Official today, we are launching two new production-grade APIs for invoking your prompts in Vellum - Execute Prompt and Execute Prompt Stream !
These APIs introduce a new interface that aligns with our "Execute Workflow" endpoint, and packs a bunch of new features around release pinning, future proofing, and more! Let’s dig in.
Improved, Consistent API
The "Execute Prompt" and " Execute Prompt Stream" are meant to replace our widely used " Generate " and " Generate Stream " endpoints. We recommend migrating to the new "Execute Prompt" APIs at your earliest convenience. We still haven't decided when we'll deprecate the legacy endpoints. While we'll continue to maintain them, we won't be adding new functionality to them.
If you use our (now legacy) endpoints, you may be familiar with this code snippet:
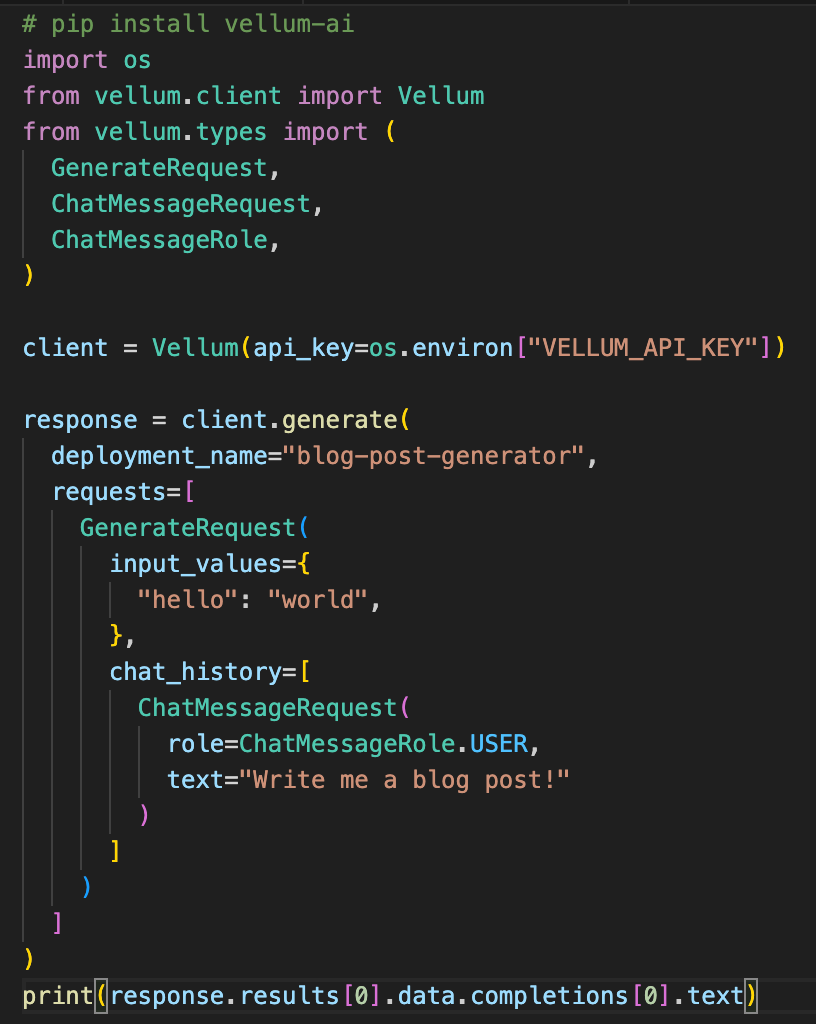
There are several aspects of this interface we wanted to improve:
What does generate do? It's not obvious that this API is the primary one for executing prompts. Less than 0.01% of invocations involved sending multiple requests , which complicated the interface for the other 99.99% of invocations where only a single request was sent. The 'input_values' only accepts STRING inputs, which often led to confusion among users about whether to include 'chat_history in its own arg or string-ified as part of input_values. Check out that response - six data accesses just to see what the model responded with!
Here’s what the same action looks like using the new " Execute Prompt" API:
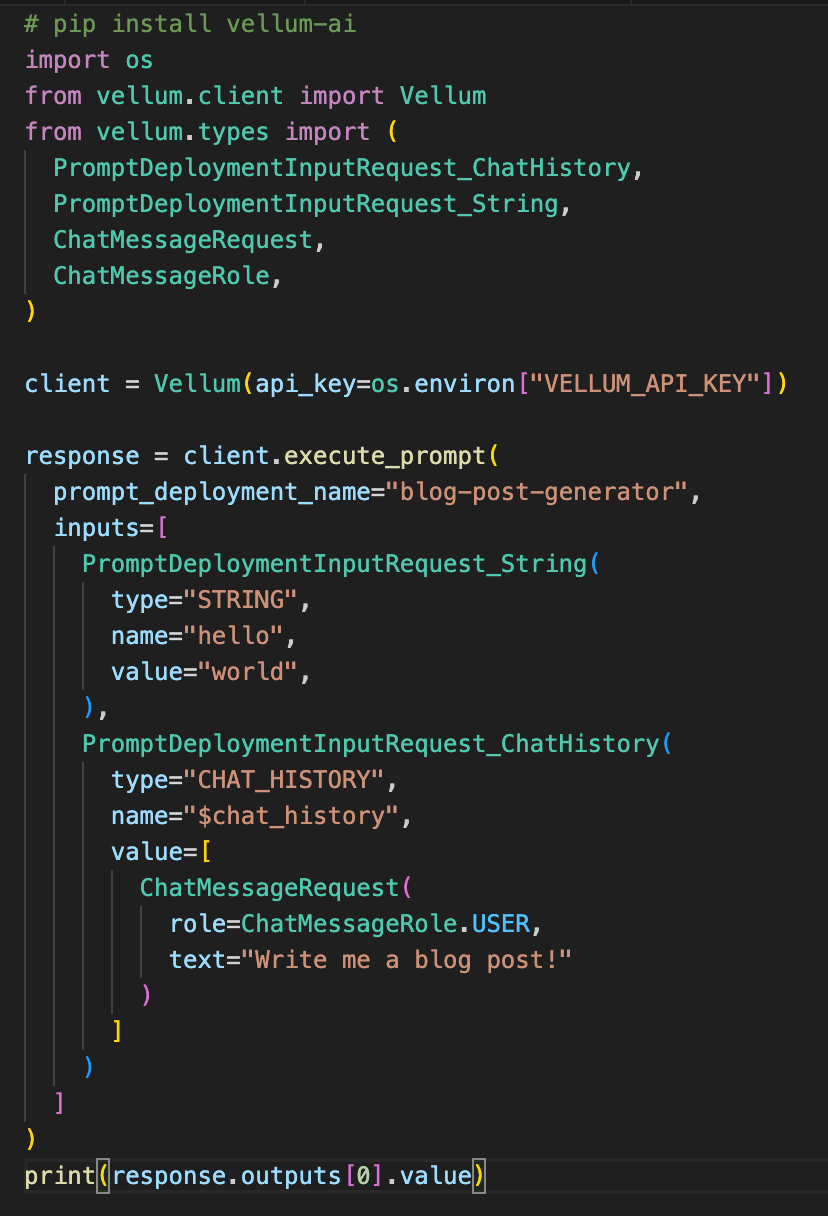
This interface brings the following improvements:
Consistent interface with current and future execute Vellum resources. Non-batch by default. Flexible inputs interface capable of handling all Vellum Variable Types. Simplified response schema for core use cases.
Release Pinning
Every deployed prompt in Vellum, comes with an auto generated release tag that can be used to reference a specific Release of the deployment. In the future, users will be able to add their own custom release tags to identify specific releases of a deployment.
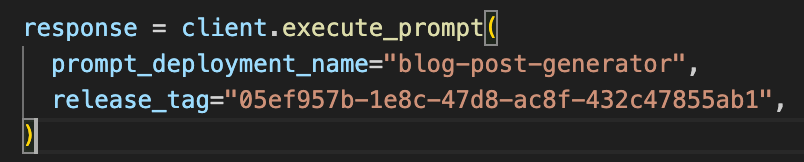
The new "Execute Prompt " APIs support a release_tag argument for accessing an exact release of your prompt. This is useful for keeping a production release of your prompt while letting the staging release float with “LATEST.”. For example:
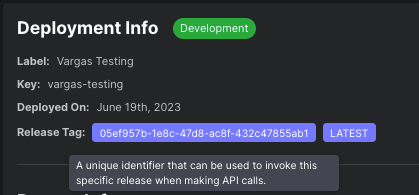
You can find the release tag associated with each prompt deployment release on the " Releases" tab of your prompt deployment:
Future Feature Support By Default
Stop me if you’ve felt this before - OpenAI releases new feature in their API, but despite how fast Vellum tries to ship support for it, you’re still stuck for some time waiting for native support. We all know the feeling, and while we’re constantly making internal improvements to increase our time-to-delivery, these " Execute Prompt " APIs now include new parameters that allow for use of any future feature by default.
At its core, Vellum translates the inputs you provide into the API request that a given model expects. If there’s a parameter that you’d like to override at runtime, you can now use the raw_overrides parameter. Similarly, if there’s some data from the model provider’s raw API response, you can opt into returning it via the expand_raw parameter. These raw response fields are returned in the raw parameter.
Let’s see an example, using OpenAI seeds and fingerprinting, which is not yet supported in Vellum but coming soon:
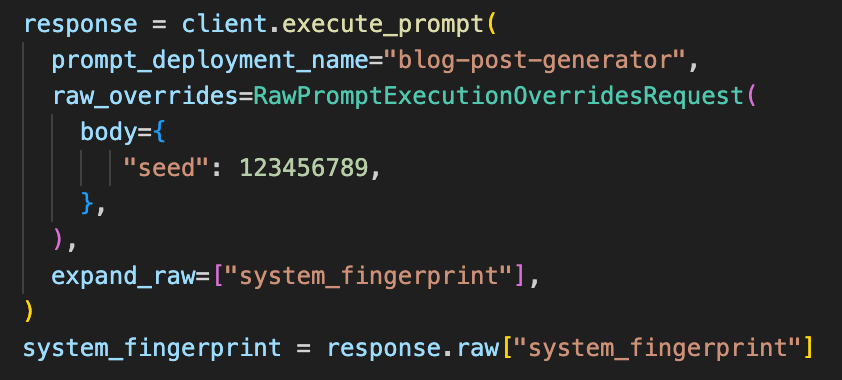
These features are meant for power users that are eager to use the latest features coming from model providers. It gives raw, early access to users without needing to eject from Vellum’s API altogether, thereby losing all benefits of Vellum prompt deployments like versioning, monitoring, and use within workflows.
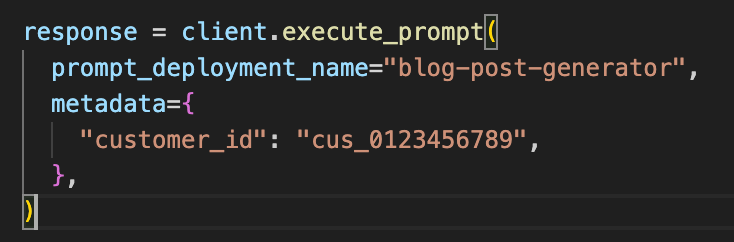
Storing Metadata With Each Execution
For some time now, Vellum has allowed to pass in an external_id with your prompt executions so that you can easily map executions stored in Vellum to your own internal systems. The " Execute Prompt " APIs now also support a new metadata field that allows you to pass in any arbitrary JSON data that’ll be stored with the prompt execution. In the future, we’ll support the ability to filter by these metadata fields in our UIs:
Multi Function Calling Support
Our old prompt execution endpoints returned function calls with type="JSON". This brought with it a few downsides:
Users needed to parse the json-ified string twice in order to access the function calling arguments. Users were responsible for adapting to changes made in the underlying model provider's API (OpenAI now uses tool_calls!) Return type is overloaded with the soon to be supported JSON mode.
To solve this, each function call is now output to the user as a FUNCTION_CALL type:
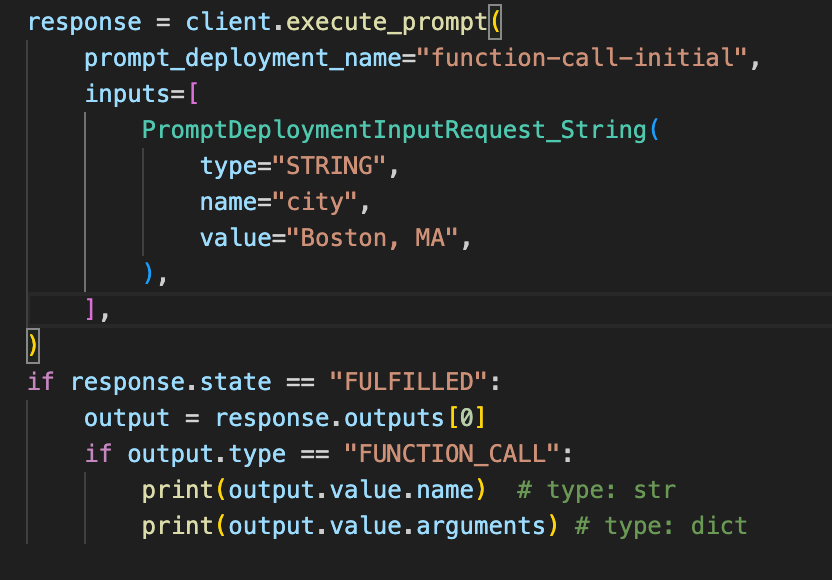
Along with solving each of the aforementioned downsides above, these new endpoints now have first class support for Multi function calling , with each function call outputted as a separate within the top level outputs array.
Give it a shot!
If you’re a Vellum customer, we’re excited to hear what you think! Interested in trying out Vellum? Book a demo with us today.