What is Top P?
Top P , also known as nucleus sampling , is a setting supported by some LLMs; it determines which tokens should be considered when generating a response.
Top P is sometimes stylized as top_p in literature.
How does Top P work?
Because LLMs, or Large Language Models, are trained on massive corpuses of text, they have huge dictionaries. However, some words are significantly more likely to occur in text (e.g. the , you , jump ) than others (e.g. matriculation , dearth , socratic ).
These words are cataloged as tokens, the fundamental unit of LLMs. Tokenizing large words includes splitting them into smaller strings (e.g. matriculation → matri , cula , and tion ).
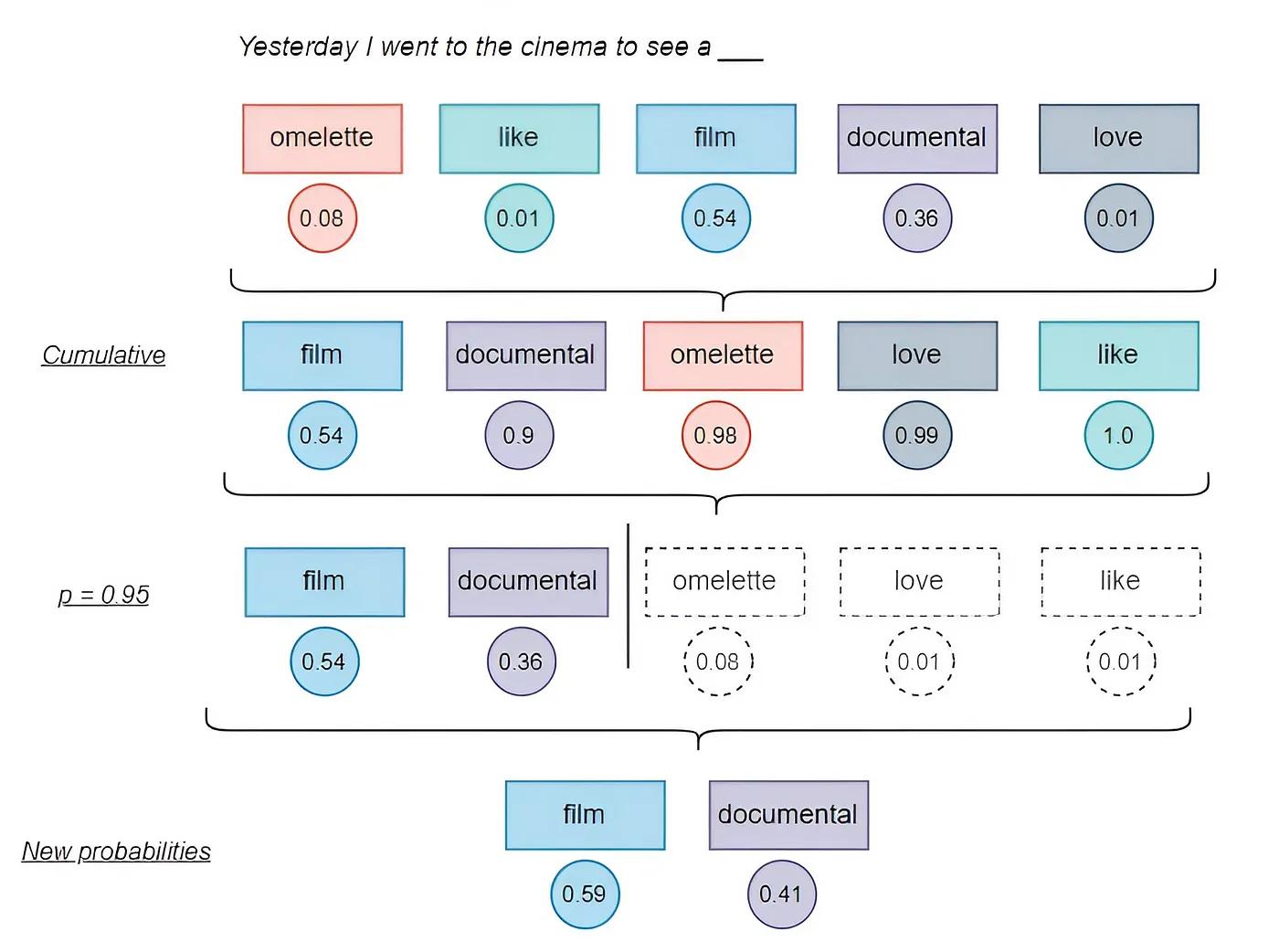
Top P defines the probabilistic sum of tokens that should be considered for each subsequent token. Top P’s values span from 0.0 to 1.0 . Importantly, Top P defines a probabilistic sum, not a percentage. For example, a Top P of 0.5 would include the most popular tokens whose relative likelihoods sum to 50%.
For a more concrete scenario, imagine a response that has thus far generated the string: I took the dog for a . With a Top P of 0.3 , the LLM would only consider tokens like walk (0.2) and check-up (0.1) because their net sum is 0.3 . There’s a long-tail of other considerations, such as trip (0.05) , bath (0.04) , or wolf (0.02) , but the Top P value crops them from consideration.
An alternative to Top P is Top K. While Top P defines a probabilistic sum of a subset of tokens, Top K instead defines the size of the subset. For the aforementioned example, a Top K of 3 would include walk , check-up , and trip .
How do you set the Top P parameter?
OpenAI
To use Top P with the Chat Completions API , you can set the optional top_p parameter. top_p accepts a number value (or null , which default to 1 ). The value should be between 0.0 and 1.0 . For instance, 0.2 would define a 20% probabilistic mass.
Anthropic
You can set stop sequences on Anthropic’s Messages API with the optional top_p parameter. top_p strictly accepts a number value. The value should be between 0.0 and 1.0 .
Gemini
You can set Top P on Gemini’s API with the optional topP parameter. topP strictly accepts a number value. The value should be between 0.0 and 1.0 .
How to experiment with Top P
By increasing or decreasing Top P, you can explore how repetitive or complex responses can get, particularly in their vocabulary and phrasing. With a very low Top P, such as 0.05 , you’ll get very constrained responses, typically at a low reading level. With a very high Top P, you’ll output a more complex vocabulary.
Conversely, you can also experiment with Top K, which is similar to Top P, but instead defines a quantity of the most popular tokens. However, Top P is a more popular setting because it accounts for fast and slow drop-offs in probabilities; some LLMs like OpenAI support Top P but not Top K.
When to use Top P
Top P can be especially useful in certain scenarios:
Managing Reading Level: If you need to produce content at a specific reading level and don’t want to pollute your prompt, Top P is an easy way to accomplish that. Generating Variations: If you are looking to generate multiple variations of a response—such as a title of a book—alternating the Top P value could help.