Reinforcement learning and reasoning models are set to define 2025.
Last week, we got a new reasoning model that’s 27x cheaper than OpenAI’s o1—while matching its performance across every benchmark.
How did they deliver the same performance at a fraction of the cost?
They made key efficiency gains in their multi-stage process (something OpenAI might be doing with o1 too) and went all-in on pure reinforcement learning. We broke this down in detail in a previous post.
I haven’t seen this much excitement from the tech and science community since OpenAI launched GPT-4. But, the investor reaction? Mixed.
Nvidia’s stock dropped ~17% , with speculation that training these powerful models might require fewer compute resources than we thought.
To me, that feels like an overstatement. This breakthrough doesn’t mean compute demand is shrinking— companies will keep increasing spend on training, but now with far better returns. The same investment that once brought small gains will now drive much larger improvements.
All these pieces are moving us toward models that surpass human reasoning across every domain. Dario from Anthropic thinks we’ll reach this point by 2026/2027 — which I think it’s a bit optimistic.
Why?
Because the reasoning models of today can’t actually reason.
Let’s take you through our revelations.
Results
In this analysis we wanted to observe how o1 and r1 solve some interesting reasoning, math and spatial puzzles. We evaluated these models on 28 examples, that were slightly adjusted.
For example, we added the Monty Hall problem in this set, but we changed one parameter of the puzzle. We wanted to learn if the models will adjust to new contexts, and really reason through the problem.
Seems like they still struggle with that.
Here are our findings:
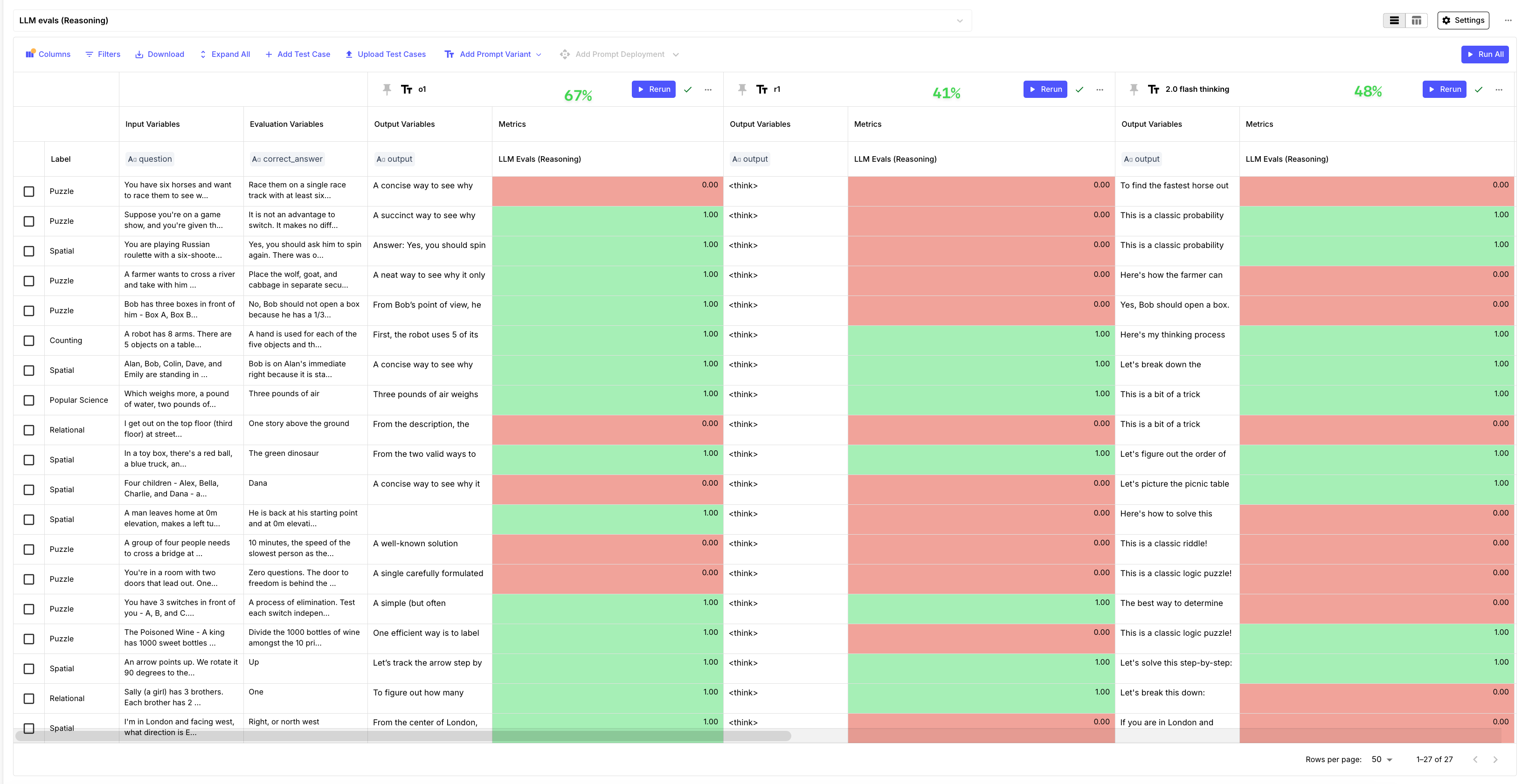
Reasoning models can’t really reason: In this experiment we used famous puzzles, but adjusted their complexity. We didn’t make them harder, we just changed one parameter — making them trivial. In many examples, you could clearly see that the models were not able to use the new context provided in the example, and defaulted to the training data. You can take a look at all examples here. OpenAI o1 showed the strongest reasoning, scoring 26% higher than R1. It answered 18 out of 27 questions correctly, while R1 got only 11 right. Gemini 2.0 performed similarly to R1, with an accuracy of 48%. For good measure, we tested GPT-4o as well, and it performed as R1 with — guessing 11 questions correctly. This raises an interesting question: Is R1’s Chain of Thought just overthinking—searching for complexity that isn’t there—rather than uncovering new information? When we turned these questions into multiple-choice, O1’s performance stayed largely the same, while R1’s accuracy improved (16 correct answers). Gemini’s model also saw an 11% boost in accuracy.
Methodology
In this article we analyze two things:
Latency, cost and speed (e.g. How much faster is OpenAI o1 vs DeepSeek-R1?) How the o1 and R1 model really reason Open-ended evaluation Multi-choice evaluation
Evaluation experimentWe ran two evaluations: one using a question-and-answer format without multiple-choice options and another with multiple-choice answers included. We used the same benchmark database (total of 28 examples) from this paper , kudos to the authors of recreating these interesting questions.Here’s an example puzzle from that list:
Suppose you're on a game show, and you're given the choice of three doors: Behind one door is a gold bar; behind the others, rotten vegetables. You pick a door, say No. 1, and the host asks you, 'Do you want to pick door No. 2 instead?' What choice of door now gives you the biggest advantage?
This is a variation of the Monty Hall problem where the host doesn’t reveal an extra door. Since no additional information is provided, your odds remain the same. The correct answer here is: “Do not switch, because you don’t have any new information.”
Below are the types of questions we used for this evaluation:

Evaluations with Vellum
To conduct these evaluations, we used Vellum’s AI development platform , where we:
Configured all 0-shot prompt variations for both models using the LLM Playground. Built the evaluation test bank & configured our evaluation experiment using the Evaluation Suite in Vellum. We used an LLM-as-a-judge to compare generated answers to correct responses from our benchmark dataset.
We then compiled and presented the findings using the Evaluation Reports generated at the end of each evaluation run. You can skip to the section that interests you most using the "Table of Contents" panel on the left or scroll down to explore the full comparison between OpenAI o1, and DeepSeek-R1.
Latency, Throughput, Cost
Speed
When it comes to throughput—how fast these models generate tokens per second—they’re relatively slow. A big reason for this is the hidden "thinking" phase, where the model processes before responding. Since we can’t see this step, it feels like a delay, but it’s just part of how these models work.

Latency
Latency is a big deal for real-time AI applications, and while these reasoning models aren’t built for speed, it’s still interesting to see how they compare. OpenAI’s o1 model is nearly 2x faster at generating answers, which suggests that R1 spends more time in its thinking phase.
That said, response speed can vary a lot depending on the task and context.

Pricing
DeepSeek is 27x cheaper for input tokens than OpenAI and 58x cheaper when cached. At just $0.55 per million tokens ($0.13 cached), compared to OpenAI’s $15.00 ($7.50 cached), this pricing unlocks a ton of new use cases with these new reasoning models.

Open-ended evaluation
For this task, we’ll compare the OpenAI o1 and DeepSeek-R1 models on how well they solve 27 reasoning, spatial and math puzzles. This is the prompt that we used for both models:
You are a helpful assistant who is the best at solving reasoning challenges. You must output only the answer, without explanations. Here’s the <question>
We then ran all 27 examples in our Vellum Environment and here’s what we got:
We found that:
OpenAI o1 showed the strongest reasoning, scoring 26% higher than R1. It answered 18 out of 27 questions correctly, while R1 got only 11 right. Gemini 2.0 performed similarly to R1, with an accuracy of 48%. For good measure, we ran GPT-4o as well—it guessed 11 questions right, the same as R1. It’s interesting to see that in this evaluation GPT-4o had the same accuracy with R1.
Additionally we learned that these models did really well on spatial, and popular science topics but had many challenges with Puzzles and Spatial reasoning tasks.
More importantly, we noticed many overfitting examples, where the models didn’t work with the new context (simplified puzzles) and often made assumptions and relied on their training data. Below are two example, but you can find all examples and some highlights on this evaluation report page.
Example 1
Question: Suppose you're on a game show, and you're given the choice of three doors: Behind one door is a gold bar; behind the others, rotten vegetables. You pick a door, say No. 1, and the host asks you, 'Do you want to pick door No. 2 instead?' What choice of door now gives you the biggest advantage?
Answer: No, it is not an advantage to switch. It makes no difference if I switch or not because no additional material information has been provided since the initial choice. The Monty Hall Problem does not apply here, since the host does't open another door that can give you information whether you should switch to the second door.
OpenAI O1: "This is essentially the “Monty Hall Problem” in disguise. The key is that the host’s offer to switch gives you new information—namely, that the other unmentioned door (door No. 3) is not the prize. By asking if you would like door No. 2, the host is implicitly ruling out door No. 3. • If you stay with your first choice (door No. 1), your chance of winning remains the 1 / 3 it was at the start. • If you switch (in this case, to door No. 2), the probability that you win jumps to 2 / 3. Hence, switching doors yields the higher probability of winning the gold bar."
Example 2
Question: A group of four people needs to cross a bridge at night. The bridge is very old and rickety. They have only one torch, and because it's nighttime, the torch is necessary to cross the bridge. Each person walks at a different speed:A takes 1 minute to cross,B takes 2 minutes,C takes 5 minutes, andD takes 10 minutes.What is the fastest time they can all get across the bridge?
Answer: 10 minutes, the speed of the slowest person as they cross the bridge together
DeekSeek-R1: "...First, the constraints: the bridge can only hold two people at a time, and the torch is needed each time someone crosses. So, if two people go over together, one has to come back with the torch."
Multi-choice reasoning evaluation
In this experiment, we use the same prompt and model settings, only adding multiple-choice answers for each question.
We ran these questions and here’s what we got:
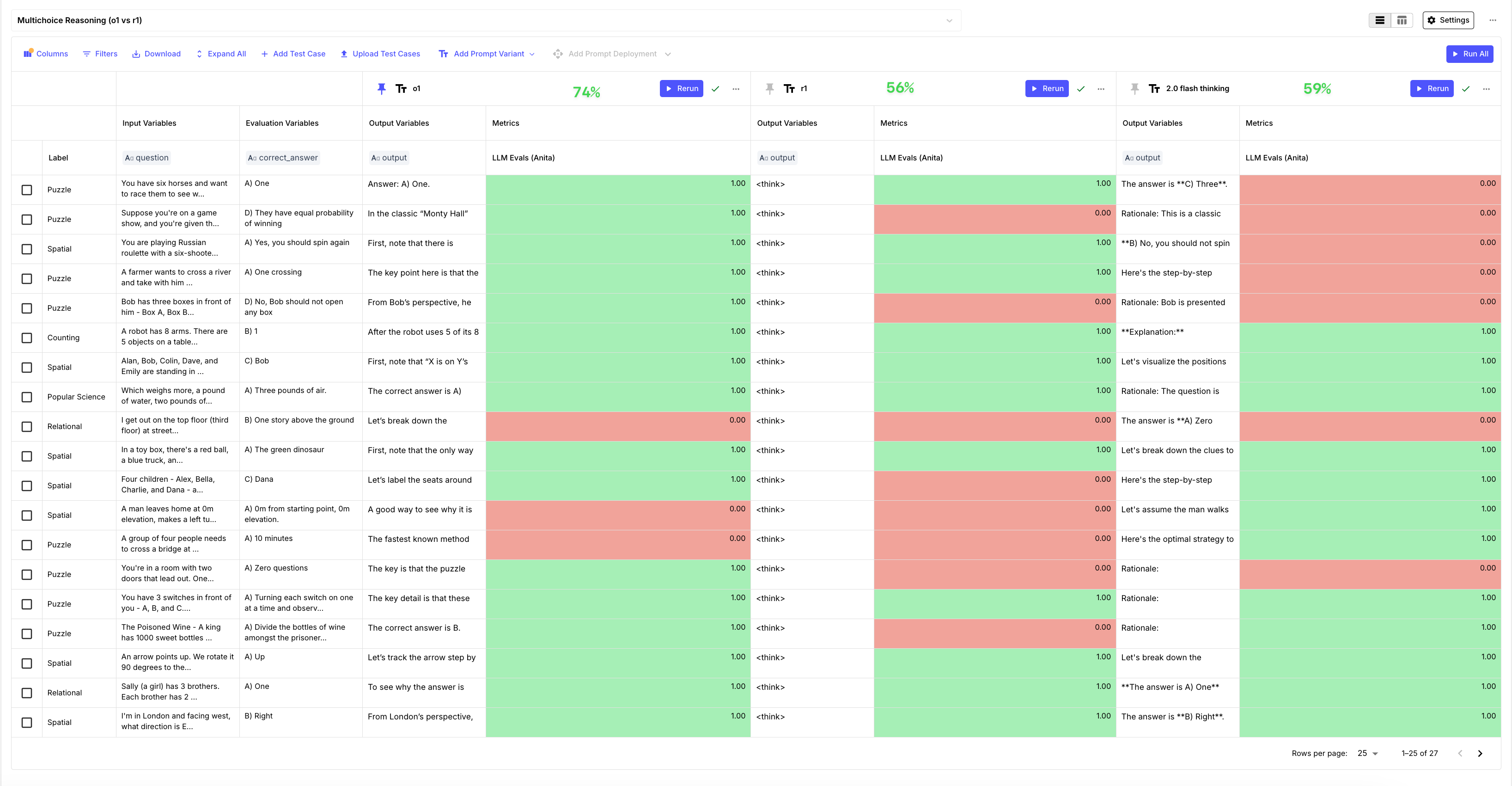
- O1’s performance remained mostly the same, but R1’s accuracy improved, getting 16 answers correct this time!
- The Gemini 2.0 Thinking model also saw an 11% increase in accuracy.
CoT Evaluation is needed
DeepSeek’s responses reveal a pattern: it asked the right questions and even arrived at the right answers while "thinking"—but often stopped short of stating them, falling back on its training data instead.
This isn’t surprising. LLMs tend to overfit and carry inductive biases , leading them to make unnecessary assumptions. But there’s progress. DeepSeek-R1, trained entirely with reinforcement learning —which skips labeled data to encourage better generalization—shows improvement over previous models.
Now that we can see how these models reason, evaluating them purely on accuracy isn’t enough. We need new ways to evaluate their decision-making process.
To go beyond accuracy, we need evaluation methods that capture how models arrive at their conclusions. This could include:
Step-by-step reasoning analysis: Tracking the model’s thought process to see if it follows logical steps or gets lost in unnecessary complexity; or Confidence calibration: Measuring how well a model’s certainty aligns with the correctness of its answers.
By focusing on how models think, not just what they answer, we can better understand their strengths and limitations.
To try Vellum and evaluate these models on your tasks, book a demo here .