What is Max_Tokens
The max_tokens parameter specifies the maximum number of tokens that can be generated in the chat completion.
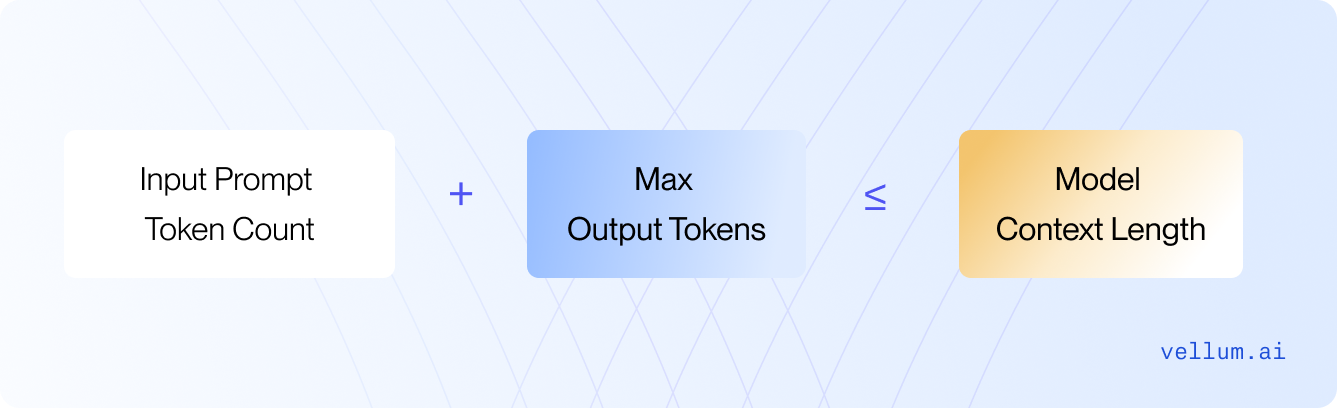
With that being said, the token count of your prompt plus max_tokens cannot exceed the model’s context length.
How does it work
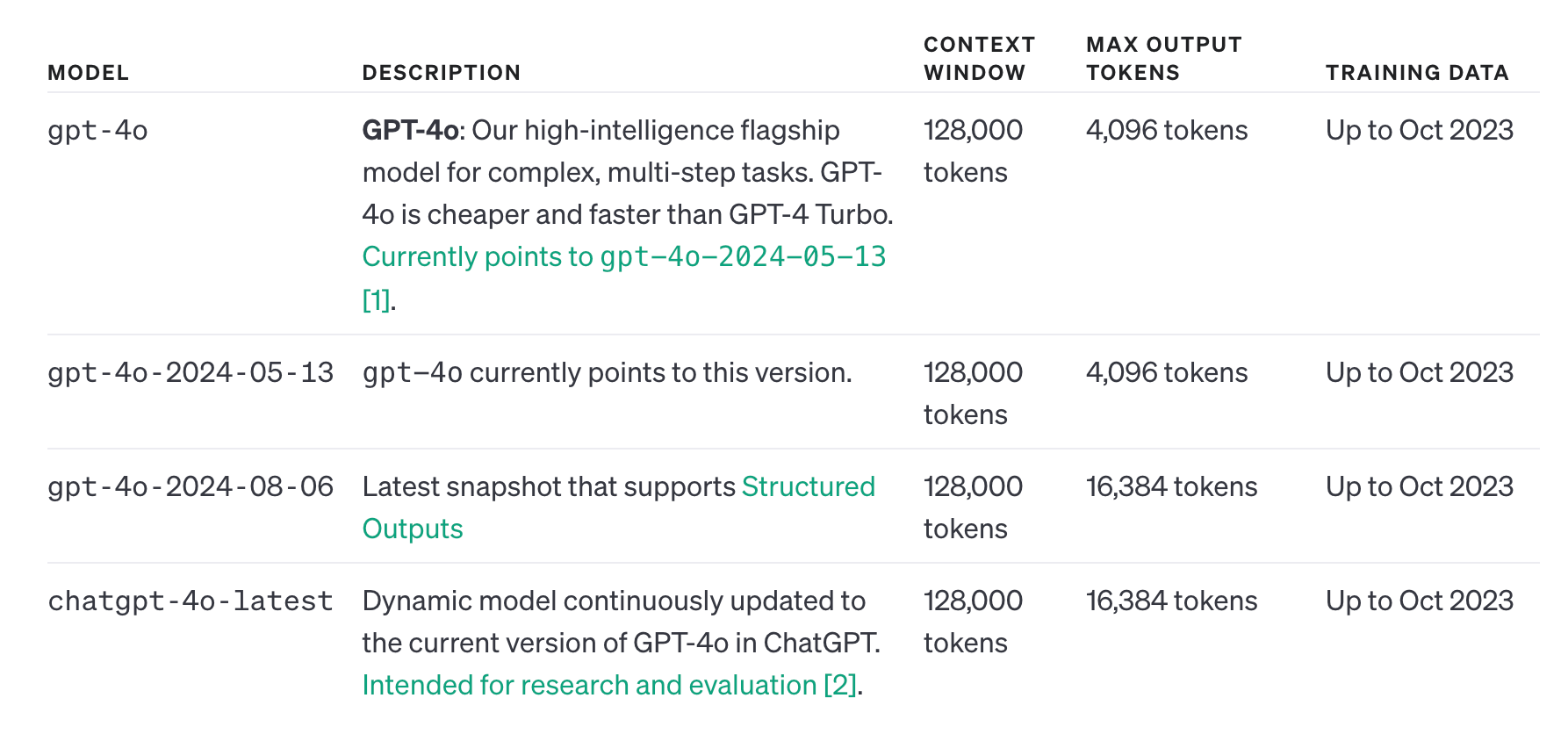
Every model has a context length. GPT-4o has 128,000, Claude 3.5 Sonnet has 200,000 context length. This number cannot be exceeded.
Each of these models have output size between 4,096 to 16,384 tokens — which means that the output can’t exceed this range.
However, you can use the max_tokens parameter to specify exactly how many tokens the model should reserve from the default number of output tokens.
How to set this parameter correctly
To set this parameter simply add the token count that you’d like to see in the model’s response.
How to experiment with this parameter
For chat completions you can skip setting this parameter, and the model will automatically use what’s left from the context length.
However, there are times when you’ll want to limit the length of the output. In those cases, it’s important to have a good way to measure how long the input prompt will be, so you can prevent the output from getting cut off. There are two scenarios for this:
Your prompt is static and you can manually count the tokens needed for the input, and you can easily calculate how much is left for the response; Your prompt is dynamic, and you count the tokens on the fly with libraries like Tiktoken. Read how to do it here .
When to use Max_Tokens?
You can use the max_tokens parameter in cases where you’d want to control the length of the output. A
For chat completions
You can set a lower token count, because you’d want your chatbot to answer in a shorter, conversational manner.
As a safeguard
You can set a lower token count in cases where you want to prevent the model from continuing its output endlessly, especially if you’re working with high temperature settings that encourage creativity but can lead to verbose responses.
Optimize processing time
You can also optimize how fast the model responds to a real-time feature in the app by limiting the size of the output.