What is the LogProbs parameter
Log_prob shows how likely each word (or token) is to appear in a sentence based on the words that came before it.
How does it work behind the scenes
LLMs are like smart text predictors. For every word or phrase they generate, they consider several possible next words and decide how likely each one is.
For example, if the model is trying to complete the sentence: “ The best movie of all time is… ” it might consider options like “The Godfather” or “Citizen Kane.” However, a choice like “Cats” would likely get a very low probability, close to 0%—not to judge, but the visual effects in that one were pretty rough!
When working with model outputs, particularly in machine learning and natural language processing, we often deal with probabilities , which indicate how likely an event (like predicting a word or a label) is to happen.
However, instead of using the actual probability percentages directly (like 10%), we use the logarithm of these probabilities. This is called the “log probability” or “ logprob .”
For example, a logprob of “-1” corresponds to a probability of about 10% (in a logarithmic scale), but it’s easier to work with in calculations. The more negative the logprob, the lower the probability. For instance, a logprob of “-3” indicates a much lower probability than “-1”.
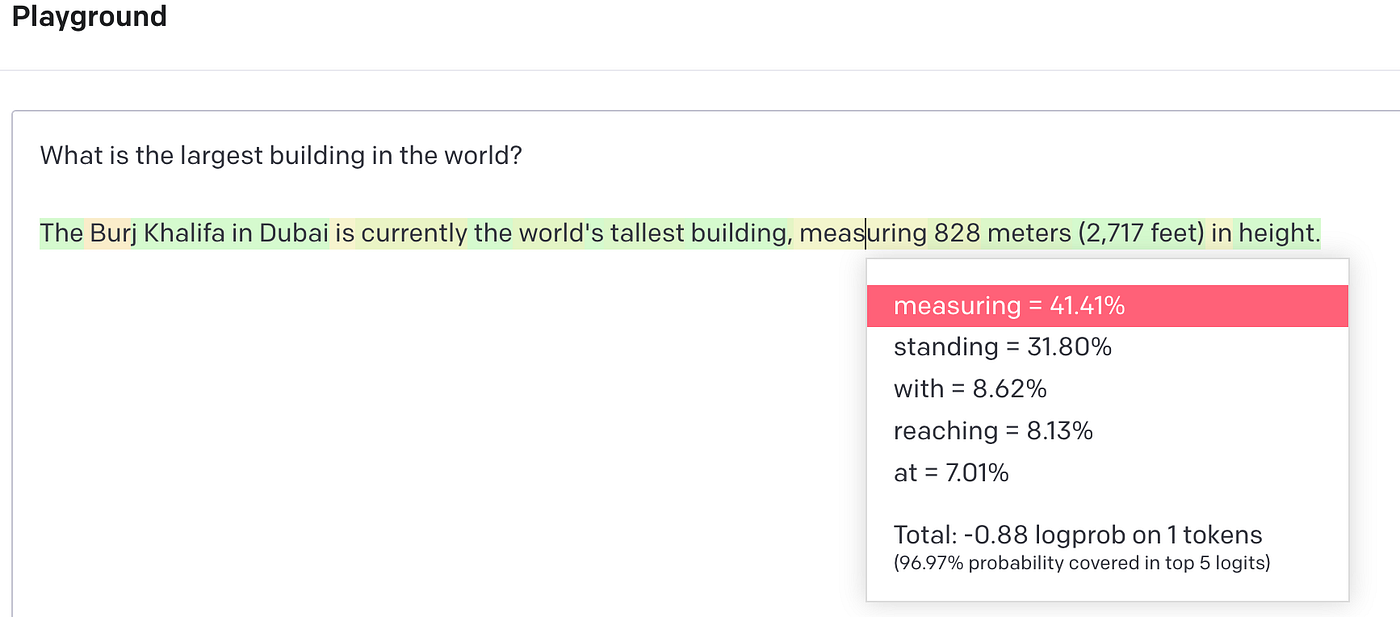
How to set this parameter correctly
When logprobs is enabled, the API returns the log probabilities of each output token, along with a limited number of the most likely tokens at each token position and their log probabilities. There are two request parameters in the API:
logprobs If set to true , it will the log probabilities of each output token returned in the content of message. t_logprobs An integer between 0 and 5 specifying the number of most likely tokens to return at each token position, each with an associated log probability.
Some important points about using logprobs:
Higher log probabilities means that token has higher chances to show up within that context. You can analyze this likelihood to understand what’s the model’s confidence of the output it generated The value of a log prob can be any negative value or 0.0. 0.0 means 100% probability
How to experiment with this parameter
We can use this parameter to understand how the model generates different tokens (words) within our context. The higher the log probability — the higher the likelihood of a token being the correct choice in that context. You can easily understand how "confident" the model is in its output, and you can also check other potential responses the model considered.
Scoring and ranking model outputs
We can calculate the overall likelihood of a sentence by adding up the probabilities of each word (or token) in that sentence. This is great for scoring and ranking model outputs.
Analyze token probabilities
We can analyze the most likely tokens that a model considers to return at each token position.
But, what can you do with it?
When to use Logprobs
You can leverage OpenAI’s logprobs to optimize your LLM in several ways, especially for tasks like classification, autocomplete, retrieval evaluation and minimizing hallucinations. You could use it in production as well as a moderation tool.
Let’s see some examples and how most of our customers utilize it for developing their AI features:
Evaluating Classification
We sometimes use LLMs to classify content, and the logprobs parameter lets us check how confident the model is in its decision.
Let’s imagine that you operate in a regulated industry and are worried about the impact your LLM chatbot could have if it's not compliant with the law. A common architecture we suggest is a "Guardrail prompt" towards the end of your chatbot.
You set up a good Guardrail prompt using the best model out there, and you get a response that your chatbot is indeed compliant. But when you look closer, the Guardrail prompt should have said that it's not compliant. The evaluator is incorrect!

The guardrail prompt above is only 70% sure in its answer and when there's an asymmetric risk in being wrong, you may want to override the Guardrail prompt's response. Sometimes we recommend our customers take Guardrail prompt responses only when the prompt is 99%+ confident.
Detecting Hallucinations with RAG
In our RAG-based systems, we usually pull context dynamically in our prompts to fix hallucinations and give the model more information of our knowledge. But even with this context, the model can hallucinate if the answer is not provided in these documents.
This is because these models are built to always give an answer, even when they don’t have the right answer .
You can use logprobs as a filter to evaluate retrieval accuracy. By setting a threshold, you ensure that only responses with a logprob close to 100% are considered reliable. If the logprob is lower, it indicates that the answer may not be found in the documents.
Building an Autocomplete Engine
You can use logprobs to improve autocomplete suggestions as a user is typing. By setting a high confidence threshold, you can ensure that only the most likely and accurate suggestions are shown, avoiding less certain or irrelevant options.
This makes the autocomplete experience more reliable and helpful.
Moderation Filters
Logprobs can help us screen responses to avoid rude, offensive, or harmful content. By creating an LLM evaluator, we can classify queries and block those with 100% confidence if they meet negative criteria.
Token Healing
LLMs use tokens to process and generate text, which can sometimes lead to issues with how prompts are handled.
For example, if the model is unsure how to finish a given URL in a prompt, logprobs reveal which tokens it thinks are likely, helping you tweak the prompt to get better results.
Here’s a simple example:
If your prompt is The link is <a href="http: , and the model struggles, logprobs can show which completions it’s considering. If the logprobs suggest the model isn’t sure about finishing the URL, you might adjust the prompt to The link is <a href="http , which could make it more likely to generate a complete URL correctly.
Why is this the case?
When you end a prompt with “ http: ”, the model might not complete it correctly because it sees “ http: ” as a separate token and doesn’t automatically know that “ :// ” should come next. But if you end the prompt with just “ http ”, the model generates URLs as expected because it doesn’t encounter the confusing token split.



