November is a month for crisp fall weather, giving thanks, and another round of Vellum product updates! In October, we shipped a ton of new models, improvements to Evals, Prompts, Workflows, and more.
Hold the gravy, let’s dive in and see what’s new 🎃
Online Evaluations for Workflow and Prompt Deployments
Previously, you could only run “Offline Evaluations” or “Inline Evaluations.” You can run Offline Evaluations manually when you want to check Prompt / Workflow performance, e.g. when you’re getting ready to make a new Production Release. Inline Evaluations are useful if you want to check quality during a Workflow’s execution and conditionally do something within the Workflow (retry a prompt, throw an error or Slack alert, escalate to a human, etc.)
But what if you want to monitor how your product performs live in production? Now you can!
Online Evaluations help you see your product’s performance in real time. They run on every production execution of your app, helping you catch & resolve edge-cases faster, and prevent regressions more thoroughly. The best part – you can use Vellum premade Metrics, or Custom Metrics that you’ve already configured!
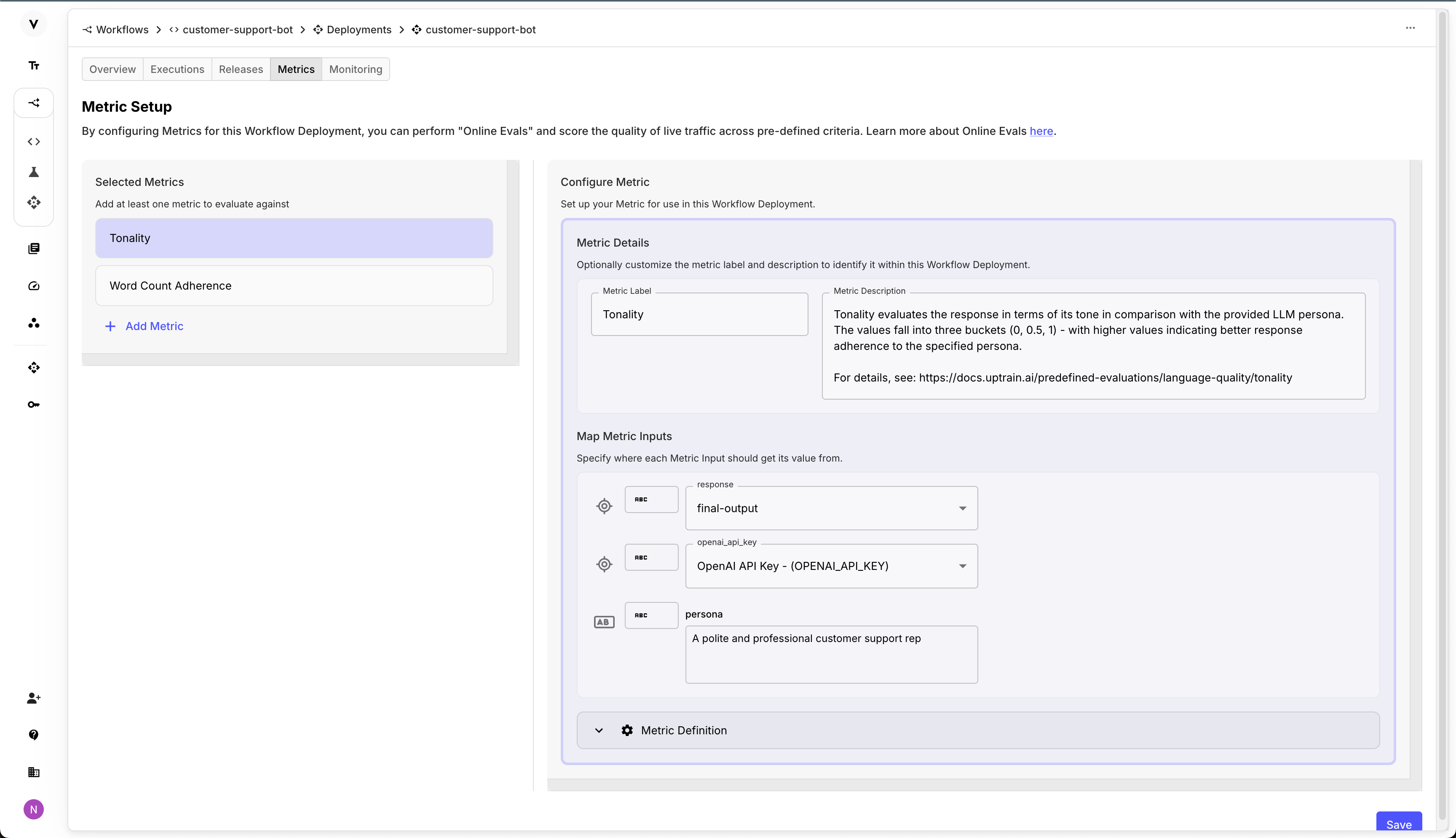
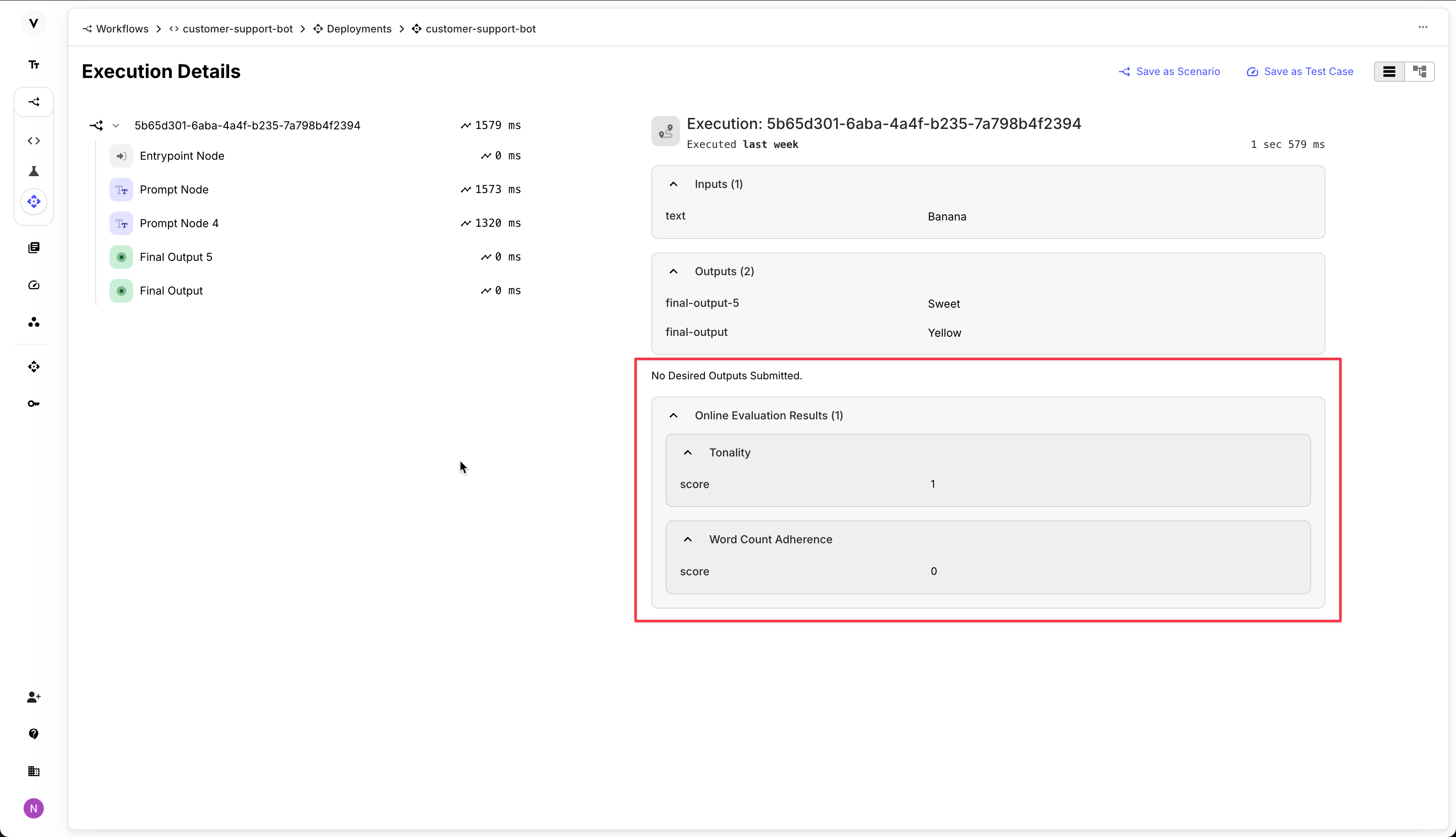
You can read more about Online Evaluations here !
Configurable Prompt Node Timeouts
Previously, if you wanted to avoid having a single Prompt node slow down your workflow, you’d need to setup a few nodes and cumbersome logic to time out early.
Now, you can easily set maximum timeouts for Prompt Nodes within Workflows, preventing bottlenecks and ensuring efficient resource management.

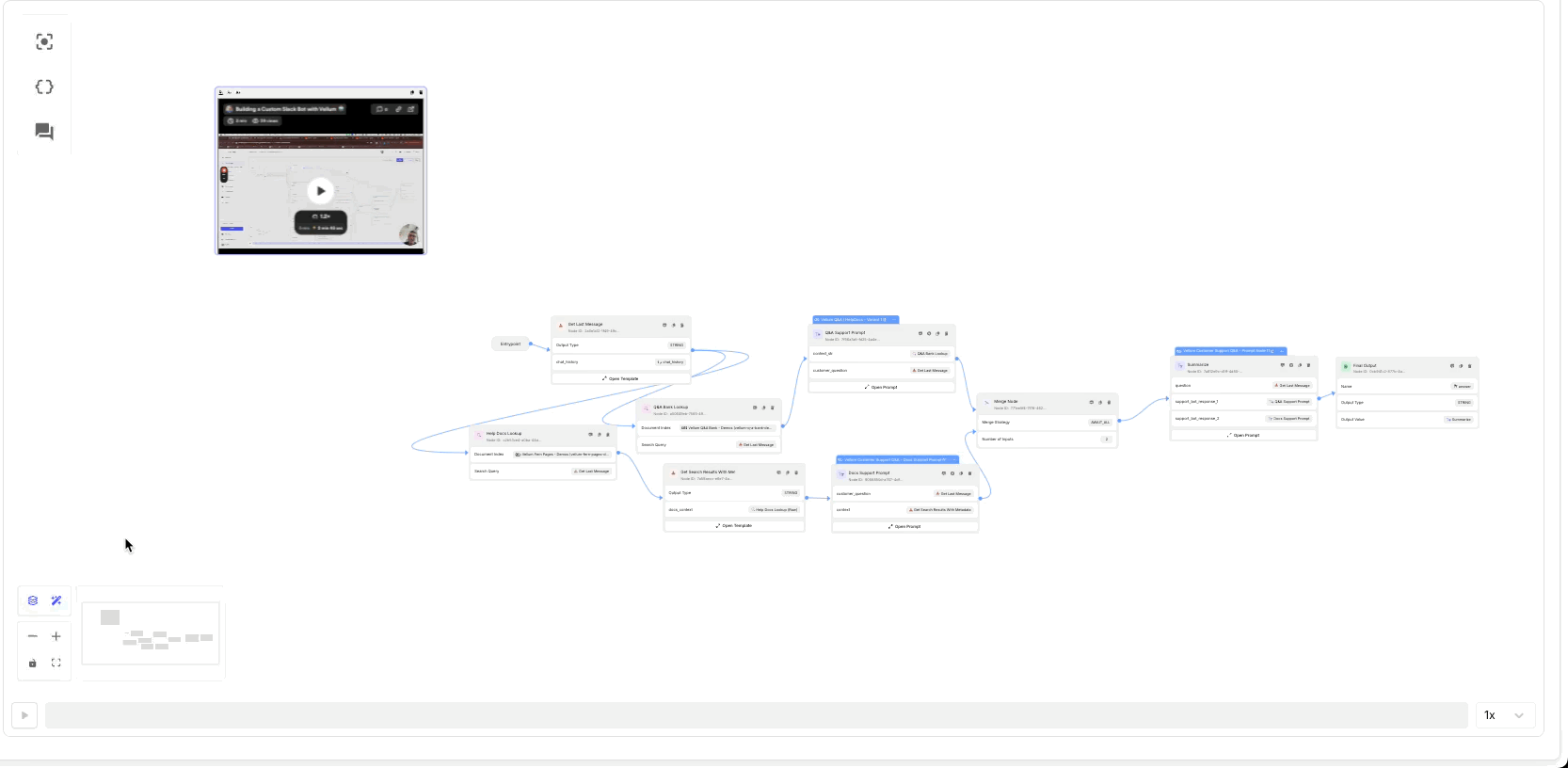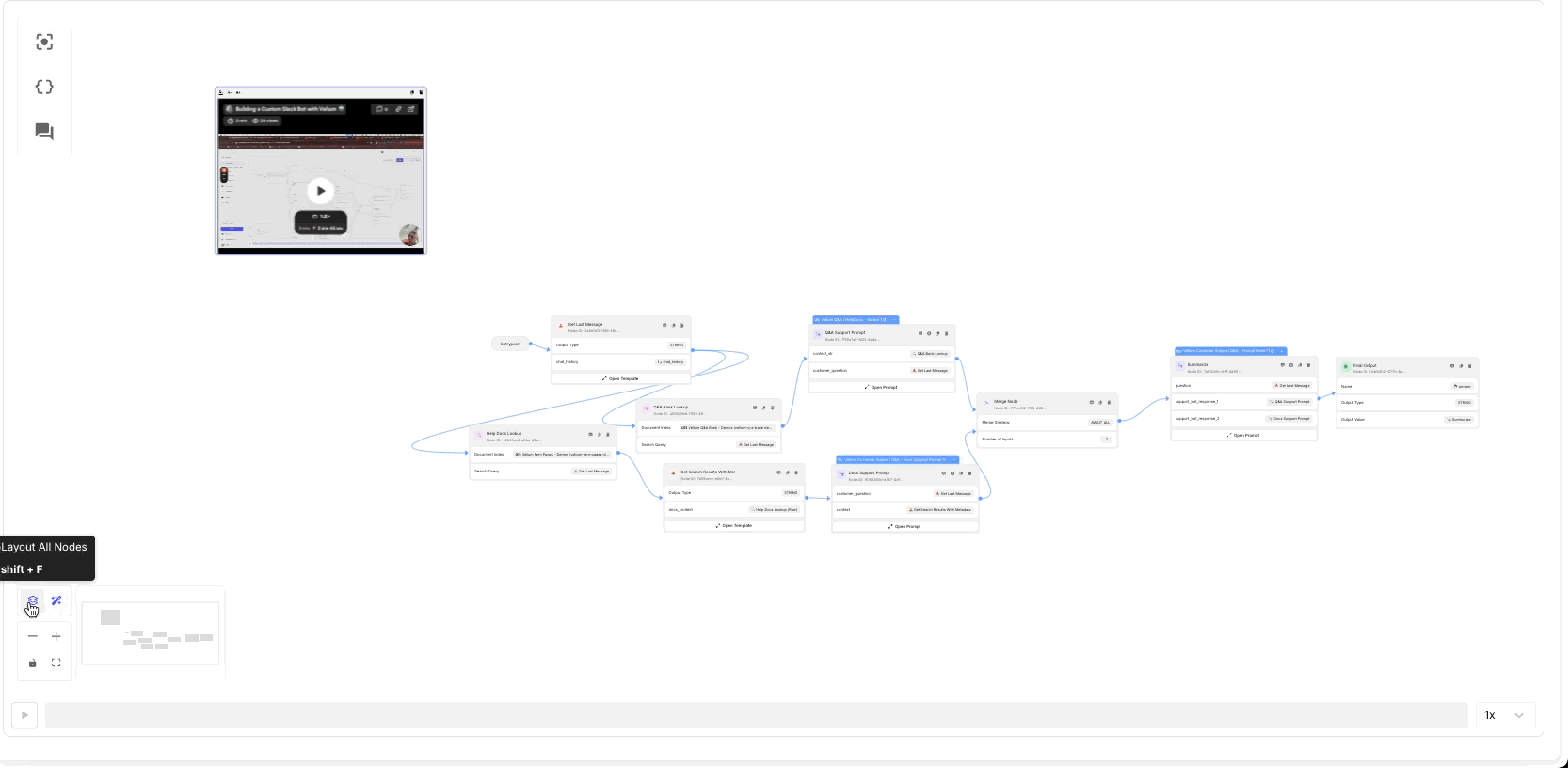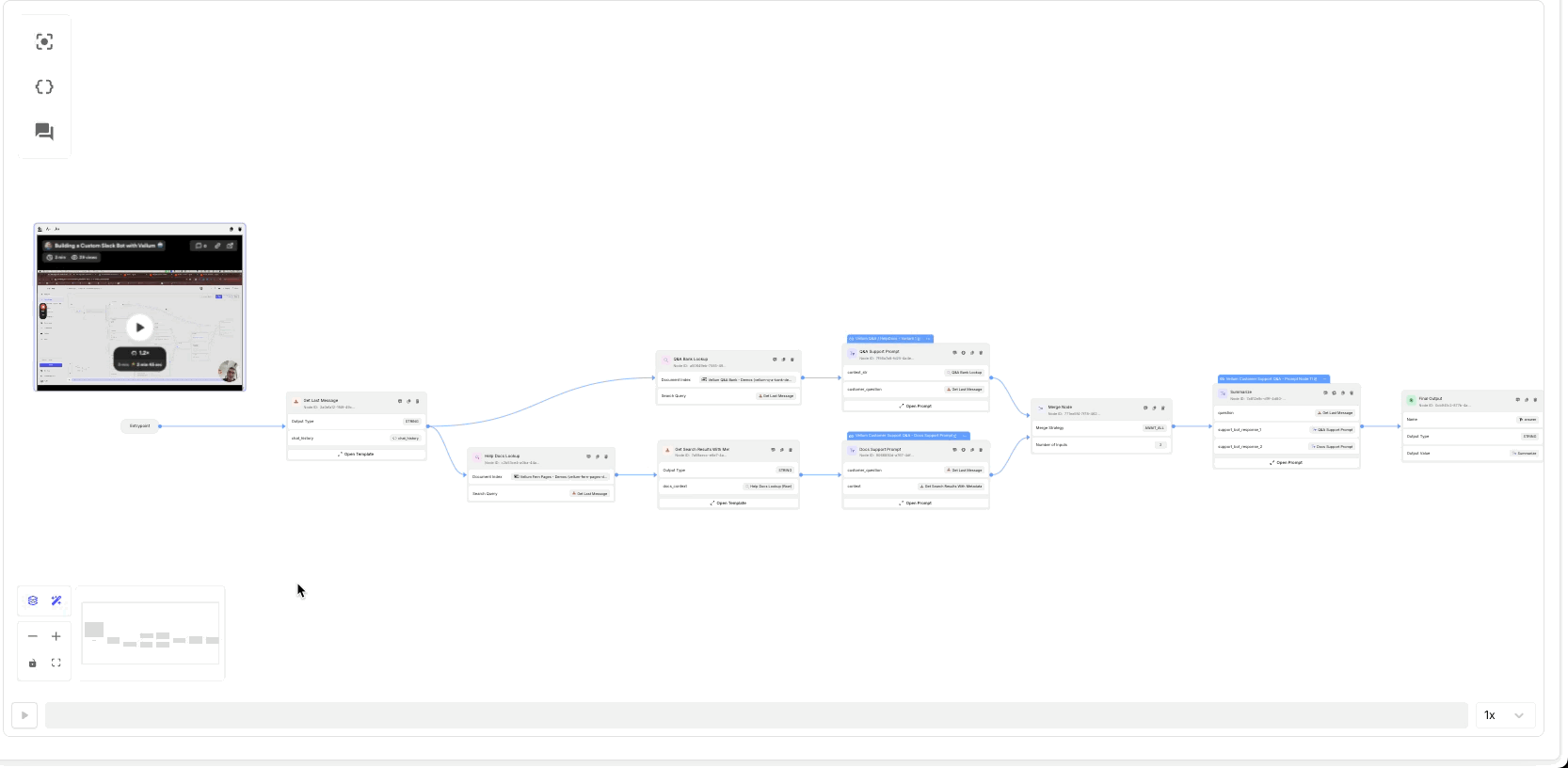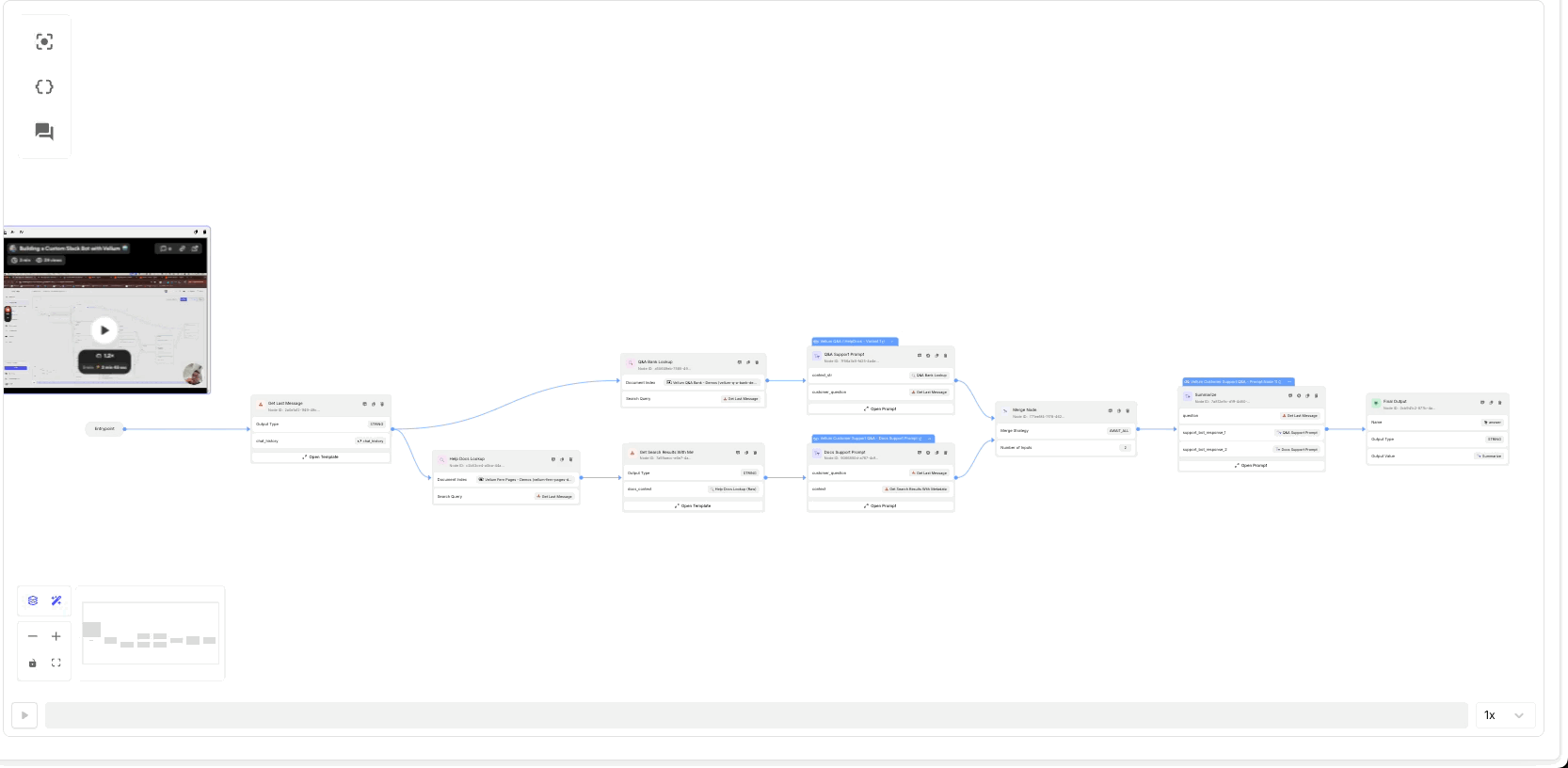
AutoLayout and AutoConnect for Workflows
As you experiment and your workflows become more complex, keeping them organized will make them easier to iterate on. Now, you can automatically organize and connect nodes in Workflow Sandboxes with just a click.
Datadog and Webhook Logging Beta Integrations
If you want deeper insights into key events happening in Vellum, but in the context of the rest of your systems, now you have it with our Datadog & Webhook Logging integrations (in beta). For example, you can set up a Datadog alert to fire when there are multiple subsequent failures when executing a Workflow Deployment.
If you’d like to participate in the Beta Period and want help setting up their integration, please contact us!
New Models and Providers!
Model optionality gives builders more flexibility to optimize for accuracy, latency, and cost, as use-cases necessitate. Here’s a quick overview of the 25 (!!) new models we added in October:
All Perplexity models — including Online models for searching the web! Cerebras — featuring 2,100 tokens/sec. That’s 3x faster than the current state of the art, or nearly 3 books per minute! 13 new OpenRouter models The newest Claude 3.5 Sonnet Gemini 1.5 Flash 8B
Other noteworthy mentions:
Vertex AI embedding models: text-embedding-004 and text-multilingual-embedding-002 OpenAI Prompt Caching for GPT-4o and GPT-o1 models
Click here to see more details about the new models we’re supporting.
Evaluations
Reorder Test Suite Variables
You can now reorder Input and Evaluation Variables within a Test Suite’s settings page, helping you stay organized & make changes faster by putting related values next to one another.

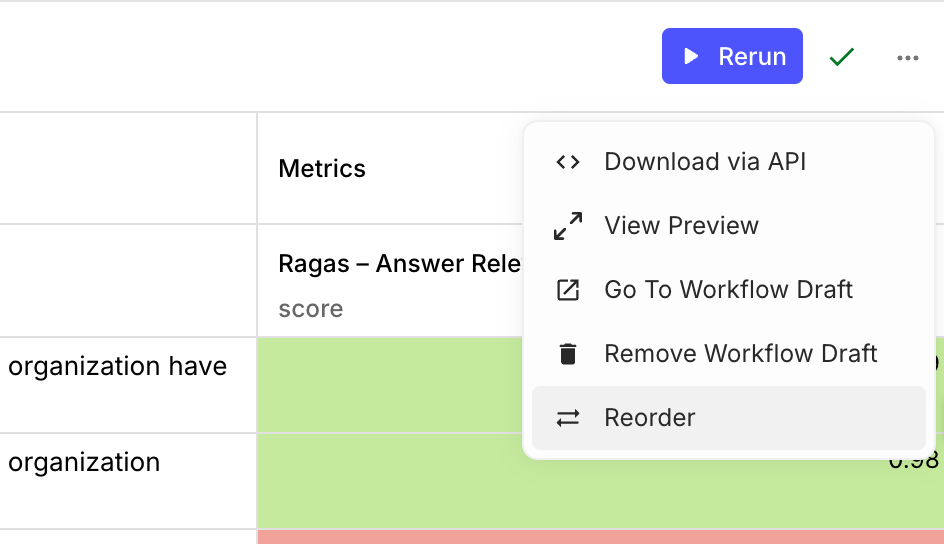
Reorder Entities in Evaluation Reports
When your Evaluation Reports use many Metrics, often you want to see related Metrics grouped nearby one another. You can now reorder entities in the Evaluation Report table, making it easier to triage your Metric scores and iterate on your Prompts & Workflows accordingly.
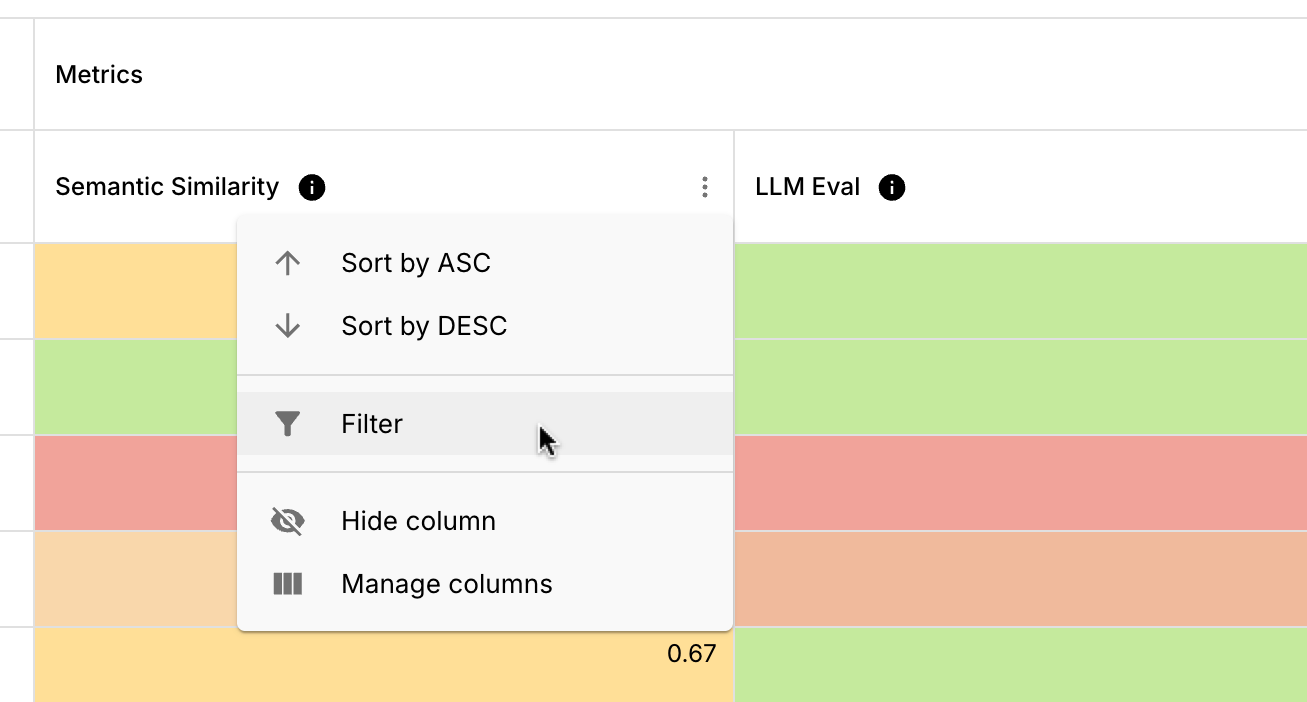
Filter and Sort on Metric Scores
You can now filter and sort on a Metric’s score within Evaluation Reports. This makes it easier to find all Test Cases that fall below a given Metric threshold, so you can iterate and improve your products’ robustness faster.
Prompts, Models, and Embeddings
Prompt Caching Support for OpenAI
OpenAI now automatically performs prompt caching to help optimize cost & latency of prompts. In Vellum, we capture the new Cache Tokens when using supported OpenAI models, to help you analyze cache hit rates and optimize LLM spend.
Vertex AI Embedding Model Support
We now support Vertex AI Embedding Models: text-embedding-004 and text-multilingual-embedding-002 , giving you more options to optimize your RAG pipelines.
New Models!
That’s right, 25 new models.
Provider / Router Model Description Cerebras llama3.1-8b Lightning fast at 1,800 tokens/sec Cerebras llama3.1-70b Lightning fast at 2,100 tokens/sec Anthropic Claude 3.5 Sonnet 2024-10-22 Across the board improvements but particularly in coding Anthropic Claude 3.5 Haiku Matches the performance of Claude 3 Opus, Anthropic’s prior largest model, on most evaluations Perplexity LLama 3.1 Sonar Small 128k Online Designed for efficient online interactions, balancing performance and resource usage Perplexity LLama 3.1 Sonar Large 128k Online Offers enhanced capabilities for more complex tasks, with improved accuracy and depth Perplexity LLama 3.1 Sonar Huge 128k Online Excels in handling intricate queries requiring deep reasoning and extensive context Perplexity Perplexity AI: LLama 3.1 Sonar Small 128k Chat Optimized for chat applications, facilitating fluid and contextually rich conversations Perplexity Perplexity AI: LLama 3.1 Sonar Large 128k Chat Enhances chat interactions with greater depth and understanding for demanding conversational agents Perplexity Perplexity AI: LLama 3.1 8B Instruct Instruction-tuned model ideal for tasks requiring precise adherence to instructions Perplexity Perplexity AI: LLama 3.1 70B Instruct Handles complex tasks with high accuracy and reliability Google Gemini 1.5 Flash 8B Lightweight, smaller, and faster OpenRouter Magnum v2 72B Designed to achieve prose quality similar to Claude 3 models OpenRouter Magnum v4 72B Replicates prose quality of the Claude 3 models, specifically Sonnet and Opus OpenRouter LLama 3.1 Lumimaid 70B Lumimaid v0.2 70B is a fine-tune with a substantial dataset upgrade compared to Lumimaid v0.1 OpenRouter Nous: Hermes 3 405B Instruct A frontier-level, full-parameter fine-tune of the Llama-3.1 405B foundation model OpenRouter NousResearch: Hermes 2 Pro - Llama-3 8B An upgraded version of Nous Hermes 2 with improved capabilities OpenRouter Nous: Hermes 3 405B Instruct (extended) An extended context version of Hermes 3 405B Instruct OpenRouter Goliath 120B Combines two fine-tuned Llama 70B models OpenRouter Dolphin 2.9.2 Mixtral 8x22B An uncensored model for instruction following, conversation, and coding OpenRouter Anthropic: Claude 3.5 Sonnet (self-moderated) A faster, self-moderated endpoint of Claude 3.5 Sonnet OpenRouter Liquid: LFM 40B MoE A 40.3B Mixture of Experts (MoE) model for general-purpose AI tasks OpenRouter Eva Qwen 2.5 14B A powerful model based on the Qwen architecture OpenRouter Rocinante 12B A versatile 12 billion parameter model OpenRouter WizardLM-2 8x22B Microsoft AI's most advanced Wizard model
Deployments:
New API for Listing Entities in a Folder
Now you can programmatically retrieve all entities in a folder via API. The response lists these entities along with high-level metadata about them.
This new API is available in our SDKs beginning with version 0.8.25. For additional details, check out our API Reference here .
Quality of Life Improvements
Workflow Edge Type Improvements
Edges between Nodes in Workflows could appear jagged or misaligned, making it difficult to visualize connections. With this new improvement, edges now snap into straight-line connectors when they are close to horizontal.
See you in December!
That’s all for now folks. We hope you have a wonderful November, filled with lots of food & fall activities. See ya in December!
PSA - sign up for our newsletter to get these updates in right your inbox!