Using the Seed parameter with OpenAI
The seed parameter helps you get consistent LLM outputs, making your results more predictable. To enable it, you can specify an arbitrary number in your request to get (mostly) consistent results each time. Currently this option is available for OpenAI’s Chat Completion models: gpt-4-1106-preview and gpt-3.5-turbo-1106 .
How does the Seed parameter work?
LLM outputs are non-deterministic by nature — meaning that outputs can vary from request to request. But, for many use-cases you’d like to reproduce similar responses for the same requests. And in those cases, you’d use the seed parameter.
This parameter controls the randomness of how the model selects the next tokens during text generation. The token selection happens based on a probability distribution, where each possible next token is assigned a score (called logit) based on its likelihood. Typically, the model introduces some randomness when selecting the next token to create more diverse outputs. Check the image below for a visual explanation of this process.
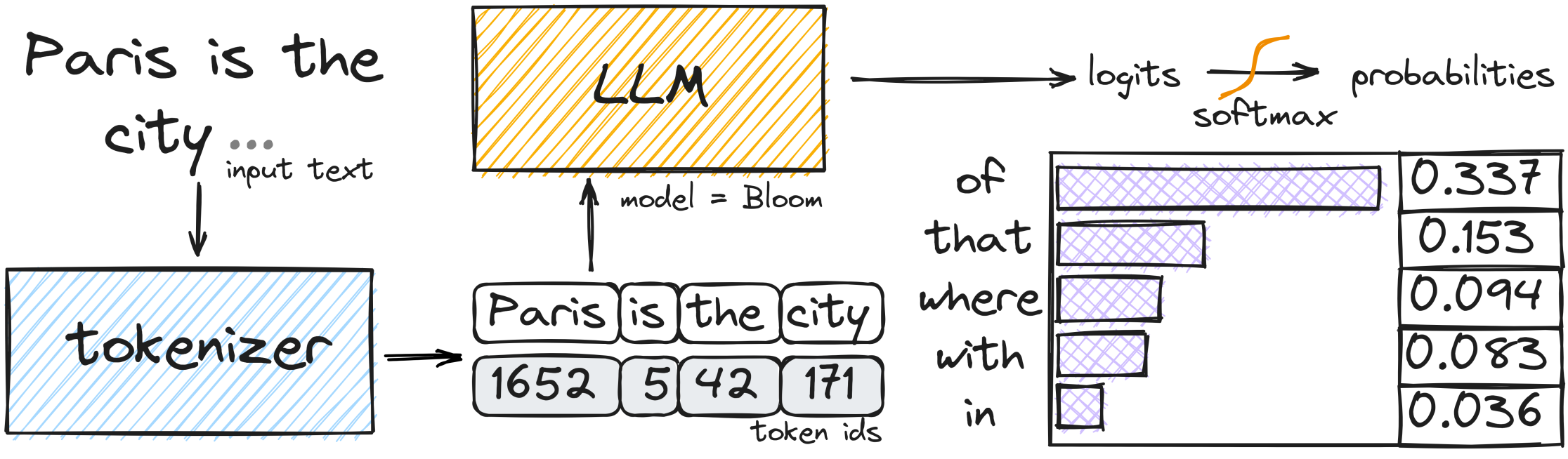
However, when you set the seed parameter , you lock this randomization process , so that the sequence of token selections will follow the same pattern every time you’d use the same prompt.
This allows for more reproducible outputs when you repeat the same request with the same parameters.
When specified, the system will try its best to reproduce a similar output — however, determinism is not guaranteed as some back end changes of the model might still produce some deviations.
To debug, you can check the system_fingerprint parameter, which helps identify whether other factors are influencing the model’s response, even when using the same seed.
How do you set the Seed parameter?
To use the seed parameter to get mostly deterministic responses across different API calls:
Set the seed parameter to any arbitrary number of your choice. It’s completely up to you how you’d define these numbers. Set all other parameters (like prompt, temperature, log bias, streaming etc.) to the same values across these requests. In the response, check the system_fingerprint field. This is an identifier for the current combination of model weights, infrastructure and other parameter changes. If this number changes between your requests, that means that some back-end model updates by OpenAI have impacted the reproducibility of your output even with a fixed seed value.
If seed , request parameters and system_fingerpint match across requests that means that you’ll get mostly identical outputs.
If you're using dynamic values in your prompt, like user input or retrieved context, the seed parameter might not function as expected. Keep this in mind while testing, and check if these changes affect the system_fingerprint value to track any variations in the output.
When to use the Seed parameter?
Maybe the best use-case to use the seed parameter is with prompts that are static in nature. Remember, changing the prompt too much can cause the model to disregard the seed.
That said, we still encourage you to play around with dynamic prompts—like when you’re pulling in user input or retrieving text from a vector database. These kinds of inputs can change how the model responds, even with the seed set, so it’s worth experimenting to see how the output shifts.



