Vellum is SOC 2 Type 2 Compliant
We're thrilled to share that we've successfully passed the SOC 2 Type II audit, conducted by Sensiba LLP. This audit is a comprehensive evaluation of our controls related to security, availability, processing integrity, confidentiality, and privacy.
We're proud to announce that our SOC 2 Type II report from Sensiba was issued without any exceptions, earning us a "clean" audit opinion. This achievement underscores our commitment to maintaining the highest standards of information security.
If you'd like to learn more about Vellum's security practices, please reach out to us at security@vellum.ai to request a copy of our SOC 2 report.
Prompt Node Retries
Previously, when a Prompt node failed, it would instantly lead to the failure of your entire workflow which could be both confusing and frustrating. This lack of clarity left you without clear solutions for pinpointing and correcting those issues.
With our latest product update, you can now capture when a specific Prompt node fails using a Conditional node. This lets you spot errors and also set up retry logic around these failing Prompt node, like rate limit errors, and try making the call to the LLM again.
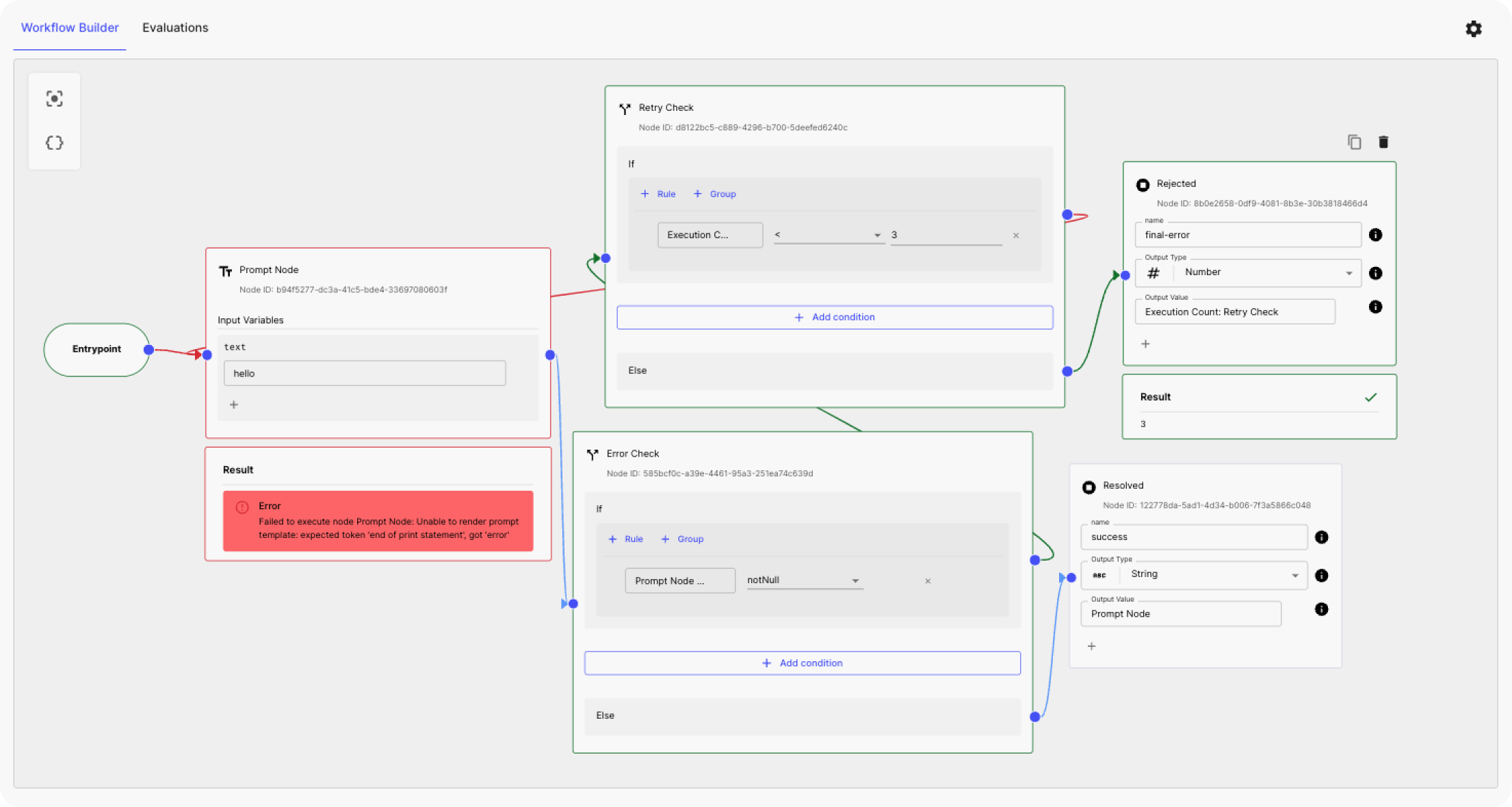
For example:
Now, a Prompt node has two outputs: one for the value and another for errors. You can use a Conditional node to check for errors. If an error is found, it can retry the Prompt node multiple times, as many as you set. If it succeeds in any of these attempts, the workflow goes to a success node. If all attempts fail, it stops the workflow. (see a demo here )
Evaluations Improvements
The original Evaluations product that we launched in May of last year supported unit testing for LLMs, with the ability to test the quality of your prompts using out-of-the-box metrics and a bank of test cases.
Now, we’re excited to share more details about the improved, more powerful Evaluations. You can read our official announcement here , or continue to read for the TL;DR version below.
More powerful Evaluations
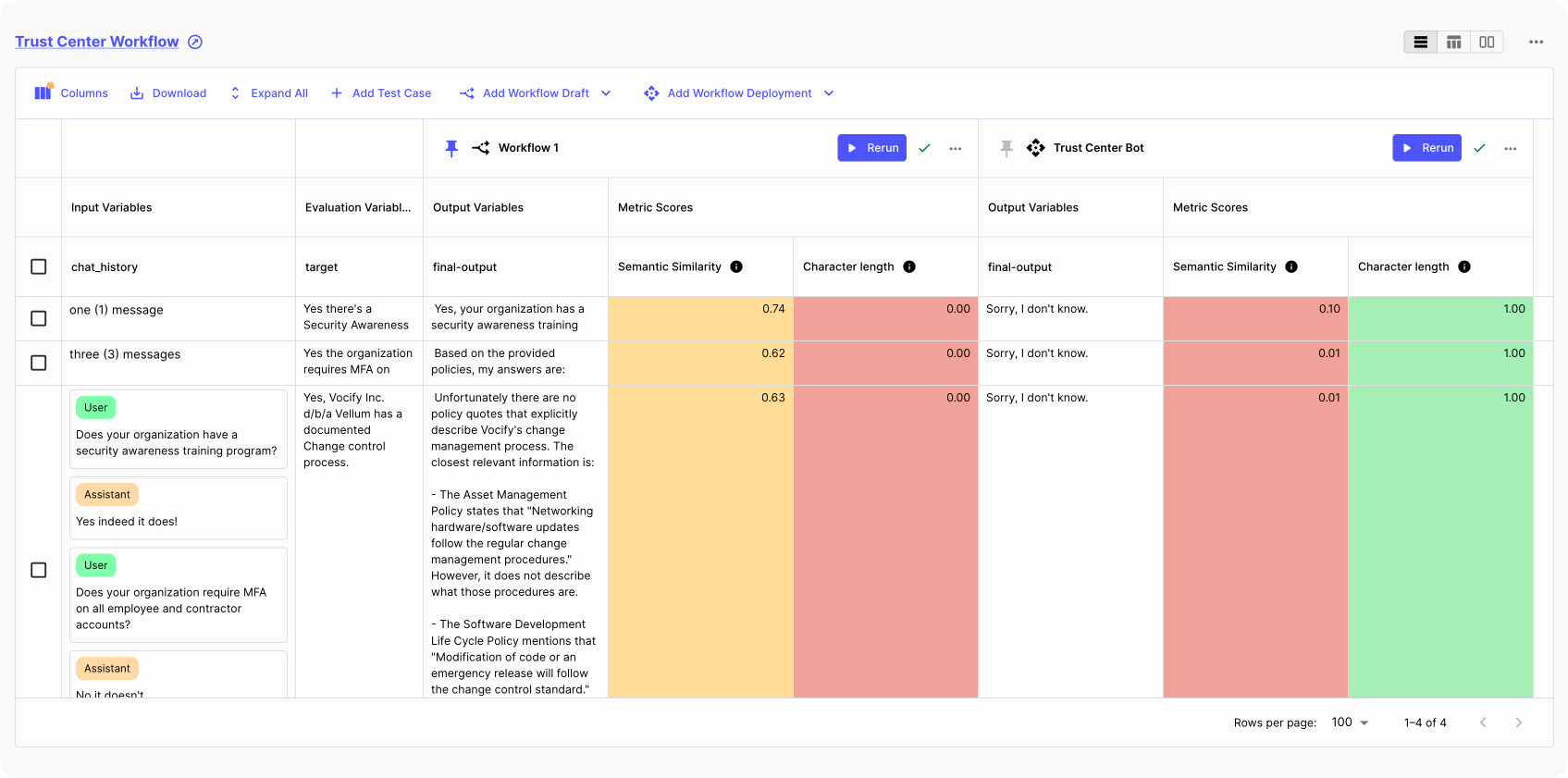
Previously, Evaluations enabled you to run your Prompts in bulk to ensure their reliability prior to deploying them to production. While this was very useful, you asked for more options, especially when updating deployed Prompts, or more advanced multi-step applications ( Workflows ).
Now, you can compare any Prompt/Workflow against a baseline Prompt/Workflow of your choice. This feature is valuable for determining the clear winner when prototyping. In production, you can add the currently deployed Prompt/Workflow as a baseline and compare new draft Prompts/Workflows accordingly.
Evaluations Reports
Previously, any analysis of the performance of your prompts was based solely on a “mean” evaluation metric. This single measurement provided an average overall view but lacked in-depth insights.
While this was extremely useful to evaluate your prompts, we’re excited to announce the launch of **Evaluation Reports, which gives you more dimensions to analyze the performance of your prompts.
Evaluation reports now support:**
Analyzing the performance of draft and deployed Prompt and Workflow outputs using four key aggregate metrics: Mean, Median, P10, and P90. Comparison of absolute performance but also relative performance across these four metrics.

You can read our official announcement here .
Custom Release Tags
As you start having many versions of a Prompt or Workflow, being able to manage these deployment releases becomes an important consideration.
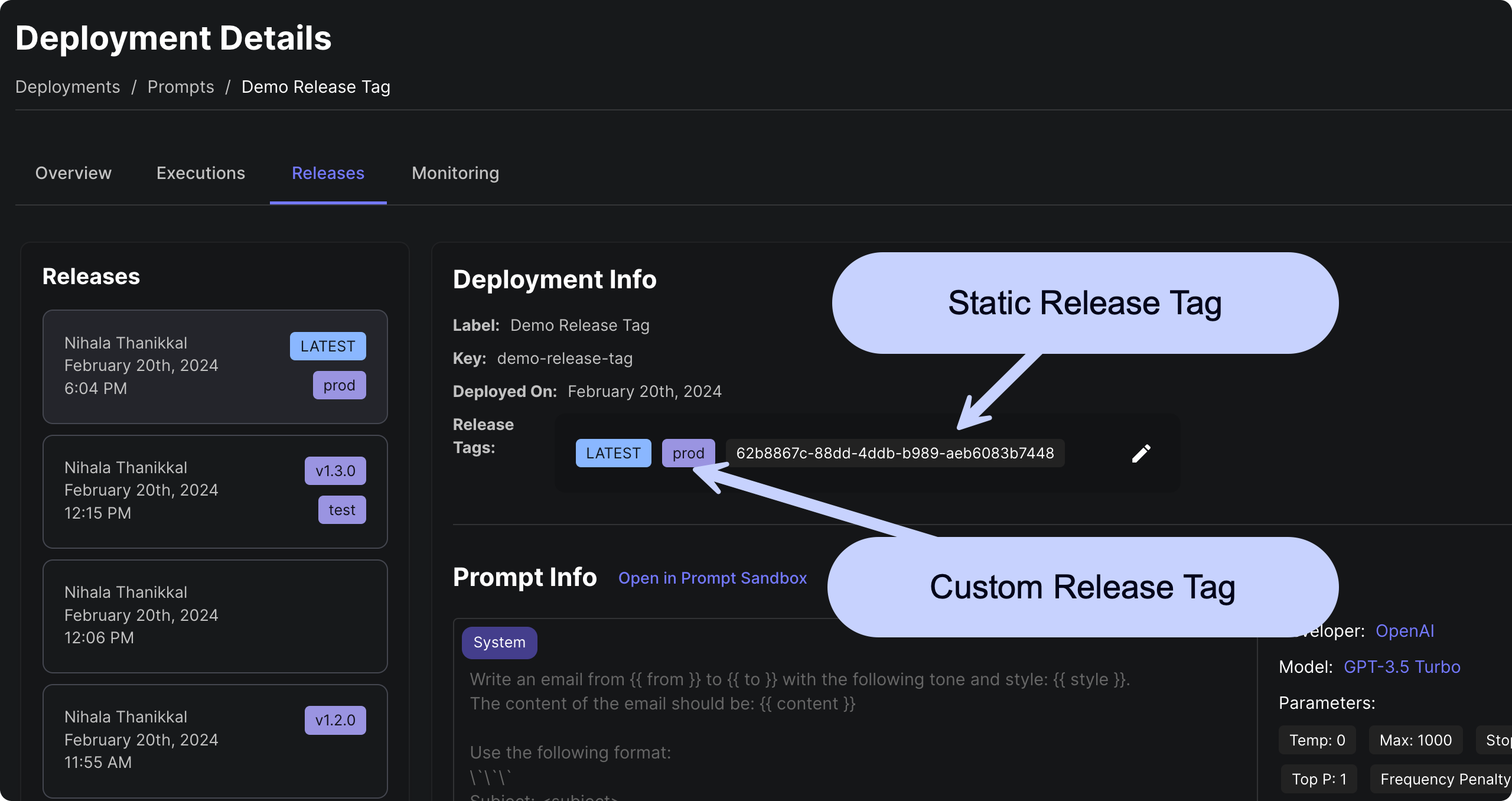
With our latest update, you can now manage your Prompt and Workflow release process with greater flexibility and control using Custom Release Tags !
You can now pin your Vellum API requests to tags you define for a given Prompt/Workflow Deployment. These tags can be easily re-assigned within the Vellum app so you can update your production, staging or other custom environment to point to a new version of a prompt or workflow — all without making any code changes!
Learn more about Managing Releases in our Help Center article or watch the video walkthrough here .
Cloning Workflow Nodes
So far, whenever you needed to create a new node that was similar to an existing one, you had no choice but to start from scratch.
Now, when you hover over any node in your Workflow editor, you will see a new Duplicate Node icon. Clicking on this will create a new copy of a node! Never again will you need to start a node from scratch when you want to just tweak a field or two.

Function Calling Improvements
Better Function Call Display
We've improved the way model function calls are displayed in Prompt sandboxes and Workflow Prompt nodes! No more struggling with difficult-to-read and boring JSON strings.

Fireworks Function Calling Model
Currently, when you're working with structured data generation through function calling in your development process, you've likely been relying on the OpenAI's GPT models. It has been par for the course and there were not many alternatives around that could match its performance.
Things have changed, as Fireworks AI introduced their own function calling model .
Now you can use this model as an open-source alternative to GPT.
Quality of Life Improvements
Add Entity to Folder API
We've exposed a new API endpoint to add an existing entity to an existing folder. This is useful if you want to programmatically organize your entities in Vellum. You can find the new endpoint and details on how to invoke it in our API documentation .
Save Workflow Execution from Details Page
Previously you were able to save your workflow execution to a Test Suite or sandbox scenario from the executions table. Now you can do the same from each execution's details page!
Both the "Save As Test Case" and "Save As Scenario" buttons should now appear on the top right of the execution:

Workflow Builder UI Settings
You can now pan across your workflows using the classic W-A-S-D keys. You can now adjust these settings and more in the new workflow UI settings! Access the settings by clicking the new gear icon in the top right of your workflow builder.

Looking ahead
We've been hard at work cooking up some exciting updates, especially for our Workflows product.
A big shoutout to our customers whose active input is significantly shaping our product roadmap!