What is Logit Bias
The logit bias parameter lets you control whether the model is more or less likely to generate a specific word.
How does it work behind the scenes
The model is always deciding which word (or tokens) to pick next. All these tokens have their own IDs, and using logit bias we can forbid the model to use some of these IDs.
But how can we actually find these IDs?
The simplest way is to use OpenAI’s tokenizer tool . Just type in your words, toggle the “Text-Token ID” option at the bottom, and you’ll get the IDs for your words. In some cases you’ll get more tokens for one word.
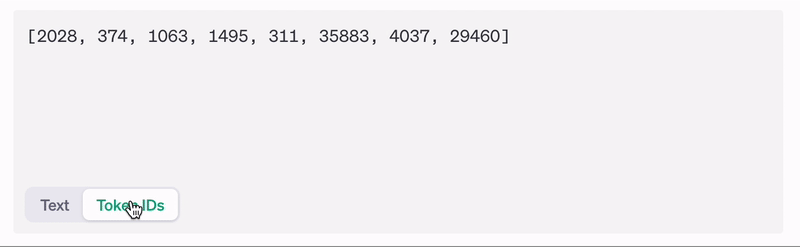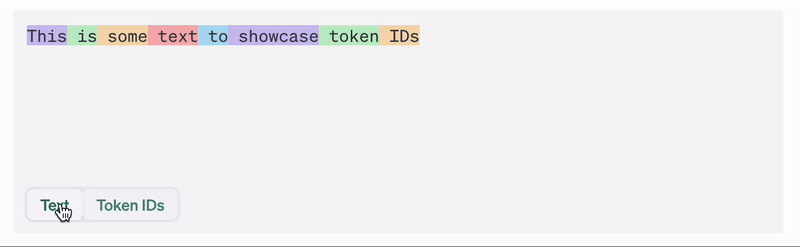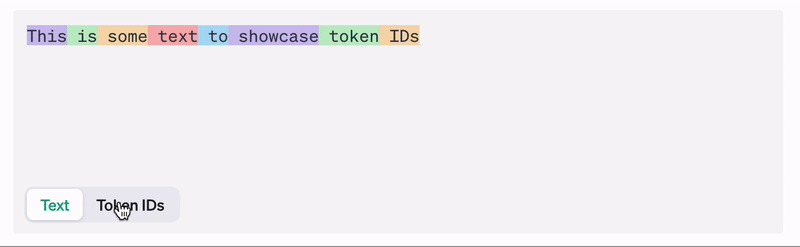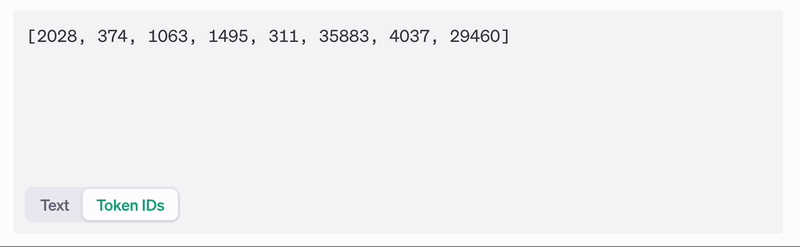
It’s important to note here that different models may produce different tokens for the same input, so you should always check with the model provider to learn about their tokenization process.
There are couple of important things to note here:
You can use OpenAI’s tokenizer tool to find out the tokens for GPT-3.5 and GPT-4 models, but there is still no data for GPT-4o and GPT-4o mini. One word can have two tokens. Characters before a word (e.g. a space or underscore) can produce different tokens for the same word. Capitalization and no-capitalization versions of same word might result in different tokens.
How to set this parameter correctly
In the API, this parameter accepts a JSON object that maps token IDs to bias value. This bias value can vary between -100 to 100. The parameter takes tokens, not text, so you’d use the tokenizer we mentioned above to take the token ids for the words that you’d want to “bias”.
How to experiment with Logit Bias
The closer the value is to -100, the more likely that token will be blocked from being generated. The closer it is to 100, the more the model is encouraged to use that token.
To test this parameter, try adjusting the values gradually and analyze the impact. Using small values like 1 or -1 won’t make much difference, but values like 5 or -5 can have a much stronger effect.
When to use Logit Bias
Use logit bias when know specifically which words you want to ban or encourage repetitive use.
Example 1: Ban offensive words
One example where you’d want to ban some words (tokens) from appearing in the results is for moderation purposes.
Suppose you’re building a guardrail that will capture offensive content in your chatbot. Now, you may want to ban words like “stupid”. The word “stupid” tokenizes to two IDs [267, 16263] , and the same word with a space before “ stupid” tokenizes to another ID [18754] . To ban them from appearing in the results we can add the logit bias like so:
Example 2: Encourage neutral answers in a chatbot If you’re using a customer support chatbot, you’ll likely want it to maintain a calm, neutral tone. To help with that, you can encourage the model to use more neutral words like “understand,” “assist,” and “resolve”. To make the model output “understand,” you need to map it to two token IDs and add a bias of 5: