Over the past two years, model intelligence has advanced rapidly, but by the end of 2024, we’re seeing signs of diminishing returns.
The question on everyone’s mind: Is scaling model intelligence reaching its practical limits?
In a narrow sense—if you’re just looking at increasing model size, compute, or dataset size—it might seem like progress has stalled.
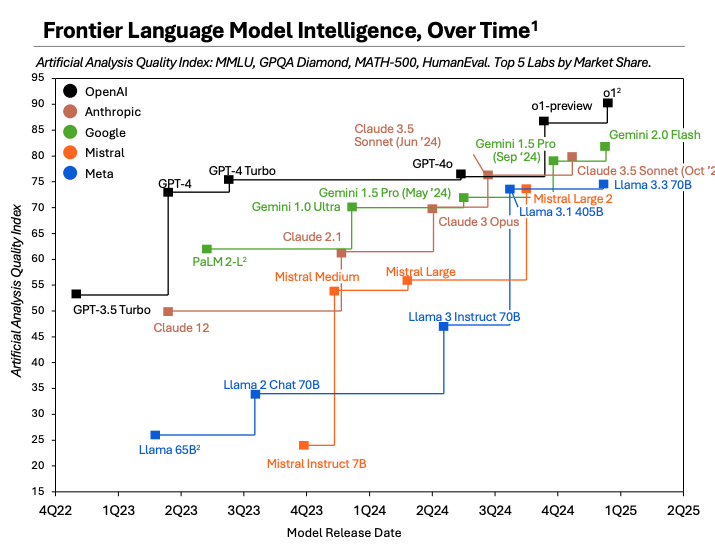
But new methods are opening up exciting possibilities.
It seems the road to AGI hasn’t hit a wall—it’s just under construction.
Or as Ilya Sutskever said in a recent interview: “The 2010s were the age of scaling, now we're back in the age of wonder and discovery once again. Everyone is looking for the next thing. Scaling the right thing matters more now than ever. ”
Today, everyone is discussing neural scaling laws—whether models are reaching their limits and what new methods might unlock fresh horizons. To tackle these questions, we’ve put together this guide, breaking down everything about the neural scaling law, the limits and the next frontier.
Scaling Laws Explained
Neural scaling laws gained prominence in the wake of breakthroughs with transformer-based architectures, such as OpenAI’s GPT models.
These laws explain how increasing compute , model size , and dataset size leads to predictable improvements in AI model performance.
However, the improvement slows down as you keep scaling, hitting a point where adding more resources gives smaller and smaller benefits. This point is called the Compute-Efficient Frontier (CEF) , marking the limit of how far brute-force scaling can take you before it stops being practical.
At a certain point, simply adding more resources becomes less effective.
To push past these limits, we need smarter approaches, like better algorithms, architectural innovations, or new ways to optimize models, to continue improving efficiency and performance.
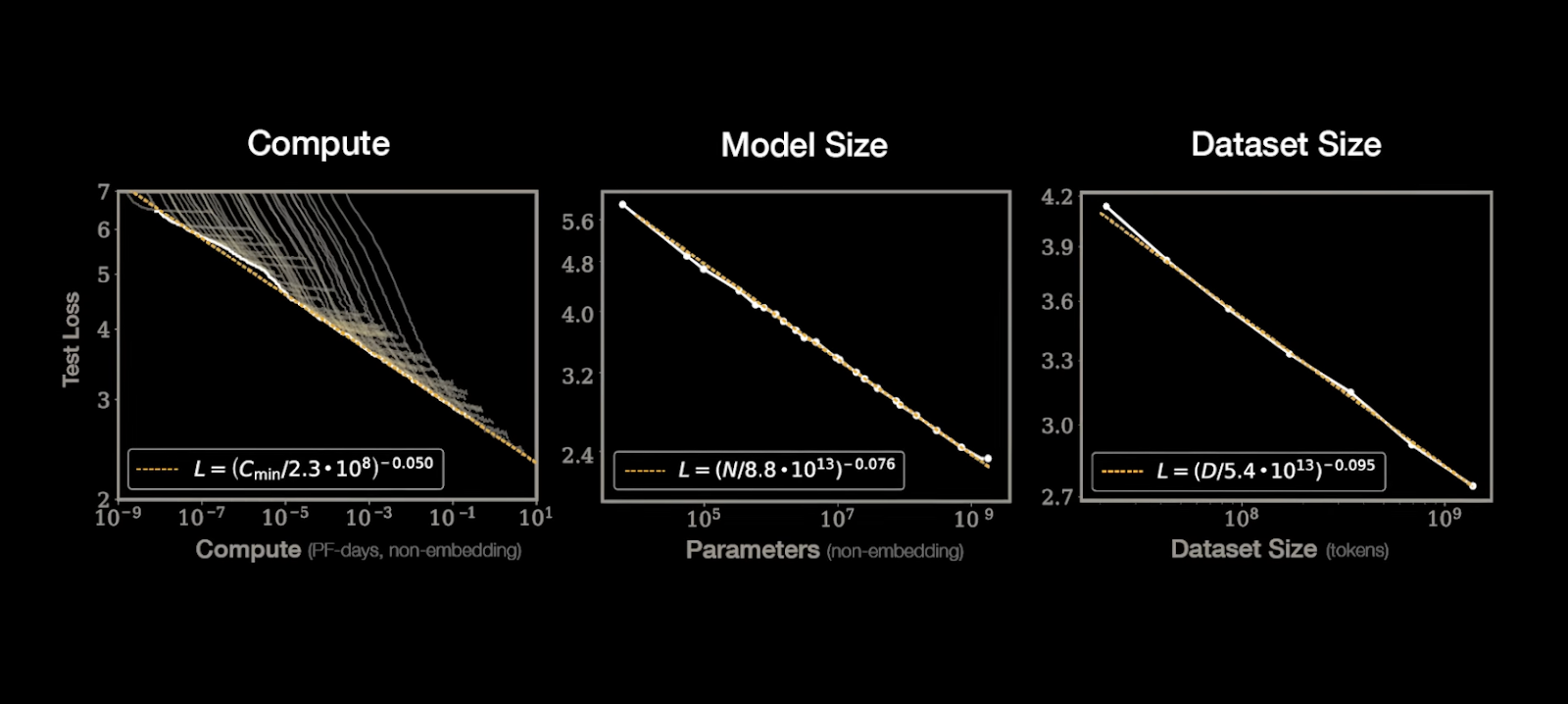
In simpler terms:
Larger models (with more parameters) require significantly more compute to train effectively. Larger datasets enhance model performance but also require greater compute resources and can hit a saturation point where further data provides little benefit and may even lead to overfitting. Scaling compute, model size, and dataset size together drives performance gains, but these gains taper off near the compute-efficient frontier, where significant resource investment yields only marginal improvements.
Compute
Compute is the foundation of neural scaling laws. It's measured in petaflop/s-days , which quantifies the total number of floating-point operations (FLOPs) performed per second, sustained over a full day. As models grow in size and dataset requirements increase, compute demands scale superlinearly (concave upward line).
For example, doubling a model's size requires far more than double the compute to train it effectively. This exponential growth highlights why scaling compute has been both a driver and a bottleneck for modern AI development.
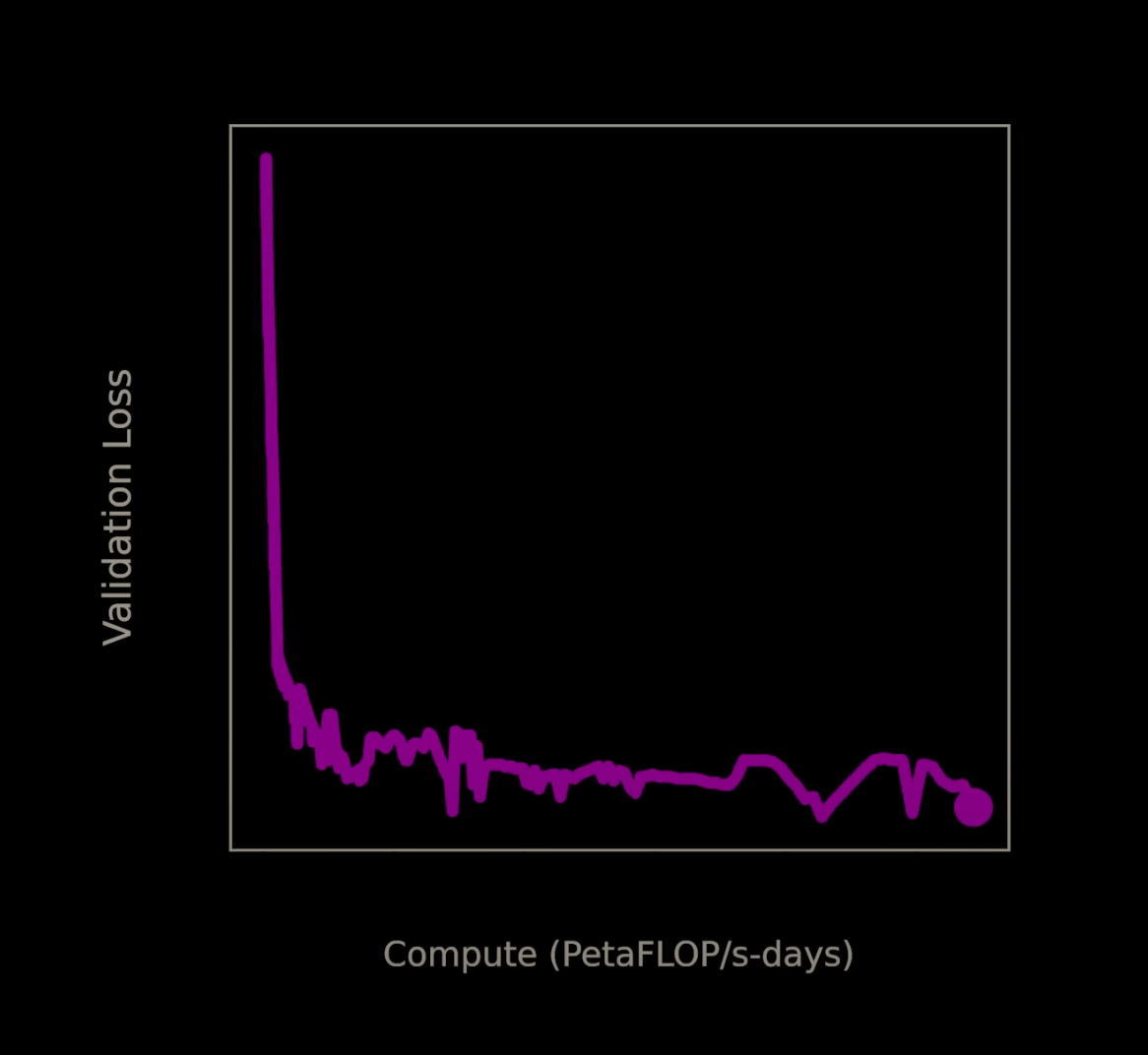
Training modern large language models (LLMs) like GPT-4 can require thousands of petaflop/s-days , reflecting the immense computational effort. This compute is typically provided by clusters of high-performance GPUs , such as NVIDIA’s A100 or H100, which are optimized for parallel processing tasks involved in deep learning.
To put these compute requirements in perspective, let's examine some concrete numbers. A single NVIDIA A100 GPU can deliver approximately 312 teraflops (312 × 10^12 operations per second) for machine learning workloads. Training a model like GPT-3 (175 billion parameters) required approximately 3,640 petaflop/s-days. This means that even with a cluster of 1,024 A100 GPUs, the training process would take several months. These numbers demonstrate why compute has become a critical bottleneck in AI development and why achieving efficiency at scale is crucial.
Model Size
Model size refers to the number of parameters in a model. Parameters are the fundamental building blocks of neural networks. A parameter is a learnable value, such as a weight or bias , that the model adjusts during training to minimize error.
For example, in a simple linear regression model y=wx+by = wx + by=wx+b:
www (weight) determines how strongly the input xxx influences the output. bbb (bias) allows the model to shift the output value.
Early LLMs, like OpenAI’s GPT-2, had 1.5 billion parameters. In contrast, more recent models, such as GPT-4, are estimated to have over a trillion parameters.
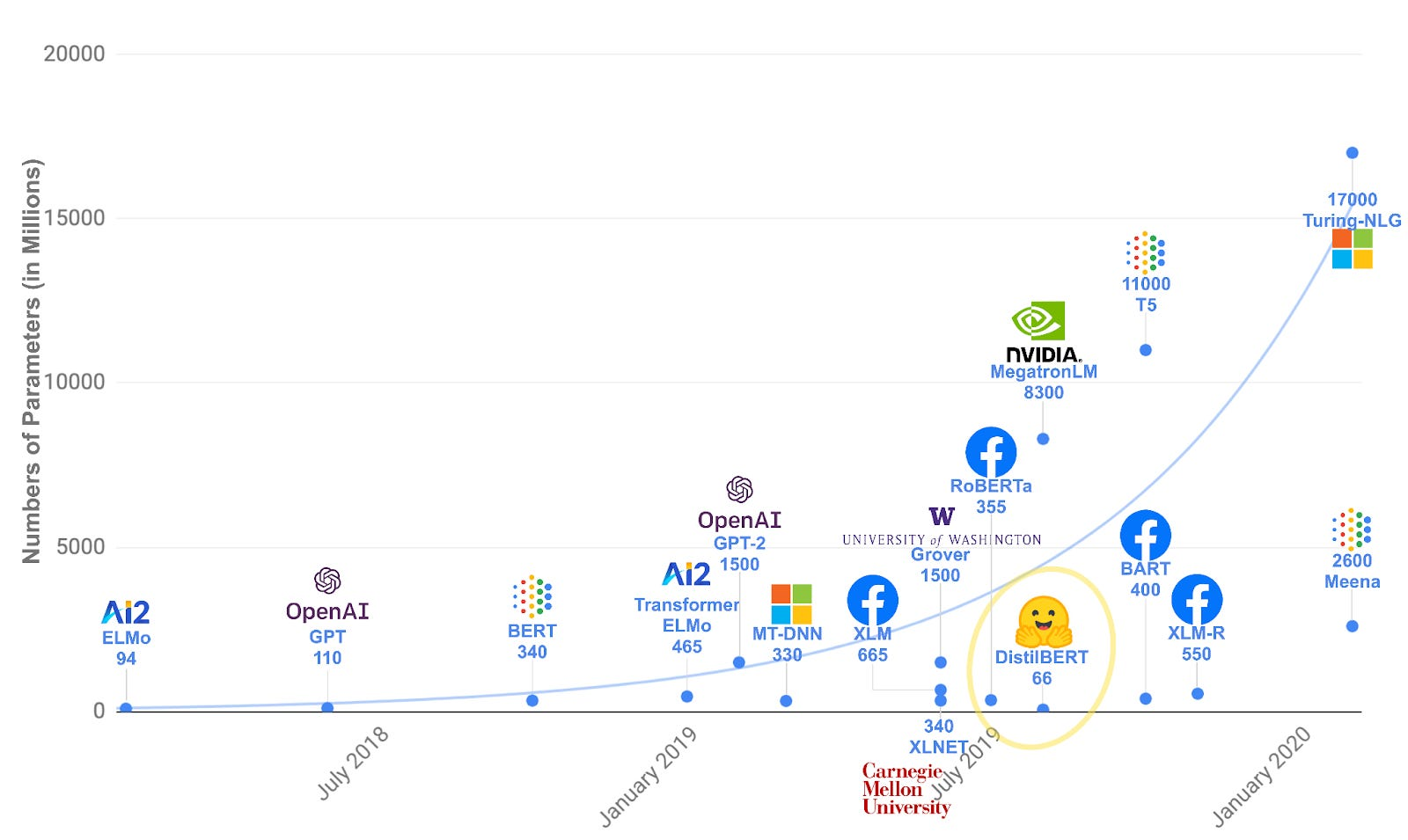
Larger models achieve better performance due to their increased capacity to learn and represent complex patterns. However, neural scaling laws show that error rates decrease predictably with more parameters only up to a point . Beyond this, adding more parameters can yield minimal improvement while significantly increasing compute requirements, creating trade-offs that must be carefully balanced.
The relationship between model size and dataset size is particularly crucial. As models grow larger, they require proportionally more training data to achieve optimal performance. This relationship follows a power law: doubling the model size typically requires a 2.5x increase in dataset size to maintain the same level of performance. This interaction leads us to consider dataset scaling as our next crucial factor.
Dataset Size
Dataset size is measured in tokens , where a token is a fragment of text, such as a word, subword, or character, depending on the tokenizer used. For reference, GPT-3 was trained on 570 GB of text data , amounting to about 300 billion tokens.
The vast majority of high-quality, publicly available text data has already been used for training. This includes datasets from: web pages (Common Crawl, Wikipedia, news articles), books and scientific papers, and code repositories (e.g., GitHub)
To continue, we’d have to rely on synthetic data (generated by AI models themselves), collect proprietary or domain-specific datasets, or develop methods to train models more efficiently with existing data.
Dataset scaling follows a pattern similar to model scaling: increasing the dataset size improves model performance, but only up to a point. As the dataset grows, the model gains new insights from the data, reducing error rates. However, it eventually hits data saturation , where additional data yields diminishing returns. At this stage, the model has already learned most of the meaningful patterns, and further data provides minimal new information or insights.
Compute-Efficient Frontier (CEF)
The compute-efficient frontier (CEF) represents the theoretical limit of resource efficiency achievable with current AI architectures. It defines the most optimal balance of compute, model size, and dataset size required to achieve a given error rate. Neural scaling laws predict that as models approach this frontier, performance improvements slow dramatically.
Models that operate on the CEF are considered "compute-efficient" because they extract maximum performance from the resources available. This is why AI providers often release families of models—like Anthropic’s Claude 3—along the CEF. These families offer trade-offs in size, speed, and capability to meet diverse use cases, optimizing for users with varying resource constraints.
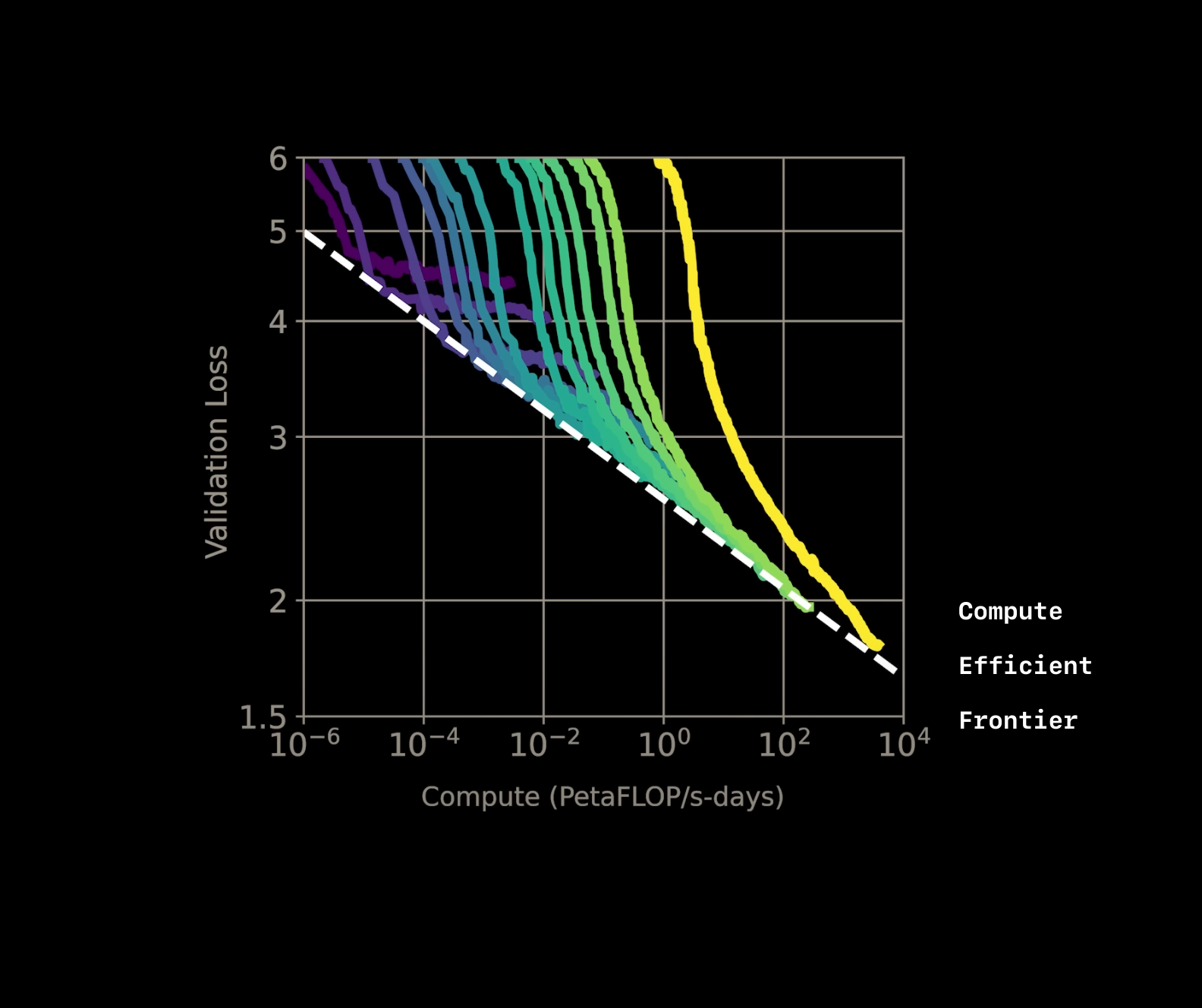
Why Is the CEF a Limiting Factor?
No known architecture has been able to surpass the compute-efficient frontier . As models scale in size or datasets grow larger, the cost of training (in terms of compute, data, and time) increases exponentially. This creates a fundamental challenge: while scaling laws have enabled the rise of large language models (LLMs), they als o reveal natural diminishing returns. The closer a model gets to the CEF, the smaller the performance gains for every additional unit of compute.
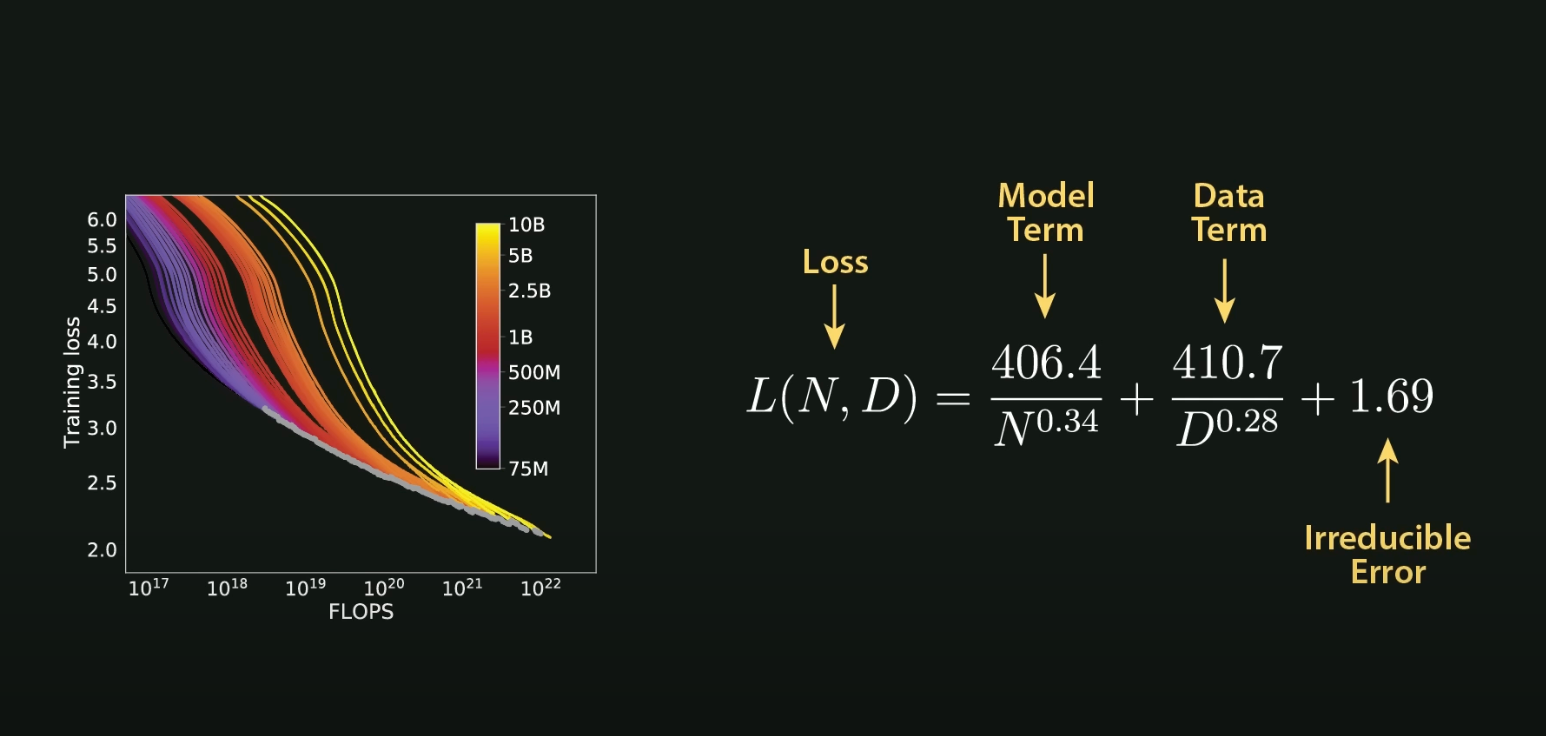
For instance, achieving near-zero error rates with current methods (and factoring in the entropy of natural language ) is likely impossible . Beyond the CEF, resource requirements grow so large that physical or theoretical limits—like energy efficiency or hardware constraints—become insurmountable.
When first discovered, neural scaling laws were celebrated for their ability to reliably predict performance improvements with increased resources. They provided a roadmap for building larger, more capable systems like GPT-3 and GPT-4. However, these same laws now highlight a hard truth: beyond the CEF, brute-force scaling becomes unsustainable .
New ways to scale model intelligence
AI scaling hasn't "hit a wall"; instead, researchers have discovered new methods to enhance performance, albeit with increased costs.
Test-time scaling
AI scaling progress has not “hit a wall”.
OpenAI's o1 model takes a new approach to AI reasoning by scaling computation during inference , letting the model "think" more before responding. This method, called test-time compute scaling, focuses on inference-time optimization rather than just expanding model size, datasets, or training compute.
Using a "chain of thought" process, o1 breaks complex problems into smaller steps, self-correcting along the way to deliver more accurate results. While this boosts reasoning ability, it comes with trade-offs: higher computational costs and slower response times.
o1 doesn’t break past the Compute-Efficient Frontier (CEF) but shifts the focus. By enhancing inference rather than relying solely on training-time scaling, it opens a new path for advancing AI performance without hitting the limits of traditional scaling.
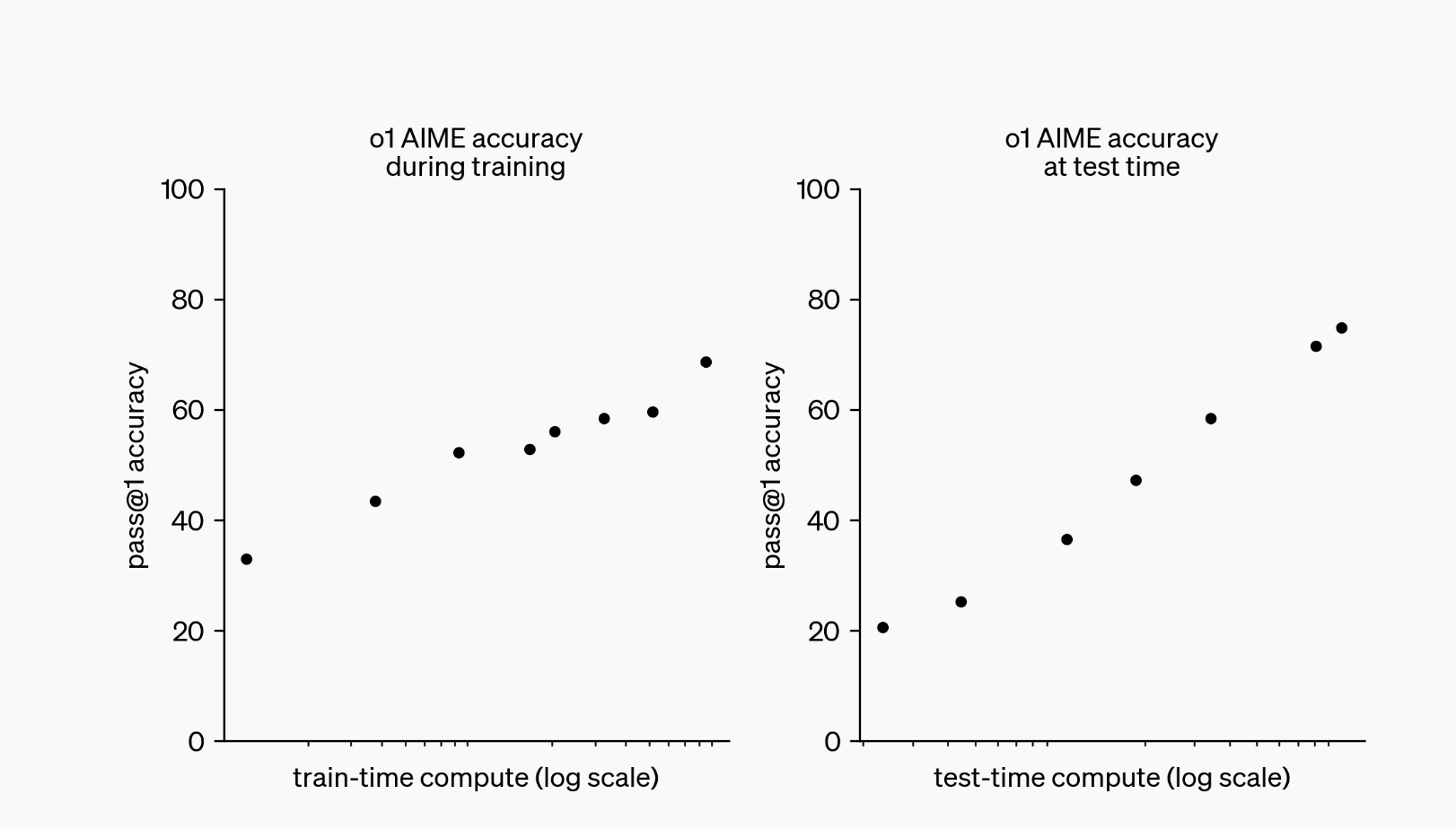
“It turned out that having a bot think for just 20 seconds in a hand of poker got the same boosting performance as scaling up the model by 100,000x and training it for 100,000 times longer,” said Noam Brown, a researcher at OpenAI who worked on o1, at TED AI conference in San Francisco last month.
The latest OpenAI's o3 model has achieved remarkable results on several benchmarks. It scored 87.5% on the ARC-AGI benchmark, a test of general ability, surpassing the typical human score of 85%. Additionally, on the challenging Frontier Math benchmark, o3 achieved a 25% success rate, a significant improvement over the previous state-of-the-art score of 2%.
At the same time, researchers at other top AI labs are also experimenting with this technique.
In fact, Google recently released the Gemini 2.0 Thinking Flash model that works in the same way as o1.
Mixture-of-Experts (MoE)
Instead of activating all model parameters for every input, sparse models dynamically engage only the parts of the network most relevant to the task.
For example, in Mixture-of-Experts architectures, different "experts" within the model specialize in distinct tasks, and only a subset of these experts is activated during any single inference. This approach dramatically reduces compute requirements while maintaining—or even improving—performance. Sparse models have proven effective for scaling up model capacity without proportionally increasing the computational overhead.
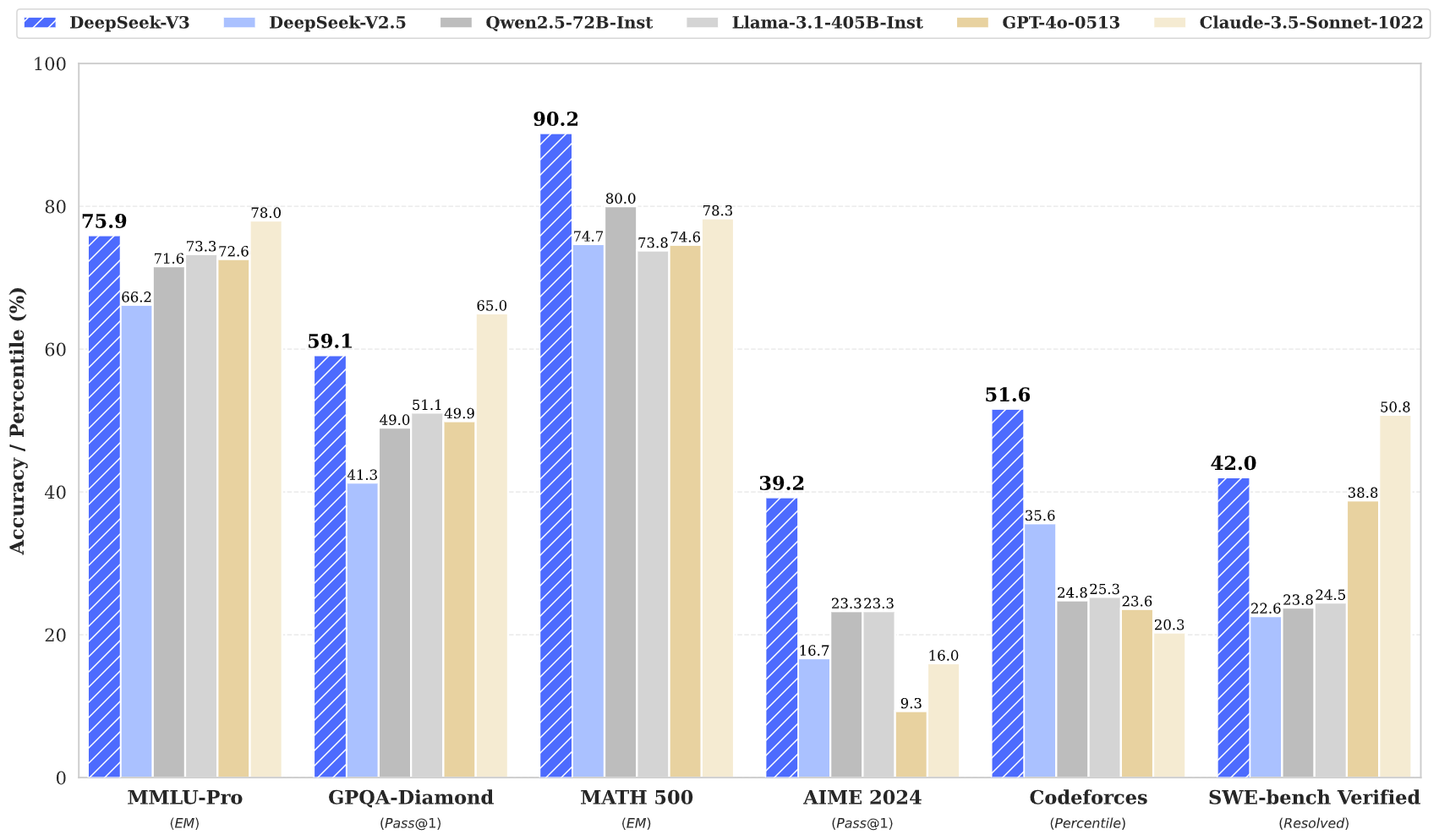
One example of a model that works with this approach is DeepSeek-V3 . Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. This is significantly less than the estimated 54 million GPU hours used for training GPT-4.
AI will scale faster, but so will costs
"Progress from o1 to o3 was only three months, which shows how fast progress will be in the new paradigm of RL on chain of thought to scale inference compute. Way faster than pretraining paradigm of new model every 1-2 years," writes OpenAI researcher Jason Wei in a tweet .
The caveat: One reason why O3 is so much better is that it costs more money to run at inference time. Models like O3 have made AI running costs harder to predict. Previously, you could estimate costs based on output size and token limits, but that's no longer as straightforward.
Because models like O3 introduce dynamic computation during inference. Instead of fixed costs tied to output size, they adjust compute resources based on task complexity, making costs vary unpredictably.
Model Scaling is evolving beyond brute force
Neural scaling laws show that scaling compute, model size, and datasets drives predictable improvements in AI performance. But these gains slow down as you approach the Compute-Efficient Frontier (CEF), where throwing more resources at the problem delivers smaller and smaller returns. To keep advancing, we need smarter techniques beyond traditional scaling.
Key Points:
Compute : Compute demand grows exponentially with model and dataset size, making it a bottleneck in scaling efforts. Model Size : Larger models can learn more complex patterns, but after a point, the added parameters give diminishing returns and spike compute costs. Dataset Size : Bigger datasets improve performance only up to a saturation point, where more data offers minimal new insights and can lead to overfitting. CEF : The CEF marks the limit of how efficiently resources can be used to improve performance, pushing us to look for better optimization methods.
To move beyond the CEF, researchers are exploring ideas like test-time compute scaling and Mixture-of-Experts (MoE) architectures. These strategies aim to unlock more performance without simply scaling up everything.
Take OpenAI’s o1 model : it uses test-time compute scaling, letting the model "think" during inference by breaking complex problems into smaller steps. This boosts reasoning abilities but increases inference costs and slows response times.
Similarly, MoE architectures activate only the parts of a network relevant to each task, cutting compute needs while keeping performance high. Models like DeepSeek-V3 have shown this works, delivering strong results with far less training compute than traditional approaches.
Scaling is evolving.
The challenge now is to innovate beyond brute force.