At Vellum we provide the platform and share best practices with the goal of helping companies build production use cases of large language models. When building applications, we’ve seen people get stuck in choosing the right model for their use case (given the large number of options across OpenAI, Anthropic, Cohere, Google and open source models).
The best model for the use case is usually one that sits at the efficient frontier of your quality, cost & latency criteria. A common question people ask is: “Can I take a 10% performance decrease for 50% lower latency & 80% lower cost?” Note, there are other criteria like privacy, reliability etc. too but for this article we will simplify a little.
We’ve written about how to measure LLM quality and our Test Suites product helps with exactly that. Given that latency often comes up as a reason to choose a certain model, we decided to do an analysis across model providers and share our findings.
Why is latency important and does it really vary across models?
Latency is important for the UX of an LLM powered application because it directly impacts the speed and responsiveness of the application. A lower latency means faster response times, leading to a smoother, more efficient user interaction. In contrast, high latency can result in delays, disrupting the flow of conversation and potentially frustrating users.

Here’s a quick side-by-side example in Vellum which shows how similar prompts have vastly different results when run across OpenAI’s GPT-4, Anthropic’s Claude-2 and Google’s Chat Bison

How do LLMs create responses? Why does latency vary across providers?
LLMs predict one token at a time by taking into account all the previous tokens in the text. They use this context to generate the most probable next token, and this process is repeated until a complete response is formed.
The context provided in the context window directly impacts latency. The larger the context window, the more tokens the LLM has to process, which can increase the time it takes for the model to generate a response. This adds up to affect time to create the first token and then the full completion based on the size of the response.
Latency can vary across models and model providers due to several factors. Firstly, the size of the model plays a significant role - larger models (in # of parameters) typically require more processing time, leading to higher latency. Secondly, the degree of parallelism in the model's architecture and deployment can affect speed, with more parallelism resulting in faster response times. Lastly, the amount of traffic a provider is handling at any given time can also impact latency, as higher traffic can lead to slower response times.
So we ran a test to compare these models side by side
We are sharing results from a one-time analysis which was conducted in a 2 hour window in early August 2023. The results will change over time as traffic fluctuates and the model providers make changes under the hood.
Metrics measured
Given that prompt length affects latency, we tested latency across short prompts & long prompts. For each prompt size, we measured time to first token and time to last token.
Prompt used

Short prompt: {{text}} variable had 10 tokens
Long prompt: {{text}} variable had 600 tokens
Models evaluated:
GPT-4, GPT-3.5, Claude 2, Chat Bison
Number of completions per model
100
With the experiment details out of the way, time for the main takeaways!
OpenAI had lowest time to first token and highest time to completion
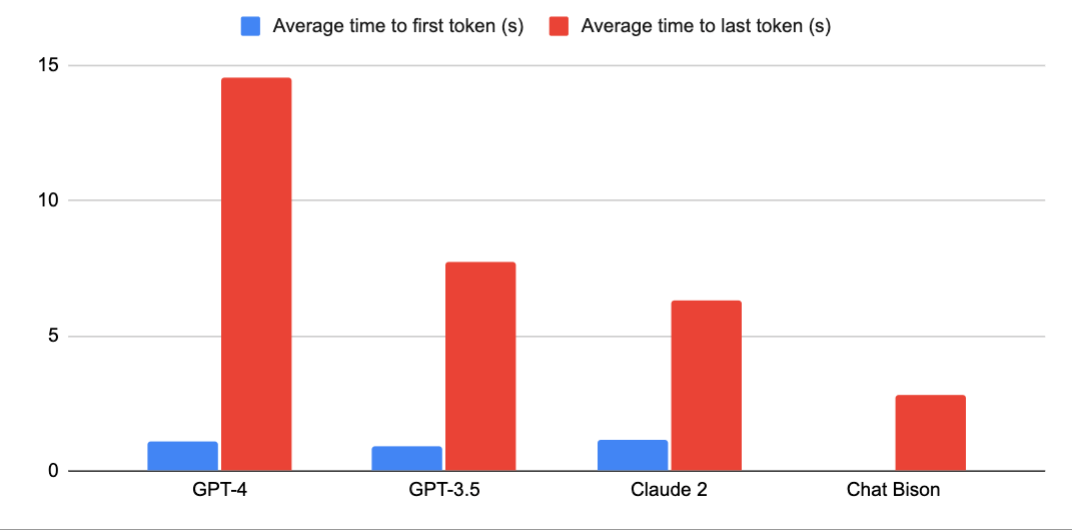
All the models came in at a similar range for time to first token (ranging from 0.9s for GPT-3.5 to 1.1s for Claude 2), however there were significant differences in time to completion:
Chat Bison, at 2.8s for time to completion, was way faster than the other models (note: Chat Bison doesn’t support streaming so only time to last token is shown) Claude 2, Anthropic’s top-of-the-line model had lower last token latency than GPT-3.5 GPT-4 had much higher last token latency than the other models
GPT-4 had the highest variability in latency
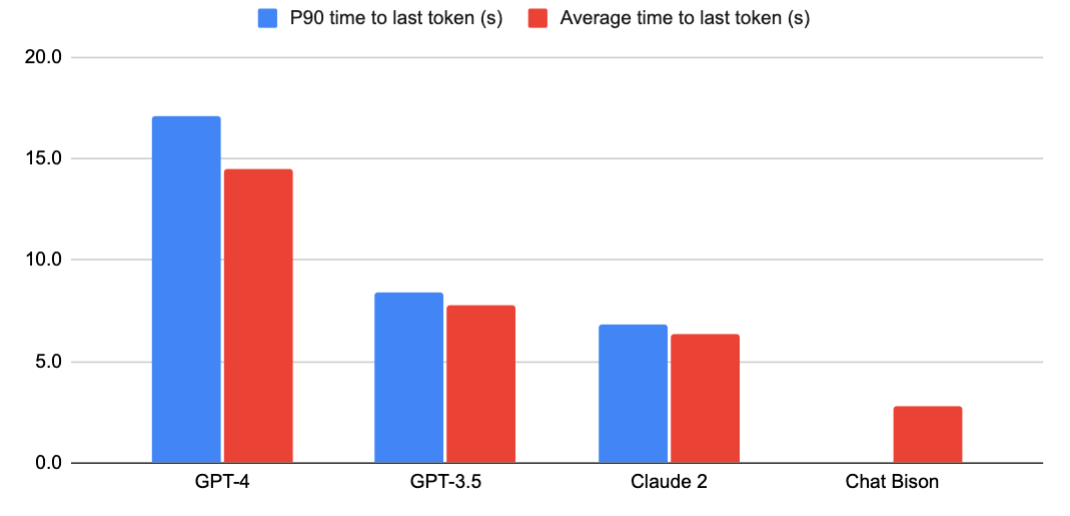
The longest GPT-4 responses took over 20s.
One miscellaneous finding: Long prompts typically have higher latency than short prompts for the same model, but the difference isn't very meaningful. The only noticeable gap was long prompt for Claude 2 took 1.9s for first token v/s short prompt took 1.1s for first token
How to best leverage this knowledge while building your LLM application
Latency is just one criterion used to make your decision on what the right prompt/model combination for your use case is, quality and cost are very important too! Ultimately it comes down to making a comparison between various models, running them across test cases to see which one is the best for a given use case. If you’d like to try these models out side by side in Vellum, sign up for a 14-day free trial of Vellum here . We’re excited to see what you end up building with LLMs!