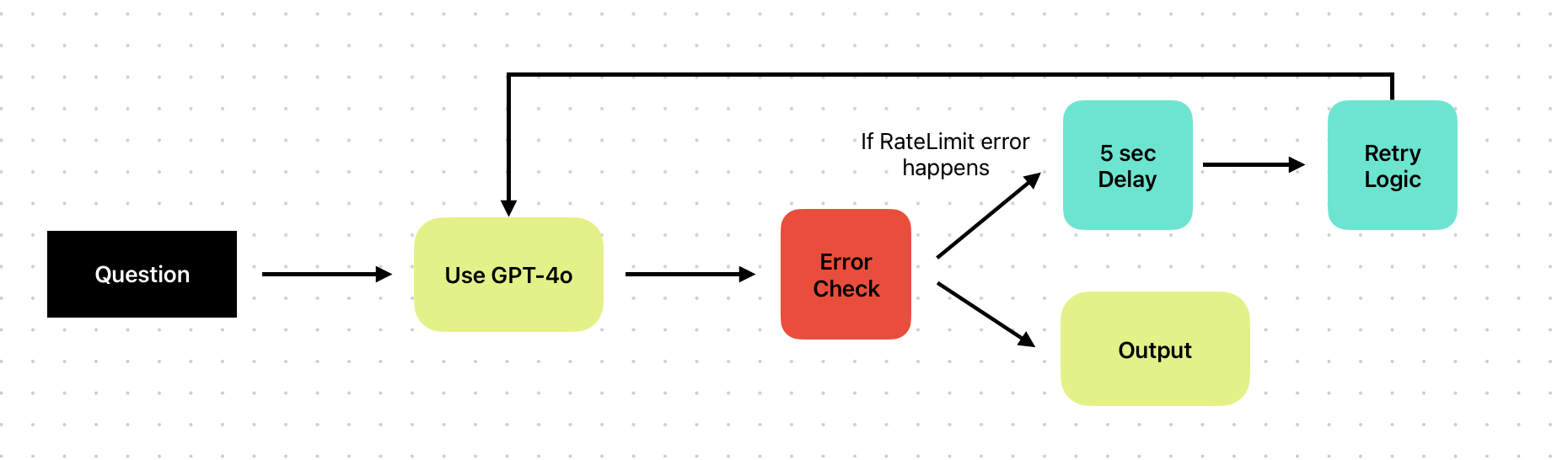
Below is an interactive preview of a Vellum Workflow implementing exponential backoff logic. If the prompt node encounters an error, the workflow waits for 5 seconds and retries up to 2 times:
Click to Interact
×
Human-in-the-Loop router
When the model can't provide an answer due to specific criteria, use function calls (tools) and handlers to route the request to a human. This is crucial if you’re expecting your users to ask sensitive questions (e.g., the user is angry or in a dangerous situation) or when they’re ready to speak with a human (e.g., for real estate apps, where the buyer is ready to talk with an agent about a specific property).
In a case of an error, you can implement error-handling logic to route the question to a human instead of retrying the API request.
Here’s how you can implement a human-in-the-loop router logic using Vellum :
Click to Interact
×
LLM-as-a-judge router
This can be tricky, but the idea is to add a step after a user request that acts as an “intent classifier.”
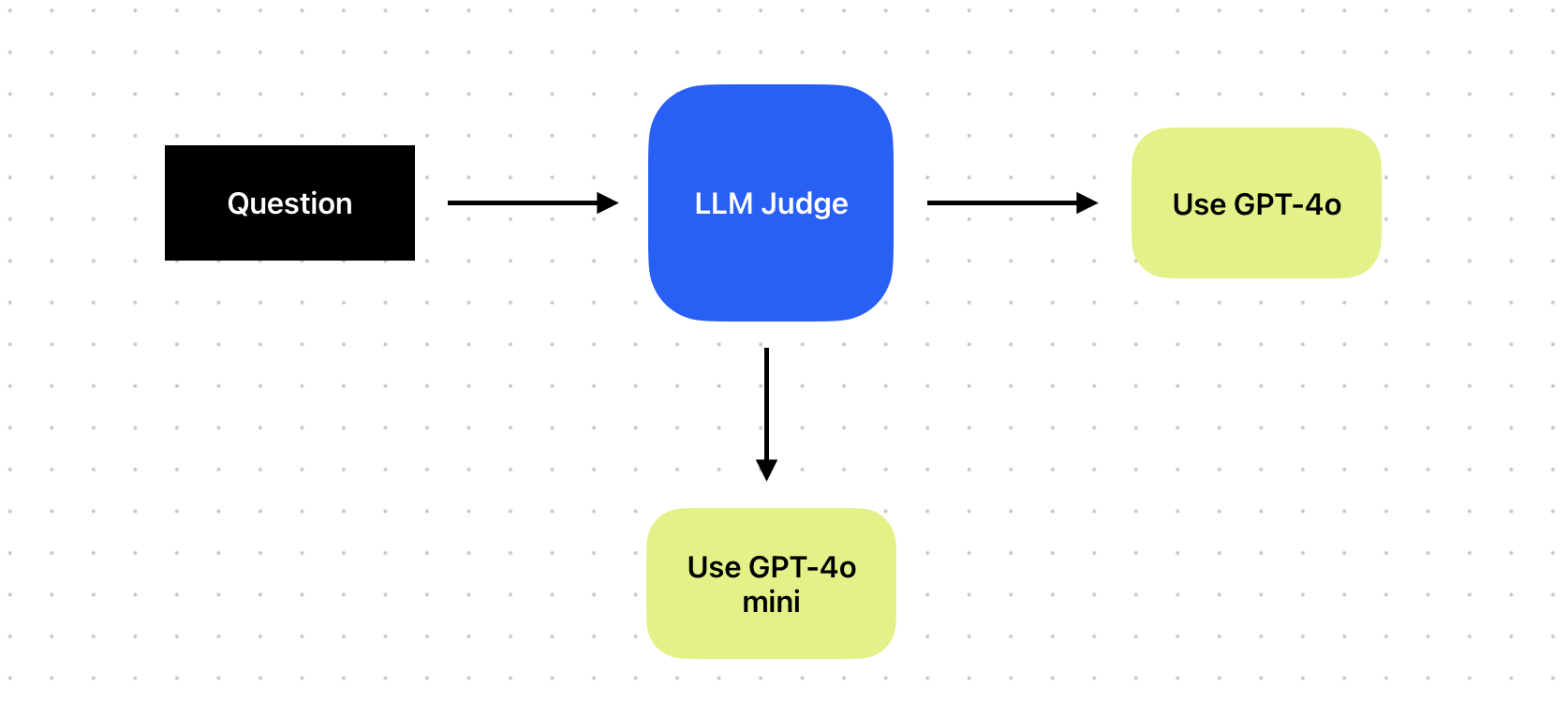
The LLM can classify the request, allowing you to filter downstream tasks based on the detected intent. This approach is useful when you want to use a smaller model for basic questions or respond faster. Of course, there are tradeoffs depending on your app’s scale and the number of customers you’re serving.
As a final note, if you can, it’s always a good practice to spread out your requests across multiple providers to reduce the overall risk of your app.
Conclusion
Provider issues are bound to happen—what matters is how you handle them.
Rather than relying on black-box solutions that abstract away critical decision-making, define your own fallback logic tailored to your app’s unique needs. This gives you full control over how your system handles failures, ensuring reliability and consistency.
With Vellum , you can build custom workflows, set up model routing, implement retries with backoff, and even add human-in-the-loop logic—all without sacrificing transparency.
You stay in control while leveraging a platform designed for scalable, production-ready AI.
If you want to try our Workflow IDE or the SDK — let us know here.