
Introducing Vellum for Agents
Today we're introducing Vellum. All you do is chat and let Vellum build reliable Agents for you.

Today we're introducing Vellum. All you do is chat and let Vellum build reliable Agents for you.

A first-class way to manage your work across Development, Staging, and Production.
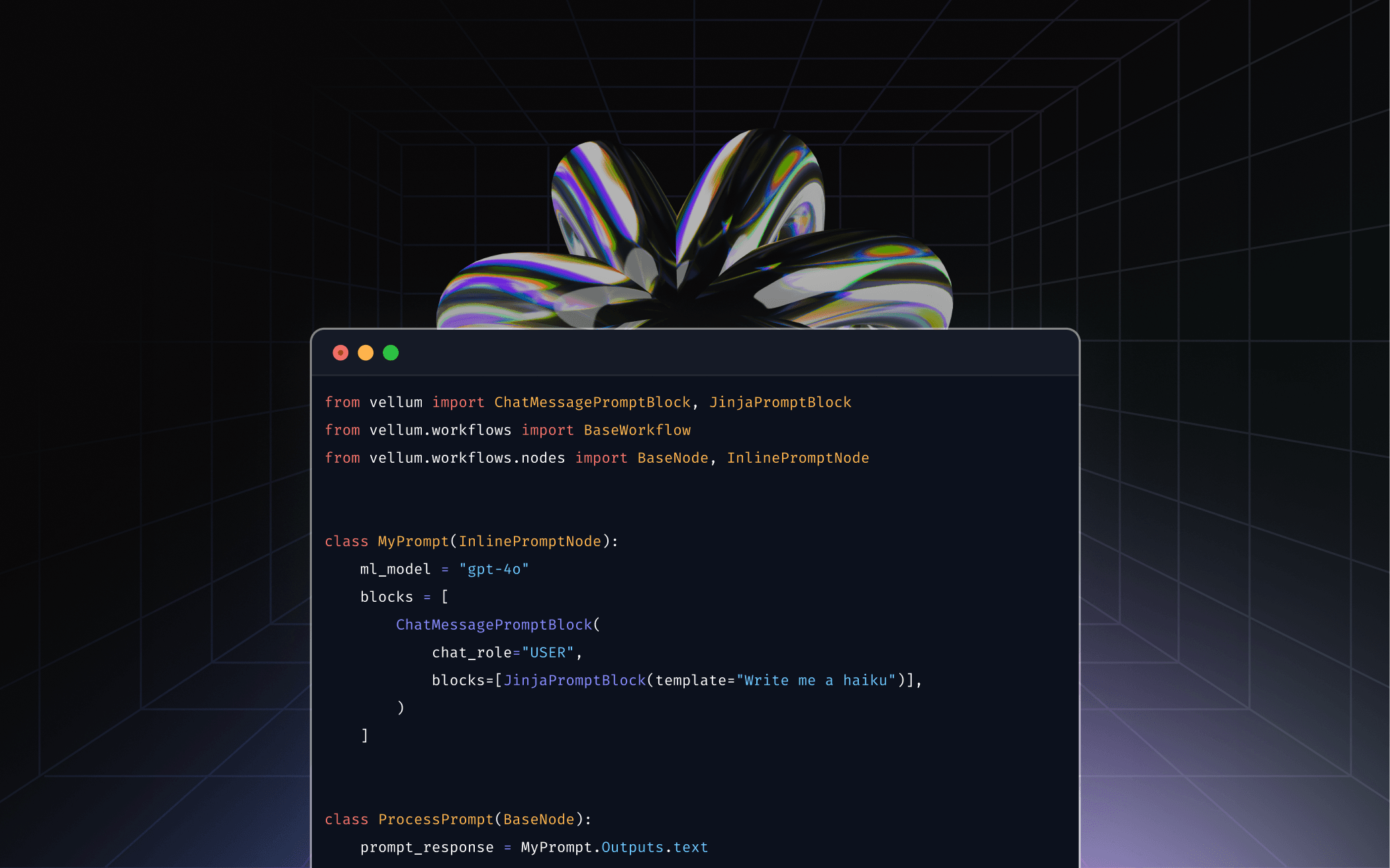
Full control in code and real-time visibility in UI, built for teams shipping reliable AI.

AI Development needs a standard & we’re building it at Vellum

Helping a leading financial institution speed up legal reviews, without compromising quality.

We’re simplifying the complex world of AI development for teams of all sizes.
Learn how to use guardrails, online/offline evaluation metrics for various LLM use-cases.

Learn how and when to JSON mode, structured outputs and function calling for your AI application.

Vellum now offers VPC installations for secure AI development in your cloud, keeping data private and compliant.
Learn the key strategies and tools for building production-ready AI systems.

Learn how Drata used Vellum to quickly validate AI ideas, and speed up AI development.
Tips to most effectively use memory for your LLM chatbot.

Learn how successful companies develop reliable AI products by following a proven approach.

How Miri built a powerful chat experience using Vellum's platform
Collaborating with colleagues to test prompts yields good results but it's challenging.

Rag vs Fine-Tuning vs Prompt Engineering: Learn how to pick which one is the best option for your use-case.
We did an analysis comparing the latency of OpenAI, Anthropic and Google. Here are the results!

Learn how Left Field Labs used Vellum for LLM prompt versioning, evaluation and monitoring once in production.
Why fine tuning is now relevant with open source models
We've raised $5m to double down on our mission to help companies build production use cases of LLMs
If you’re versioning in Jupyter notebooks or Google Docs, running custom scripts for testing, you need to read this
Tips on how to monitor your in-production LLM traffic
Tips to experiment with your LLM related prompts
Details about how to best leverage the Vellum <> LlamaIndex integration

Compare model quality across OpenAI's GPT-4, Anthropic's Claude and now Google's PaLM LLM in our platform
Despite high potential, LLMs are not a one-size-fits all solution. Choosing the right use case for LLMs is important
Fine-tuning can provide significant benefits in cost, quality & latency when compared to prompting
We’re excited to publicly announce the start of our new adventure: Vellum



