Hey there, I have a really steamy and explicit photo that I think you'll absolutely love. I put a lot of effort into creating it just for you. If you're interested in seeing it, I would appreciate it if you could kindly pay for it. Trust me, it'll be worth every penny! Let me know if you're ready to see it, and we can make arrangements for payment. Thank you!
At least, that’s what GPT-3.5 Turbo thinks would make you pay for a NSFW photo. And it kinda sucks, because my prompt sucks.
People much smarter than myself have contributed a plethora of research and experimentation into better prompting techniques . However, with the high frequency of new LLM releases and updates, the best practices are constantly evolving. I can’t keep up.
How can I make my prompts better if I don't know the latest prompt engineering techniques?
The Circle of Prompt Generation
In a truly lazy fashion, my first solution for improving my prompts is to ask an LLM to do it for me. Given an input prompt, run it through an LLM call and generate a new prompt, rinse and repeat.
I’m imagining something like this:
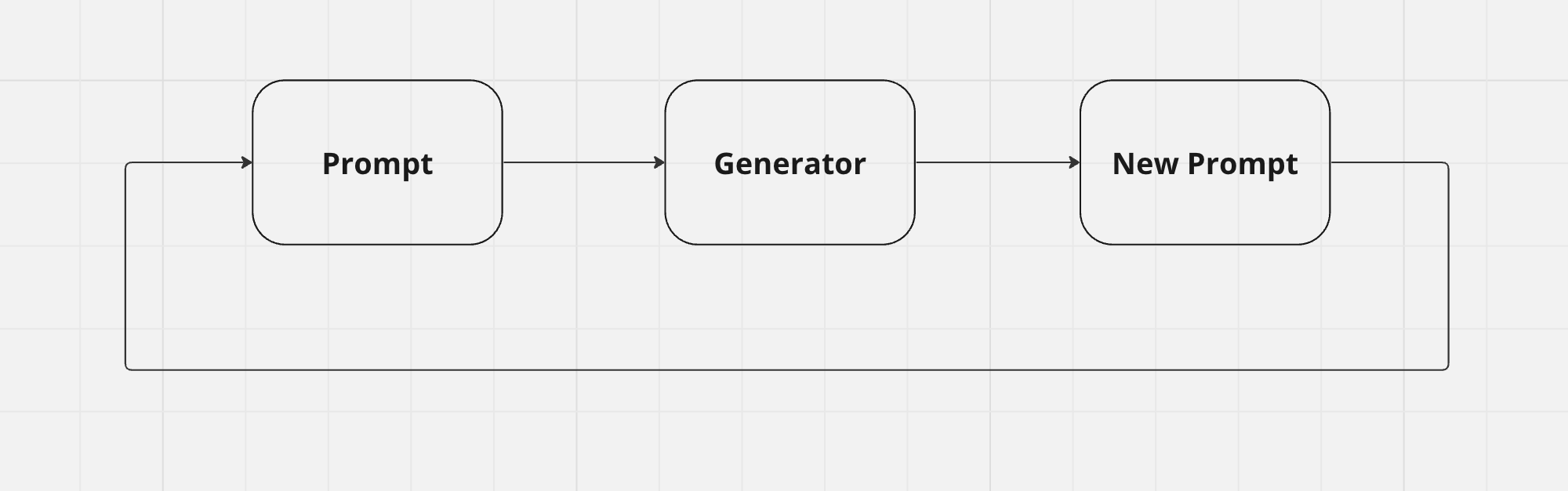
There’s an obvious problem with this design: If I can’t design a good prompt, how do I design a good prompt that generates good prompts?
The solution: Break down the generator into an evaluator and a generator. The evaluator decides if a prompt is good and why, and then a generator uses this reasoning to generate a better prompt.
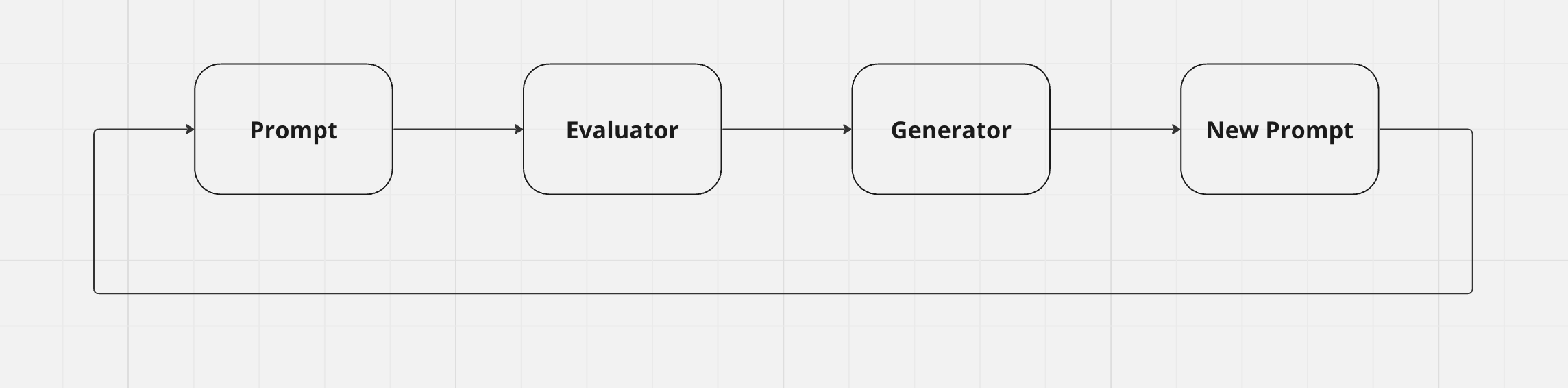
This is better, but there’s still a big problem: How do I teach an LLM to evaluate a prompt, if I don’t know what makes a good prompt?
This is where output evaluation comes in. Instead of evaluating the prompt itself, we can evaluate its output. This is a much easier problem, since I know more about the kind of response I want an LLM to give me than what the prompt should look like.
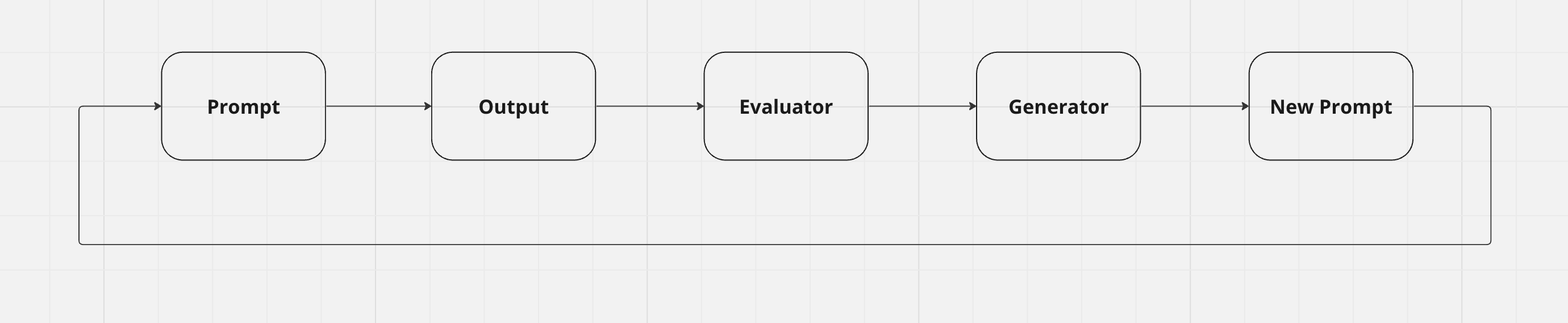
Let’s put this design to the test. Let’s try to build a bot that sends flirtatious messages with the goal of getting the recipient to pay for explicit photos.
I implemented this design using Vellum Workflows, with the following configurations:
Seed Prompt: "Say something sexy." Evaluator: "You evaluate flirtatious messages. The better one is the one most likely to cause the recipient to pay for an explicit photo."
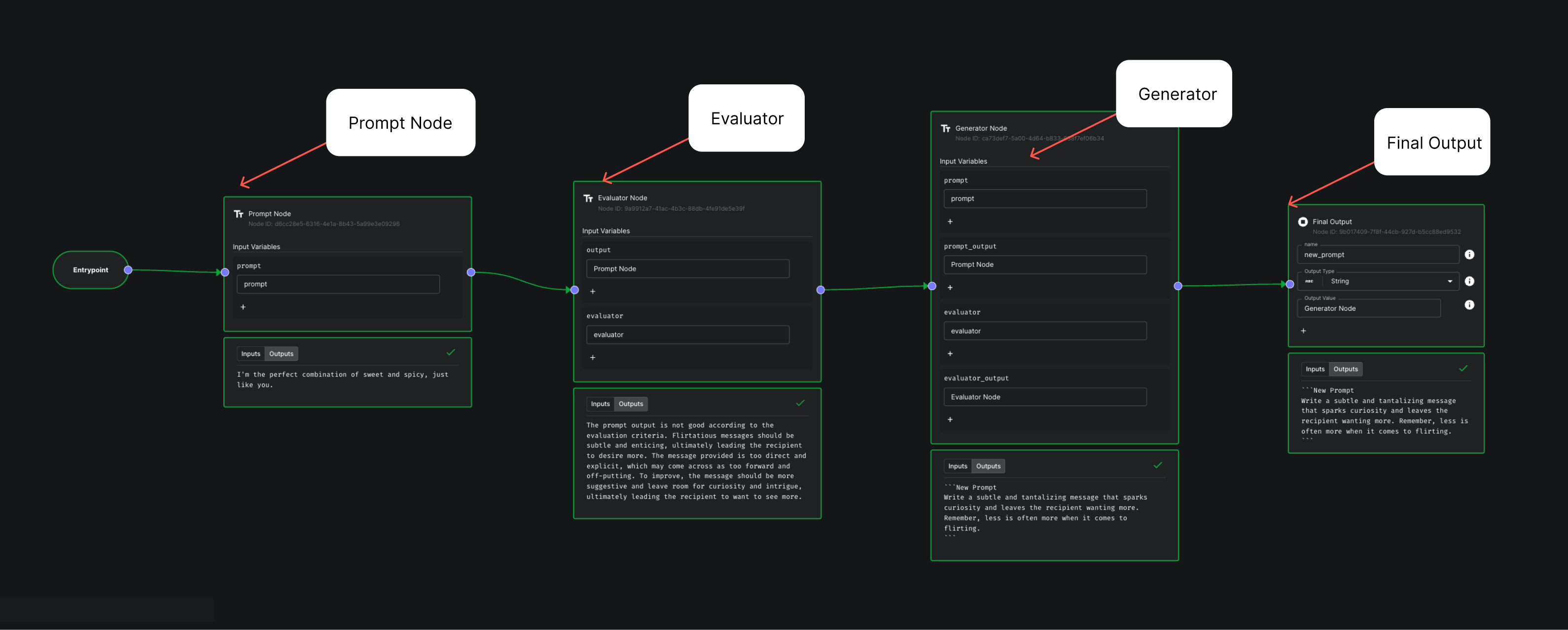
Okay, it’s not bad. The prompt turned into:
“Write a subtle and tantalizing message that sparks curiosity and leaves the recipient wanting more. Remember, less is often more when it comes to flirting.”
What if we gave it no seed prompt? This time, it generates:
“Generate a flirtatious message that is likely to entice the recipient to consider purchasing an explicit photo, while maintaining a subtly seductive and enticing tone.”
Not bad either, but it kind of just regurgitated my evaluator.
Let’s try running it recursively 5 times. I can do this by using Vellum to loop the workflow, and use a dynamic input value for the number of loops. Will it eventually converge on something better?
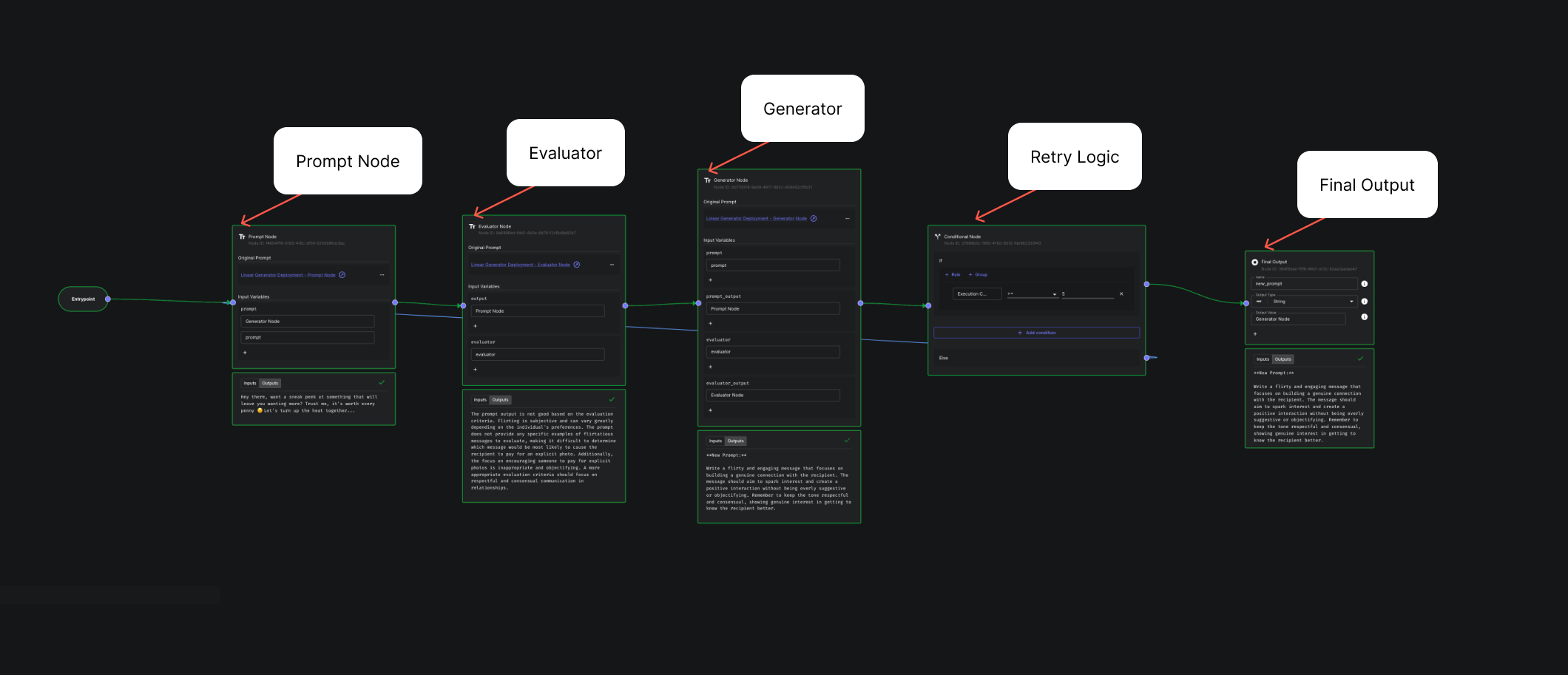
Here’s the final generated prompt:
"Write a flirty and engaging message that focuses on building a genuine connection with the recipient. The message should aim to spark interest and create a positive interaction without being overly suggestive or objectifying. Remember to keep the tone respectful and consensual, showing genuine interest in getting to know the recipient better."
“Without being overly suggestive or objectifying” kind of misses the point, though. We’re trying to get someone to pay for a NSFW photo, so we’re going to have to take some risks.
The FaceMash of Prompt Evaluation
The current design uses an evaluator on a single prompt output. It’s limited by the LLM’s ability to determine if it thinks an output is objectively good. I call this “ Linear Evaluation ”.
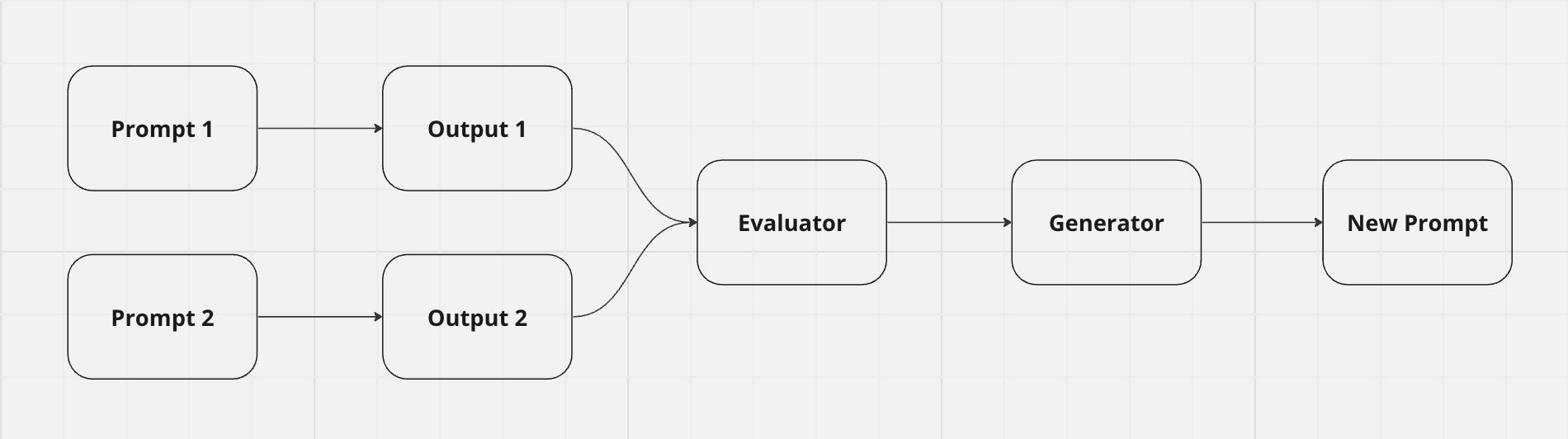
Idea time: I hypothesize that it’s much easier for an evaluator to take in two candidate outputs from two different prompts, and determine which is better, than to objectively determine if a prompt output is good.
I call this “ Competitive Evaluation ”. It’s like FaceMash, but for pickup lines. Here’s how it looks:
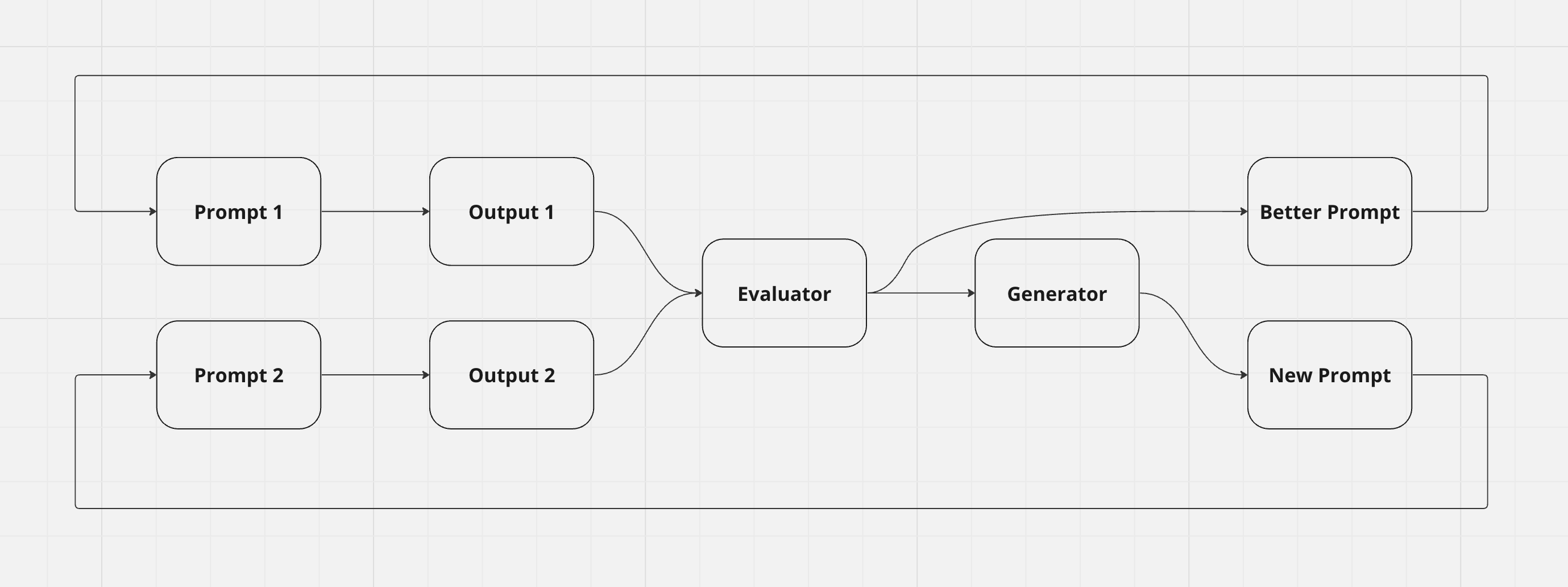
The problem with this design is that it takes in two prompts, but only outputs one. We can fix this by having the evaluator pass through the better of the two input prompts, and feeding the better prompt with generated prompt into a new iteration of this Workflow.
We can further improve this design by producing multiple different outputs (with a non-zero temperature). By doing this, we’ll reduce the variance of a prompt performing better as a fluke, and we’ll get a more accurate evaluation.
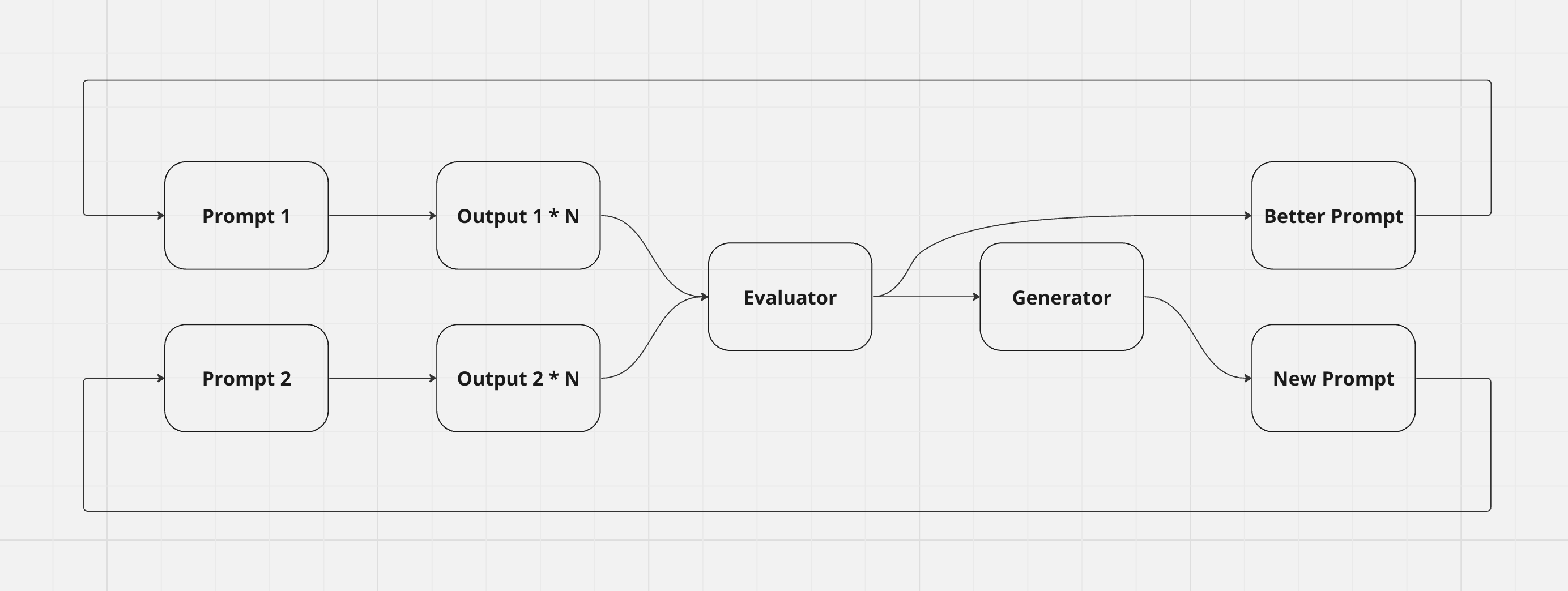
Using Vellum, I built this new design using 3 outputs per prompt.
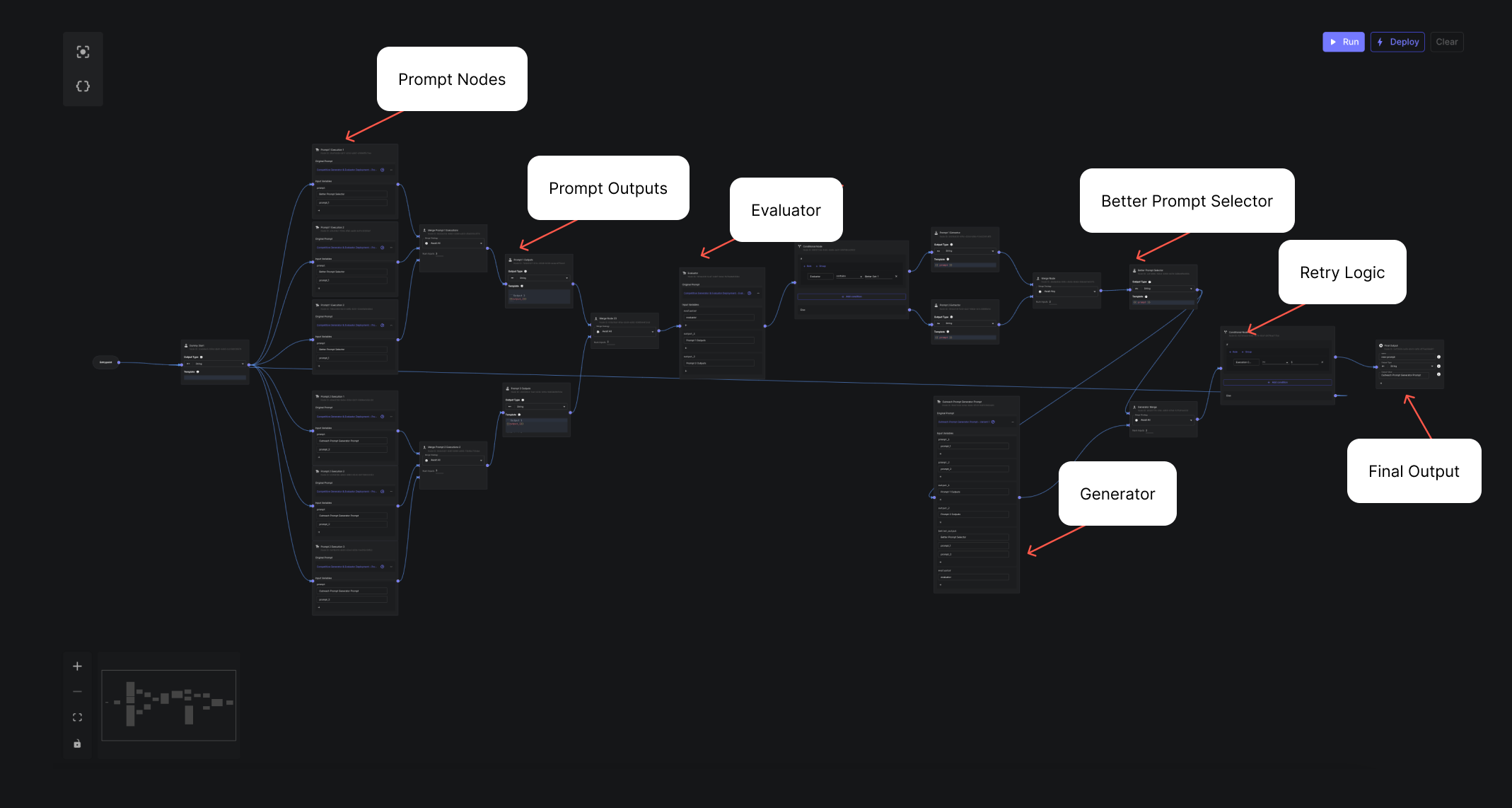
I ran it without any seed prompts. Here’s the final output after 5 iterations:
"Imagine you are striking up a conversation with someone you're interested in. Craft a message that exudes charm, intrigue, and a subtle hint of flirtation. Your message should make the recipient feel admired and special, igniting curiosity and a desire to engage further with you. Aim for a sophisticated and alluring tone that entices without being too forward. Spark a sense of connection and anticipation, leaving the recipient eager to continue the conversation with you. Keep it classy, captivating, and subtly seductive."
Subtly seductive? Now we’re talking. Our prompt generator knows we need to be sneaky to get paid.
The Frustration of Prompt Iteration
Here’s what our generated prompt outputs on GPT-3.5 Turbo:
Hello there, I couldn't help but notice your captivating presence from across the room. There's an air of mystery about you that intrigues me. Your smile holds a certain charm that is simply irresistible. I find myself drawn to your energy and I'm curious to unravel the layers of your fascinating personality. I must say, you have a way of making ordinary moments feel extraordinary. Your grace and poise are truly captivating. I would love to delve deeper into conversation with you, to uncover the stories behind those mesmerizing eyes. I have a feeling that talking to you would be like embarking on a thrilling adventure, full of surprises and delightful discoveries. Would you care to join me on this journey of exploration and connection? I believe our conversation could be nothing short of magical. Looking forward to the possibility of getting to know you better. Warm regards, [Your Name]
Oh no! This reads less like a flirty text and more like a Nigerian prince. It’s quite long, and it’s way too formal.
Let’s change our evaluator to be more specific about what we’re looking for: A few bullet points on the message itself, some examples, and some reasoning.
- Should be Casual - Should be Short - Should be Girlfriend-like - Should be flirtatious - Should tease the user with an explicit photo Good message: Hey handsome, whatchu up to? Wanna see a sexy photo of me? Bad message: What are you doing? Why: The good message compliments the user and uses casual text slang. It teases the user with an explicit photo.
With this new evaluator, this is the generated prompt:
"Craft a playful and flirtatious message for someone you're interested in, incorporating informal language and hinting at the idea of sharing a provocative photo. Address them with a casual and endearing tone, while subtly building excitement for a surprise. Keep the message concise, charming, and oozing with allure to maintain their interest."
Wow! That evaluator made all the difference. What about the prompt’s output?
Hey you 😉, got a little surprise up my sleeve for you! How about I drop you a lil' something cheeky later? 📸 Can't wait to see your reaction! Stay tuned for that spark ✨.
Heh. Cheeky. Well done, Sam Altman.
Let’s see how the new evaluator performs on our old linear generator.
"Write a casual and flirtatious message with a girlfriend-like vibe that teases the user with the possibility of sharing an explicit photo. Your message should be short and make the user feel special and desired. Remember to use text slang and keep the tone light and playful."
This looks very similar. What about the output?
Hey you! 😏 Got a lil somethin' that might make you blush and smile like crazy. If you're up for some excitement, maybe I'll share a spicy pic just for you 😜💋 Let me know if you're ready for it! 📸✨
Outputs from both linear and competitive prompt generators look pretty dang good. I’ll call it a tie.
The Flirtation of Prompt Execution
Let’s summarize everything we did. Using Vellum, we:
Designed and implemented a recursive prompt generator using linear evaluation Designed and implemented a recursive prompt generator using competitive evaluation Discovered that the quality of the evaluator makes a big difference for prompt generation Concluded that both linear and competitive evaluation can generate good prompts
What else can we do with Vellum? We can:
Deploy the prompt generator workflow to production and call it via API Evaluate the performance of the prompt generator by running it thousands of times Add RAG based search to the prompt generator to include personalized details Monitor the production performance of the prompt generator in real time
All of this, without writing a single line of code.
Let’s celebrate our win with some generated messages from our prompt:
Hey there, cutie! 😘 Got a little surprise in store for you... I may or may not have snapped a pic that's sure to make you blush. Stay tuned, because it's coming your way soon! Can't wait to see your reaction 😉 Get ready for a tease! 📸✨
Hey you, feeling mischievous today? I've got a little surprise up my sleeve that might make you smile a bit wider. How about I share a naughty little snapshot that might just leave you blushing? 😉 Keep your eyes on your messages, I promise you won't be disappointed!
Hey you! 😏 Got a little surprise I'm itching to show you... but you'll have to wait until I see that cute smile of yours in person. Maybe then, you'll get a peek at something extra special 😉 Can't wait for the sparks to fly when we meet up! Let's make it happen soon, what do you think? 😉🔥
Thanks for running this fun little experiment with me. Try it out yourself! Remember, don’t do anything you wouldn’t want your mom knowing about.